
Meta研究揭示稀疏注意力机制在Transformer模型中的权衡关系
![]() 前沿资讯
1745837501更新
前沿资讯
1745837501更新
![]() 0
0
随着语言模型的发展,处理长序列的能力变得愈发重要。然而,Transformer架构模型中的自注意力机制存在计算瓶颈,在推理时,预填充阶段的计算复杂度与序列长度呈二次方增长,解码阶段则受限于关键值(KV)缓存的内存访问。稀疏注意力机制旨在通过近似密集注意力输出,减少计算开销,但此前其实际效果缺乏大规模评估。

为此,Meta、爱丁堡大学、Cohere等机构研究人员深入探讨了Transformer模型中稀疏注意力机制的可行性、效率与准确性的权衡关系,并建立了相应的缩放定律。
在此次研究中,研究人员对免训练的稀疏注意力方法进行了大规模实证分析,涵盖参数在70亿到720亿之间的模型、长度在1.6万到12.8万令牌之间的序列,以及0%到95%的稀疏度。为了便于分析,他们将现有方法归纳为四个关键维度:稀疏化单元、重要性估计、预算分配和KV缓存管理,并选取了六种具有代表性的模式进行严格评估。同时,研究人员精心策划了9个长上下文任务的基准测试套件,这些任务涵盖了不同的任务类型、序列自然度和精确控制的序列长度。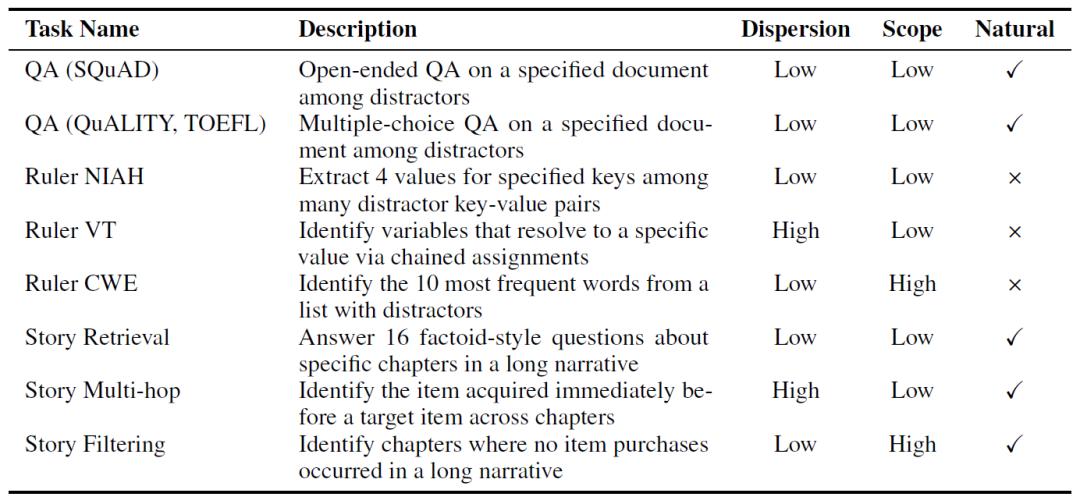
研究发现,在等计算量(isoFLOPS)分析下,对于非常长的序列,更大且高度稀疏的模型比更小的密集模型更具优势。在解码阶段,能够实现的稀疏度通常比预填充阶段更高,并且与模型大小相关。不过,即使是中等稀疏度,在大多数配置下也可能导致至少一个任务的性能显著下降,表明稀疏注意力并非万能解决方案,在应用时需要仔细评估权衡。
在不同任务和阶段,没有一种稀疏注意力方法能够始终表现最佳。例如,在检索任务中,稀疏注意力方法的性能下降程度与查询数量直接相关。在高范围或高分散度的任务中,块级方法(如Block-Sparse、Quest)通常优于令牌级全局选择方法。此外,非均匀预算分配策略在不同推理阶段的效果也有所不同,预填充阶段的自适应阈值选择可能不如简单的均匀分配,而解码阶段的自适应分配则能带来更好的性能提升。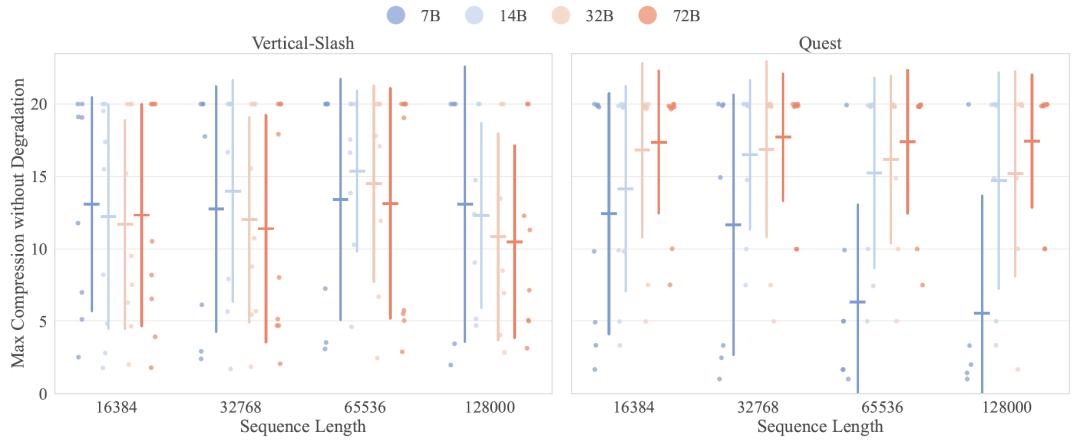
研究人员还建立了稀疏注意力的缩放定律,通过对数线性模型能够可靠地预测模型在不同配置下的性能,表明研究结果在测试范围之外也具有一定的通用性。尽管如此,在某些任务和设置下,预测的相关性仍然较弱,如Story Multi-hop任务在压缩比和序列长度外推时的准确性预测。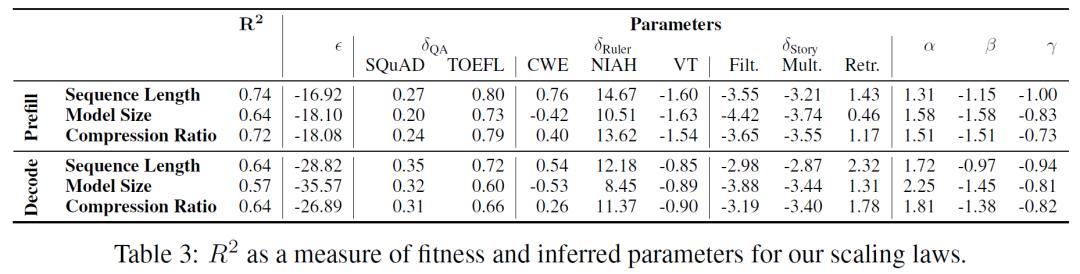
该研究全面比较了稀疏注意力方法,为其在下一代模型架构中的应用提供了重要参考。研究团队表示,未来的研究应重点将关注动态稀疏机制,使其能够根据输入和任务需求进行自适应调整,同时保证性能。这将有助于推动更高效、更灵活的人工智能模型的发展,有望在自然语言处理等领域取得更大的突破。
参考资料:https://arxiv.org/abs/2504.17768
 豫公网安备41010702003375号
豫公网安备41010702003375号