
阿里巴巴开源发布Qwen3系列模型,性能超越OpenAI o1和DeepSeek R1
![]() 前沿资讯
1745923885更新
前沿资讯
1745923885更新
![]() 0
0
阿里巴巴旗下Qwen团队正式发布了新一代开源大型多模态语言模型系列:通义千问3.0(Qwen3),该系列模型在开源模型中处于领先水平,性能接近OpenAI和谷歌等公司的专有模型。
Qwen3系列包含两个“专家混合”(Mixture-of-Experts,MoE)模型和六个密集(Dense)模型,共计八款新模型。旗舰型号Qwen3-235B-A22B拥有2350亿参数,激活参数数量为220亿,采用混合专家(MoE)架构,在处理不同问题时,能够智能调用相应的模型部分,如同召集不同的“专家”,而非调动整个模型,大大提高了效率。
在性能表现上,Qwen3可与Deepseek-R1、Gemini-2.5-Pro等顶级模型相媲美。在AI数学竞赛AIME2024和AIME2025中,Qwen3成绩介于Gemini-2.5-Pro和OpenAI-o3-mini之间;在LiveCodeBench和CodeForces测试中,甚至超越了Gemini-2.5-Pro和o3-mini。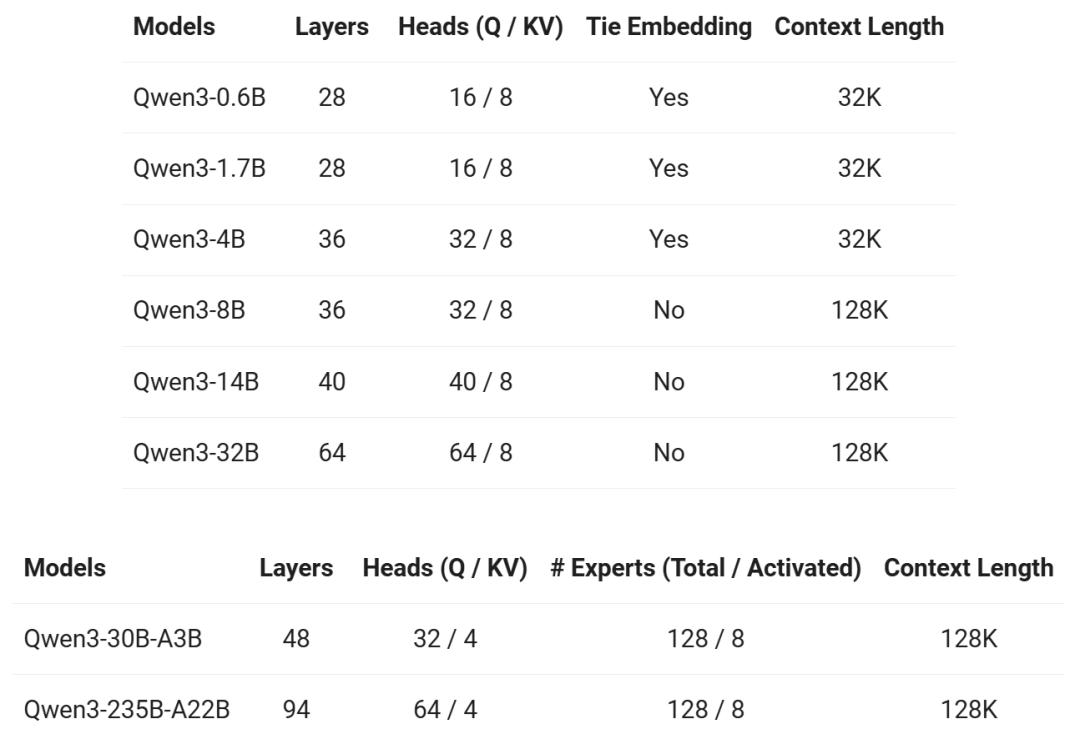
Qwen3具有多项创新特性,支持思考和非思考两种模式,也称为“混合推理”能力。在思考模式下,模型如同推理专家,在给出最终答案前会深入思考,非思考模式则能快速响应。两种模式的结合,让模型在面对难题时能合理分配计算资源,根据需求灵活调整思考深度,实现稳定高效的思考预算控制。在AIME2024和AIME2025等测试中,随着思考模式下token数量增加,模型的表现显著提升。
在数据方面,Qwen3相比Qwen2.5有了巨大飞跃。Qwen2.5是在18万亿个token上进行预训练的,而Quin3使用了约36万亿个token的数据,token数量几乎是其两倍。有趣的是,Qwen团队使用Qwen2.5-vl来提取文本,然后用Qwen2.5来提高提取内容的质量。为了增加数学和代码数据的数量,他们还使用Qwen2.5-math和Qwen2.5-coder生成合成数据,包括教科书内容、问答对和代码片段。每一代模型都可以用来帮助构建下一代AI模型,使它们在迭代过程中不断优化。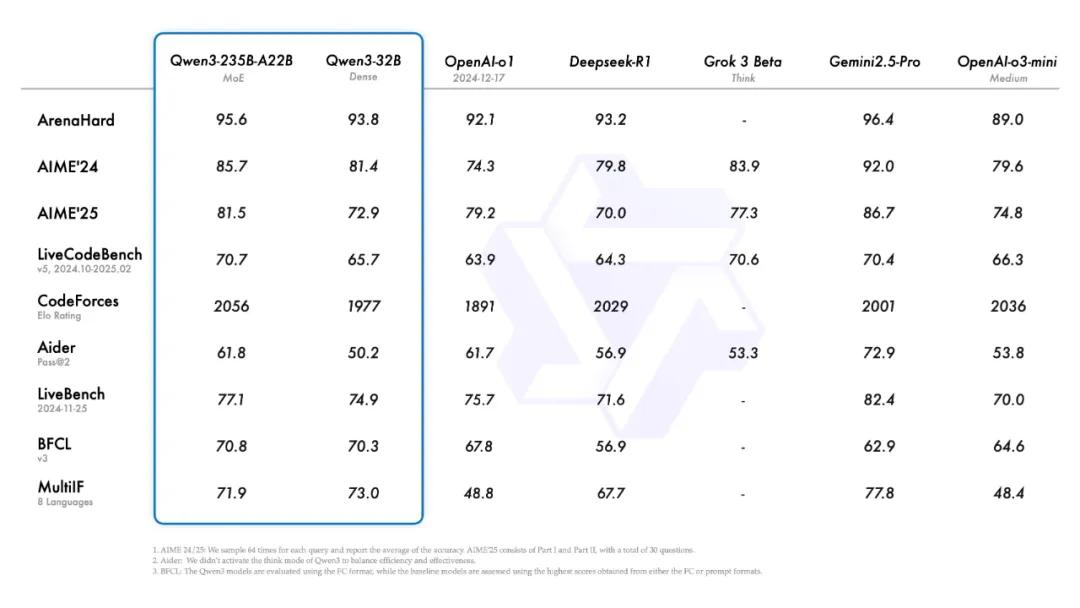
模型的训练过程分多个阶段进行。预训练阶段包括三个步骤:第一阶段在超30万亿token上训练,赋予模型基础语言技能和常识。第二阶段增加知识密集型数据比例,进一步训练5万亿token。第三阶段使用高质量长上下文数据,将上下文长度扩展到32万亿token。后训练阶段则通过长链思维冷启动、推理强化学习、思考模式融合和通用强化学习等步骤,逐步提升模型的推理、响应和指令执行能力。
此外,Qwen团队还运用了蒸馏技术训练轻量级模型。这种技术以大模型为“教师”,小模型为“学生”,让小模型在保留部分能力的同时,具备运行速度快的优势,部分小模型甚至可在边缘设备和手机上运行。
Qwen3基于Apache 2.0许可证发布,允许商业使用、修改和分发,极大地促进了开源生态系统的发展。该团队表示,Qwen3不仅是对前代产品的升级,更是向通用人工智能(AGI)和超人工智能(ASI)迈出的重要一步,未来将继续扩大数据规模、模型参数、上下文长度和多模态能力,并强化基于环境反馈的强化学习。
参考资料:https://qwenlm.github.io/zh/blog/qwen3/
https://www.youtube.com/watch?v=gk0PrTcZfGA
 豫公网安备41010702003375号
豫公网安备41010702003375号