
通义百聆“语音双子星”同步开源:3秒“复刻声音”,嘈杂环境也能“听清”
![]() 前沿资讯
1765792043更新
前沿资讯
1765792043更新
![]() 0
0
导读:通义百聆一次性升级了语音“说”和“听”两大能力,Fun-CosyVoice3 与 Fun-ASR 同步增强并开源;3秒音频即可跨语种、跨方言复刻音色,嘈杂环境下语音识别准确率提升至93%,多语言、方言与企业定制能力全面落地。
通义百聆今天放出了一套“组合拳”,把“会说话”和“听得懂”两件事同时做到了位。语音合成与语音识别两大核心能力同步升级,并直接开源,对开发者和实际应用场景都释放出更明确的信号。
3秒录音,声音还能“换语言、换情绪”
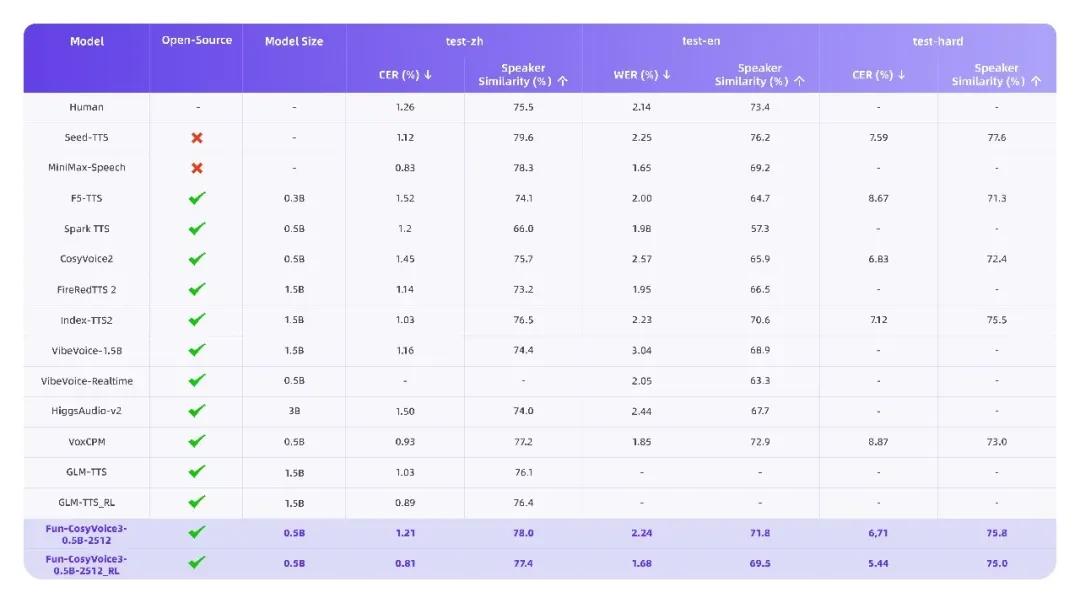
先来看“说话”的部分。升级后的 Fun-CosyVoice3,只需要一段3秒左右的参考音频,就能复刻音色,并在不同语言、方言甚至情绪之间自由切换。普通话、粤语、英语、日语可以来回切换,开心、愤怒等情绪也能直接控制,音色一致性依然保持得很稳。
最直观的升级变化有三个:
- 首包延迟降低50% ,支持双向流式合成,输入几乎同时就能“开口说话”,更适合语音助手、直播配音等实时场景;
- 中英混说准确率大幅提升,专业术语、大小写混排、语码切换不再“卡壳”;
- 跨语种音色复刻能力更稳定,用普通话录音,也能生成粤语、日语或英语,声音辨识度依然很高。
同时,官方还同步开源了 Fun-CosyVoice3-0.5B 版本。这个版本主打轻量化和可落地,支持 zero-shot 音色克隆、本地部署和二次开发,更适合希望把语音能力真正“装进系统”的团队。
嘈杂环境下,也能把话“听清楚”
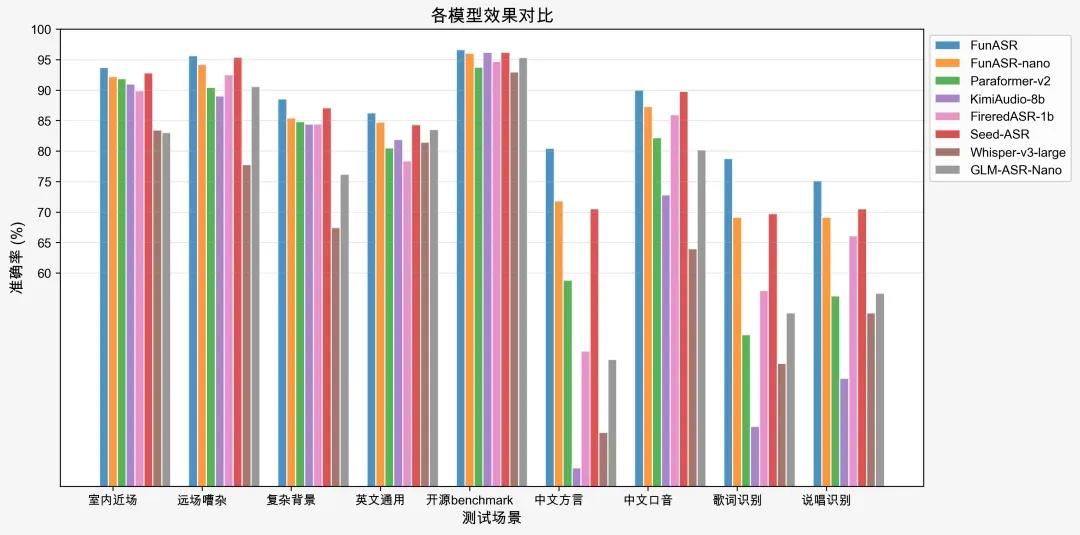
如果说 CosyVoice3 解决的是“怎么说”,那 Fun-ASR 解决的就是“怎么听”。
这次 Fun-ASR 的升级,重点放在真实复杂环境里。在会议室、地铁、车载等高噪声场景下,识别准确率可达93% ,绕口令、背景音乐、说唱歌词这些过去最容易翻车的内容,也都被重点优化。
更关键的是覆盖面:
- 支持31种语言自由混说,无需提前指定语种;
- 中文覆盖7大方言、26种地方口音,从东北话到四川话,从港台腔到河南口音,都能稳定识别;
- 流式识别首字时间降低到 160ms,实时性进一步增强。
针对企业级场景,Fun-ASR 还引入了 RAG(检索增强生成)机制,把可定制热词数量提升到10000条,同时不牺牲通用识别准确率,对金融、医疗、教育等行业更友好。
除了主模型,Fun-ASR-Nano(0.8B)也正式开源。在参数量大幅压缩的情况下,推理成本更低,依然支持本地部署和定制微调,给资源受限的场景多了一个现实选择。
GitHub链接:
https://github.com/FunAudioLLM/CosyVoice https://github.com/FunAudioLLM/Fun-ASR
国内体验demo:
https://www.modelscope.cn/studios/FunAudioLLM/Fun-CosyVoice3-0.5B
https://modelscope.cn/studios/FunAudioLLM/Fun-ASR-Nano/
国内模型仓库:https://modelscope.cn/models/FunAudioLLM/Fun-CosyVoice3-0.5B-2512
参考资料:https://mp.weixin.qq.com/s/0c_cK2zwxkuR1lx-n8cNxA
 豫公网安备41010702003375号
豫公网安备41010702003375号