
月之暗面开源发布音频基础模型Kimi-Audio,推动语音识别、音频理解、音频生成等技术迈向新高度
![]() 前沿资讯
1745663826更新
前沿资讯
1745663826更新
![]() 0
0
一直以来,音频处理技术的重要性与日俱增,像环境感知、言语交流、情感表达以及音乐欣赏都离不开它。不过,受限于人工智能发展水平,传统音频建模只能将各类音频处理任务分开处理,难以满足复杂多变的需求。随着语言模型的飞速发展,音频处理也迎来了新契机,开始朝着通用模型的方向迈进。在此背景下,Kimi团队重磅发布开源音频基础模型Kimi-Audio,推动语音识别、音频理解、音频生成和语音对话等技术迈向了新高度。
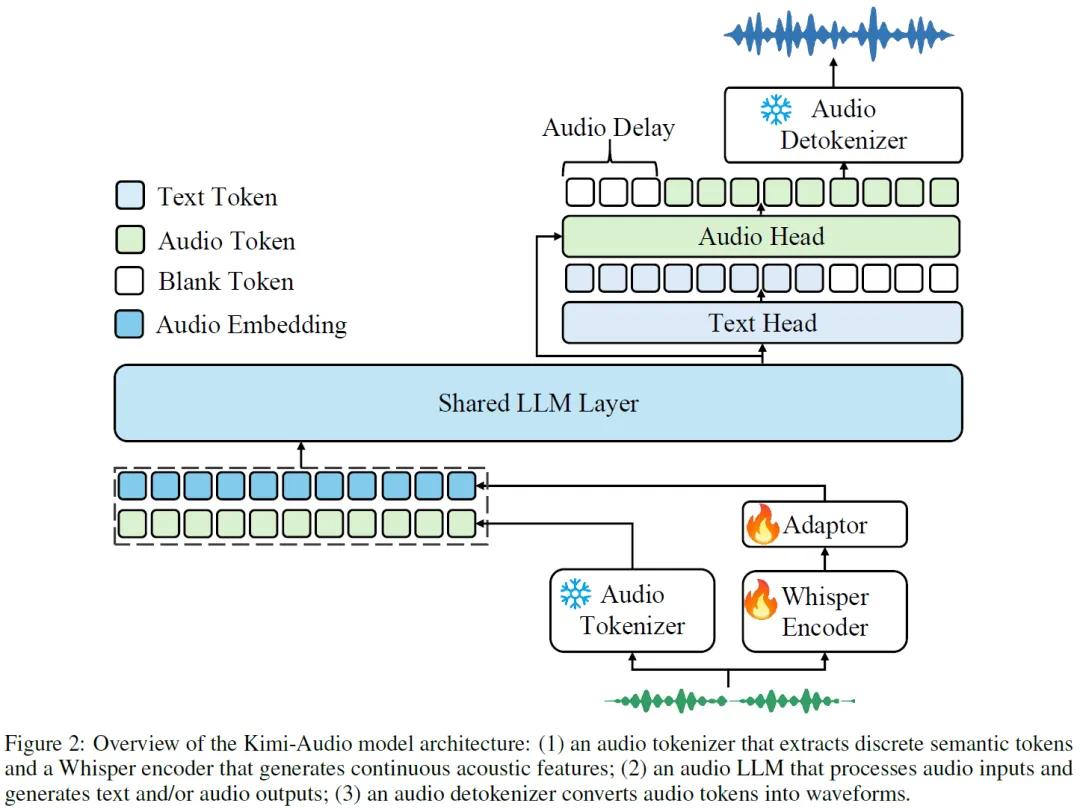
Kimi-Audio架构设计巧妙,它由音频分词器、音频语言模型和音频解分词器三部分组成。音频分词器采用混合策略,会把输入音频转化为离散语义令牌和连续声学向量,以12.5Hz的帧率转换音频,这样能让模型更好地感知音频细节。音频语言模型则是整个模型的核心,通过共享Transformer层和并行头结构,它可以同时生成语义令牌和文本令牌,大大提升了模型的生成能力。音频解分词器则利用流匹配和分块流式解码技术,负责将预测出的离散语义令牌变回连贯的音频波形,有效降低语音生成延迟。这一套架构紧密配合,让Kimi-Audio在处理各种音频语言任务时都能游刃有余。
数据是模型训练的关键。为了让模型拥有强大的能力,Kimi团队收集整理了超过1300万小时的音频数据,这些数据涵盖了有声读物、播客、访谈等多种场景,内容丰富多样。此外,团队还开发了一套数据处理流程,能对原始音频进行增强、分割、转录和过滤等操作,确保数据的质量。
在模型训练阶段,除了使用这些大规模的预训练数据,团队还精心策划了一系列预训练任务,像文本和音频的单模态预训练、音频与文本的映射预训练以及音频文本交织预训练等。通过这些任务,模型能够充分学习音频和文本知识,实现两者之间的有效对齐。
为了让Kimi-Audio在实际应用中表现更出色,团队还进行了监督微调。他们收集了大量开源数据集,涵盖自动语音识别、音频问答、自动音频字幕等多个任务领域,同时还加入了内部数据进行训练。经过多轮优化,Kimi-Audio在多个音频基准测试中都取得了领先成绩。
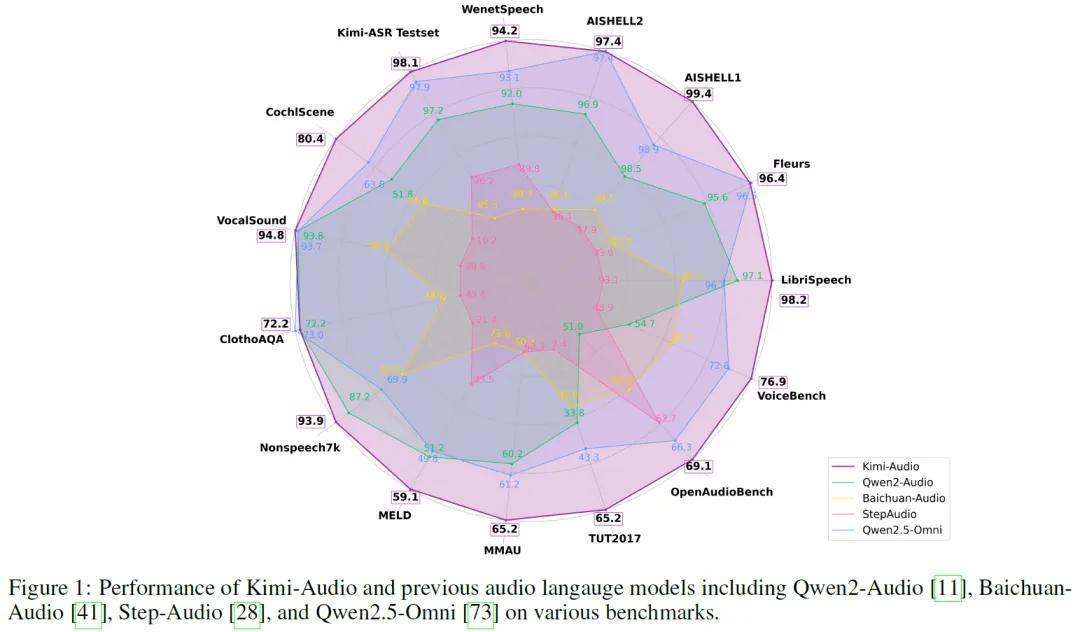
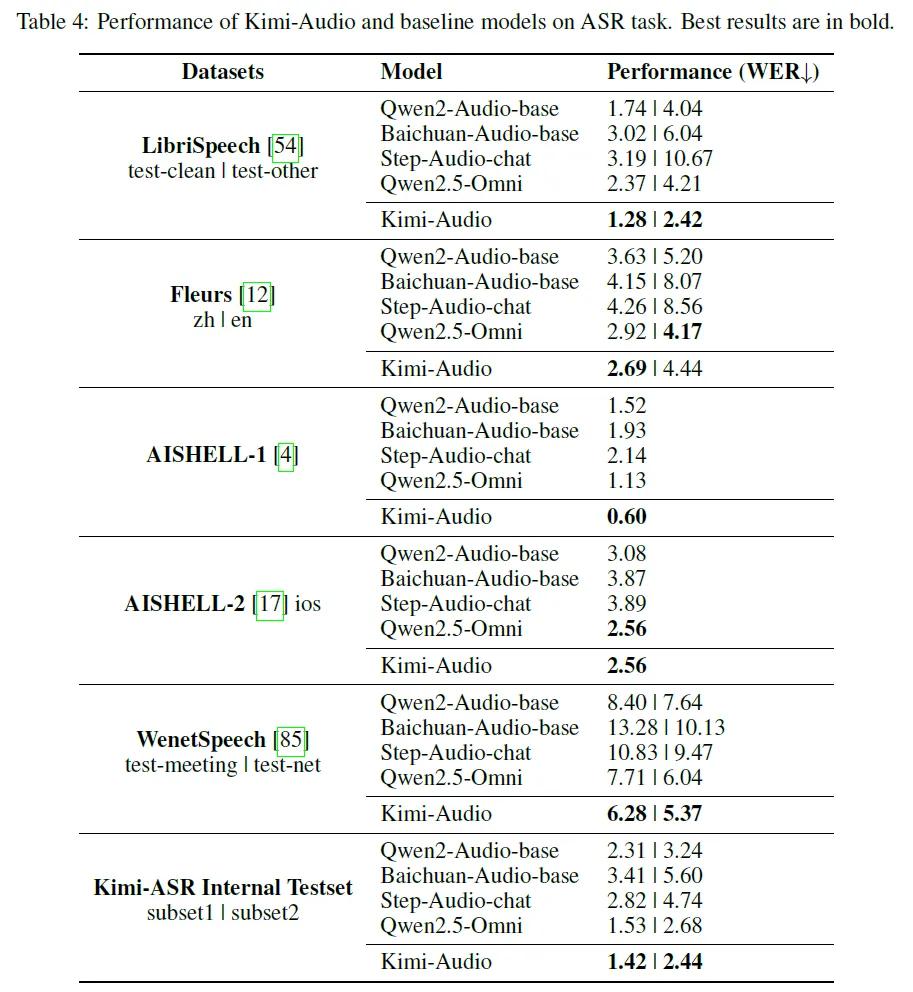
在自动语音识别任务LibriSpeech、AISHELL-1等多个数据集上,超越了同类模型,错误率显著降低。
音频理解能力也十分突出,在MMAU、MELD等基准测试中,对音乐、语音情感等的理解能力领先。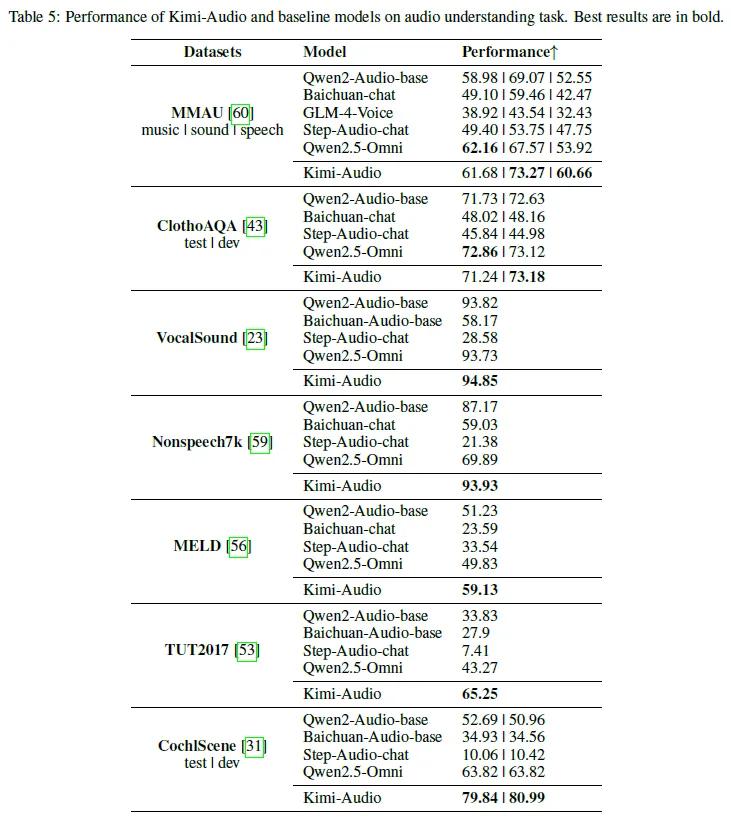
音频到文本聊天任务里,在OpenAudioBench和VoiceBench基准测试中成绩优异,展现出强大的对话和推理能力。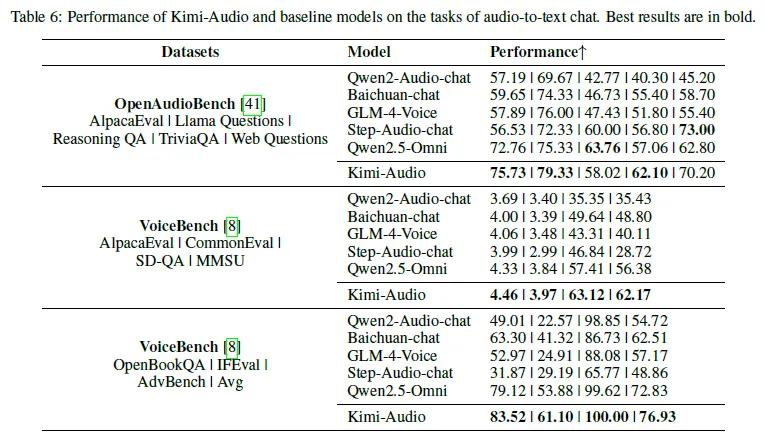
端到端语音对话方面,主观评价结果显示,其在情感控制、速度控制等维度表现出色,整体性能与GPT-4o相当,超越多数对比模型。
为方便模型评估和对比,Kimi团队开发了开源评估工具包,这个工具包可以解决评估指标不一致、模型配置多样以及生成评估缺失等问题,进一步推动音频基础模型评估标准化,助力研究人员更公平地比较不同模型性能。
Kimi团队已将Kimi-Audio的代码、模型检查点以及评估工具包全部开源,并希望借此推动整个音频处理领域的发展,让更多研究人员和开发者能够基于此进行创新。Kimi团队表示,未来,他们将致力于引入描述性文本提升模型对复杂声学环境的理解,开发更优的音频表示方法,探索不依赖ASR和TTS的训练方式,推动音频处理技术向更智能、通用的方向发展。
参考资料:https://huggingface.co/moonshotai/Kimi-Audio-7B-Instruct
 豫公网安备41010702003375号
豫公网安备41010702003375号