
研究人员发现,测试时训练(TTT)技术可显著提升模型抽象推理能力,效果与人类得分相当
![]() 工具推荐
1731320545更新
工具推荐
1731320545更新
![]() 0
0
尽管大语言模型在处理训练数据中的任务时表现出色,但在面对新颖问题时却常常遇到困难,这些新颖问题包括非平凡的推理、规划或字符串操作,它们与模型预训练数据中的内容截然不同,这种能力也是衡量当前人工智能系统获取新技能的关键指标,是智能的一个重要衡量标准。

为了解决这些问题,研究者们提出了测试时训练(Test-Time Training, TTT)的概念,这是一种在测试阶段对模型进行参数更新的技术,它可以让模型在推理过程中通过动态参数调整来适应特定的测试输入,这种方法与传统的微调不同,因为它在测试时而不是训练时对模型进行调整,通常是基于单个输入或少量上下文标记的例子进行的。在TTT的过程中,首先从测试输入中生成训练数据,然后优化这些参数以最小化损失函数,产生临时更新的参数用于预测,预测完成后,模型恢复到原始参数,以便下一次实例或批次的测试,因此,TTT为每个测试输入训练了一个专门的预测模型。
TTT的设计空间很大,对于语言模型(特别是对于新任务学习)哪些设计选择最有效目前还缺乏深入的理解。为此,研究人员系统地研究了TTT的各种设计选择及其与预训练和采样方案的相互作用。通过在抽象推理语料库(ARC)上的评估,他们发现了几个关键因素,包括初始微调、辅助任务格式和增强以及逐实例训练,这些因素对于TTT在少量样本学习中的有效应用至关重要。
抽象推理语料库(ARC)是一个专门设计来评估语言模型抽象推理能力的基准测试。它包含了一系列视觉推理问题,这些问题以二维网格的形式呈现,每个网格由不同颜色的形状或图案组成,形成了输入和输出对,在ARC中,每个任务都包含了一组训练和测试样本,训练样本用于提供给模型一些示例,以便模型能够学习到完成任务所需的转换规则。ARC的成功标准是模型能够为所有测试输出产生精确匹配,如果不能匹配,则不给予部分分数,ARC数据集的原始训练和验证集分别包含400个任务,每个任务都由训练和测试样本组成,模型需要在没有额外训练样本的情况下,仅通过推理来解决这些新任务。
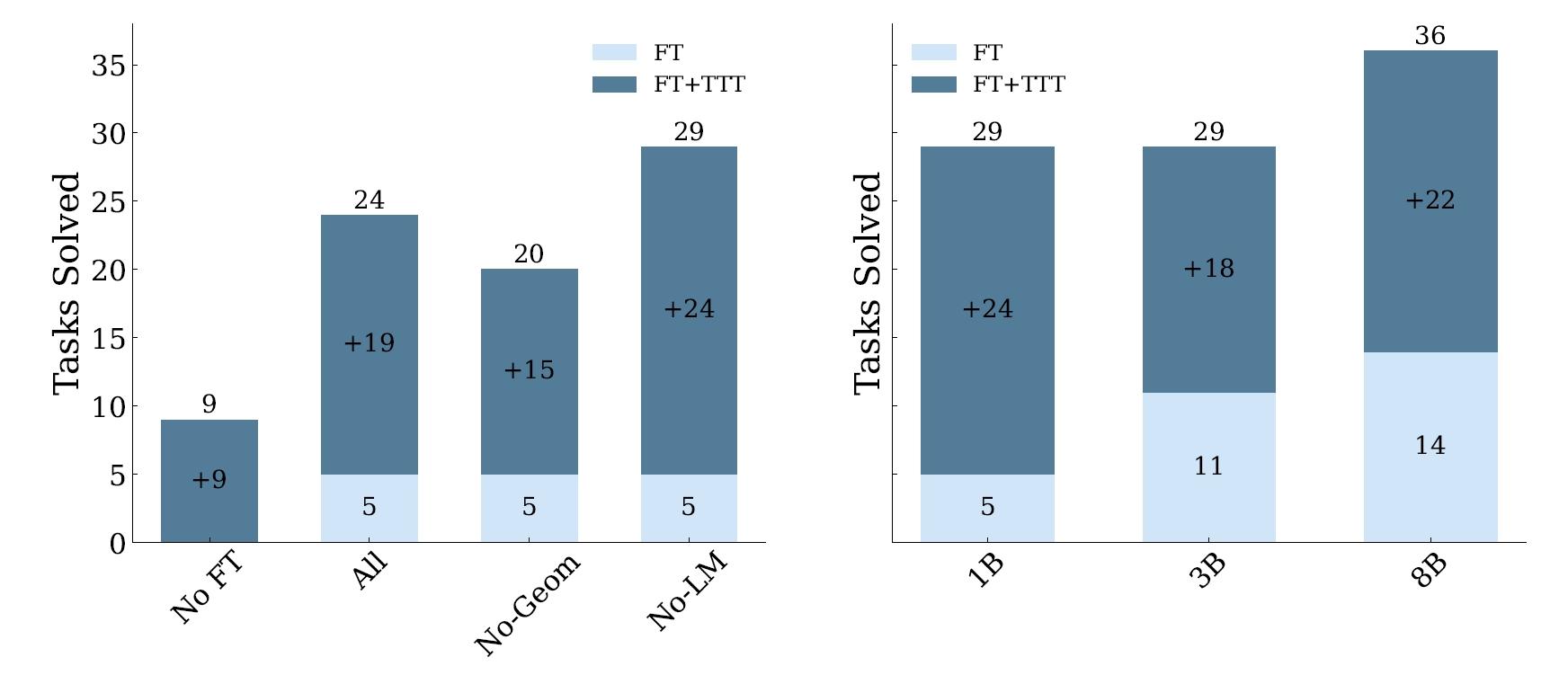
在实验设置部分,研究者们详细描述了他们用于测试测试时训练(TTT)不同组件影响的默认配置。他们使用的是一个8B参数的语言模型,来自Llama-3模型系列,以及1B和3B参数的Llama-3.2模型。为了在测试时高效地适应模型参数,他们采用了低秩适应(Low-Rank Adaptation, LoRA)技术,这是一种参数高效的微调方法,对于每个任务,他们初始化了一组单独的LoRA参数,这些参数在由测试输入生成的数据集上进行训练。LoRA的秩被设置为128,并且适应被应用到多层感知机(MLP)、注意力和输出层。他们使用AdamW优化器进行训练,每个任务进行2个epoch,批量大小为2。在数据和格式化方面,为了高效评估,他们从ARC验证集中随机选取了80个平衡任务,包括20个简单、20个中等、20个困难和20个专家级任务,他们将每个任务的TTT数据集限制在最多250个样本,以提高效率。
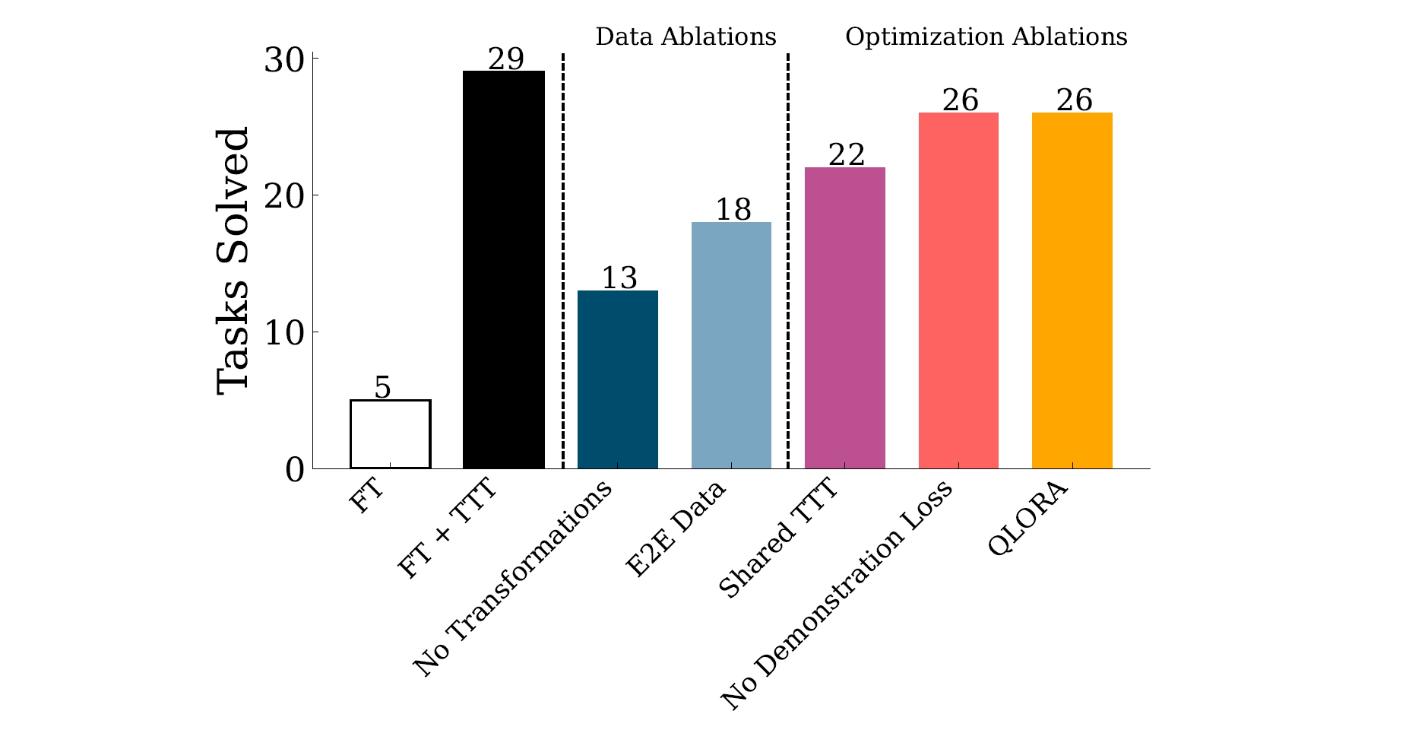
研究人员通过对比实验发现,在类似任务上的初始微调对于TTT的成功至关重要。在将模型应用于测试时训练之前,先在与测试任务相似的任务上进行微调,可以帮助模型更好地适应新的测试任务,这种预训练使得模型能够捕捉到相关任务的特性,为后续的测试时训练打下基础。
另外,辅助任务格式和增强是另一个关键要素。研究者们采用了一种增强的、留一法(leave-one-out)任务生成策略来构建测试时数据集,这种方法通过排除训练样本中的一个样本对来创建合成任务,然后通过对这些任务应用基于规则的变换(如旋转、翻转等)来进一步增强数据集,这样的数据增强不仅增加了数据的多样性,还帮助模型学习到更加鲁棒的特征表示。
最后,逐实例训练也是TTT成功的一个重要组成部分。研究者们不是学习一个适用于所有任务的单一LoRA适配器,而是为每个任务学习一个特定的LoRA适配器,这种方法允许模型为每个测试任务训练更专门的参数,从而提高了模型在特定任务上的性能,通过这种方式,模型能够更精细地调整其参数以适应每个独特的测试实例,从而在测试时实现更准确的预测。
通过这些方法,TTT显著提高了模型在ARC任务上的表现,与基础微调模型相比,准确度提升了高达6倍,特别地,当TTT应用于一个8B参数的语言模型时,在ARC的公共验证集上达到了53%的准确率,相较于纯粹的神经方法,提高了近25%的最佳性能,当与程序合成方法结合后,准确率达到61.9%,与人类平均表现相当。这些结果挑战了符号组件对于解决复杂任务是绝对必要的假设,表明在测试时分配适当的计算资源是解决新颖推理问题的关键因素,而与这些资源是通过符号机制还是神经机制部署的无关。
 豫公网安备41010702003375号
豫公网安备41010702003375号