
MiniMax-01系列模型开源发布,456B参数,400M上下文窗口
![]() 工具推荐
1736937071更新
工具推荐
1736937071更新
![]() 0
0
近年来,大语言模型和视觉语言模型发展迅猛,在知识问答、复杂推理、数学、编码以及视觉语言理解等诸多任务中表现出色。然而,当前多数模型的上下文窗口长度在32K到256K tokens之间,难以满足实际需求。比如在将专业书籍作为上下文、辅助整个编程项目,或是通过多示例发挥上下文学习的最大潜力等场景下,这样的长度常常捉襟见肘。过去两年,虽然借助更强大的GPU和更优的I/O感知softmax注意力实现,上下文窗口有所扩展,但由于Transformer架构固有的二次计算复杂性,进一步延长窗口困难重重。为解决这一难题,研究者们提出了诸如稀疏注意力、线性注意力、长卷积、状态空间模型和线性RNN等降低注意力机制计算复杂度的方法,可惜这些创新在商业规模模型中的应用有限。
在这样的背景下,MiniMax-01系列模型应运而生,它包含了MiniMax-Text-01和MiniMax-VL-01,在性能上可与顶尖模型相媲美,同时在处理长上下文方面,能够应对长达400万tokens的上下文窗口。
一、模型架构:创新融合铸就强大性能
为了让MiniMax-01系列模型在有限资源内发挥最佳性能并更好地处理长序列,研发团队采用了混合专家(MoE)方法,并尽可能地使用线性注意力来替代标准Transformer中的传统softmax注意力。
MoE就像是模型中的“智囊团”,它由多个前馈网络专家组成。对于输入的每个token,模型会决定将其路由到一个或多个专家进行处理。这种设计使得模型在相同的计算资源下,能够比传统的密集模型处理更多的信息,从而显著提升了模型的性能。为了解决训练过程中可能出现的路由崩溃和负载不平衡问题,研发团队提出了辅助损失和全局路由策略。辅助损失就像是一个“平衡器”,通过计算每个专家被分配到的token比例和平均路由概率,来调整模型的训练过程,确保各个专家都能得到充分的利用。全局路由策略则像是一个“智能调度员”,它会在不同的专家并行(EP)组之间同步等待处理的token数量,从而有效减少整体的token丢弃率,保证训练的稳定性。
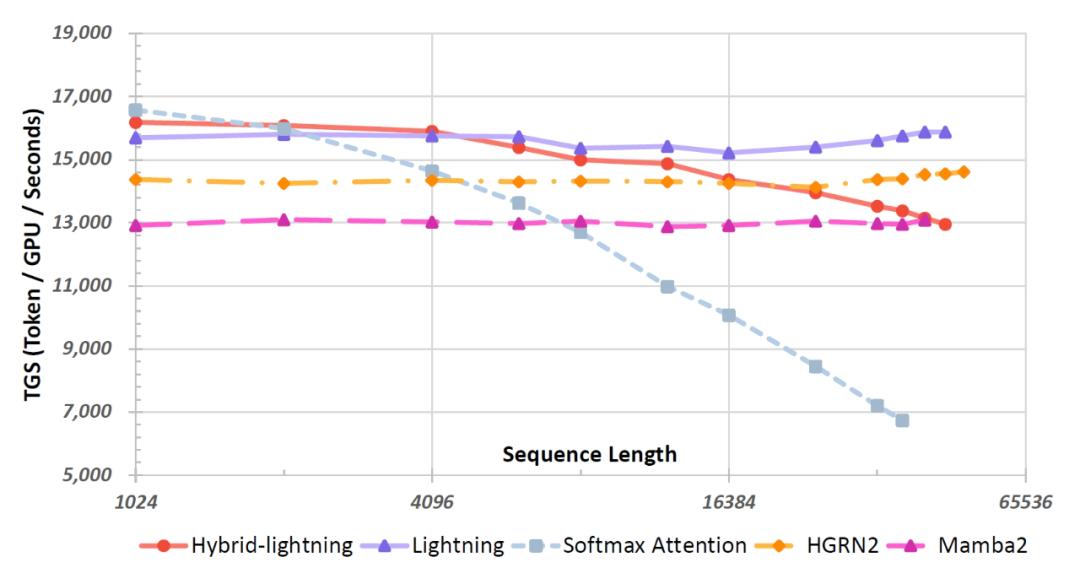
线性注意力是MiniMax-01系列模型的另一个关键创新点。传统的softmax注意力在处理长序列时,计算复杂度会随着序列长度的增加而呈二次方增长,这就像是一个“沉重的负担”,限制了模型处理长上下文的能力。而线性注意力则巧妙地利用“right product kernel trick”,将计算复杂度转化为线性,大大减轻了模型的计算压力。Lightning Attention作为线性注意力的一种优化实现,更是通过独特的平铺技术,有效地规避了因果语言建模中缓慢的cumsum操作,进一步提升了模型的效率。
在实际应用中,研发团队发现纯线性注意力模型虽然计算效率高,但在检索能力方面存在不足。为了解决这个问题,他们提出了一种混合架构,将Lightning Attention和softmax注意力相结合。这种混合架构充分发挥了它们各自的优势,使得模型在检索和外推任务上的表现超越了单纯依赖softmax注意力的模型。
二、计算优化:突破瓶颈提升效率
为了让MiniMax-01系列模型能够高效运行,研发团队在计算优化方面下足了功夫。
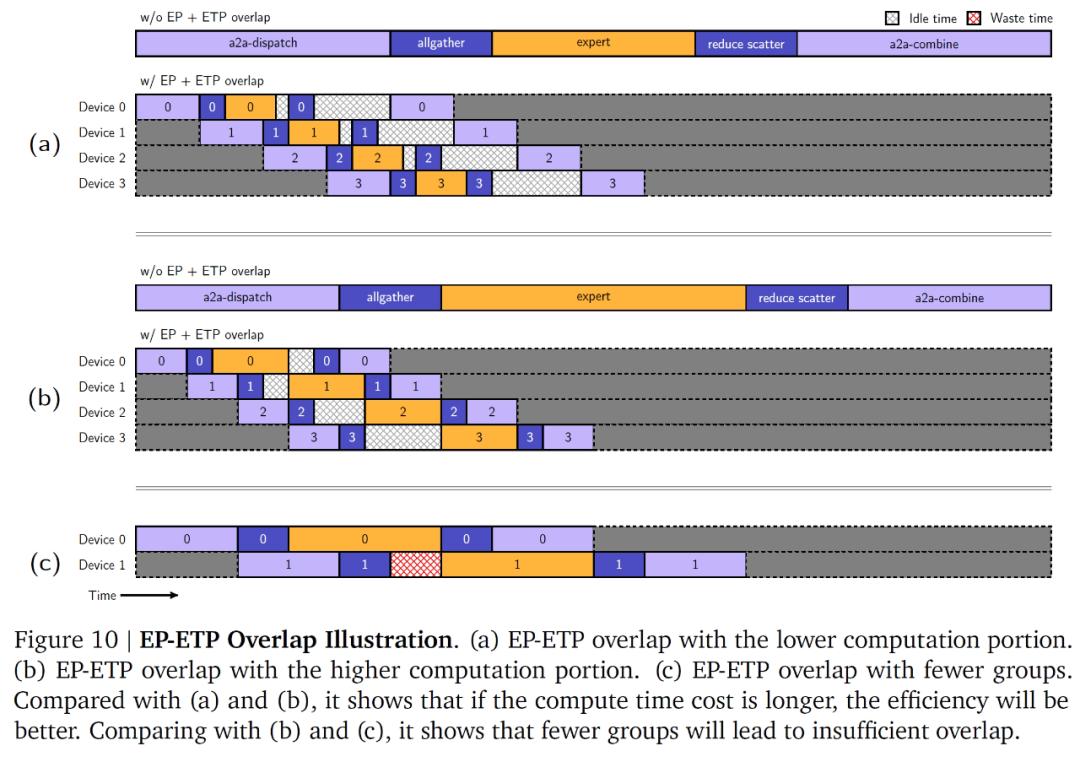
在MoE架构的训练过程中,全对全(a2a)通信会带来巨大的开销,这就像是模型训练过程中的“堵车”现象,严重影响了训练效率。为了解决这个问题,研发团队提出了基于令牌分组的重叠方案。这个方案就像是给车辆规划了合理的路线,让a2a通信在专家并行(EP)通信组内进行,并与不同专家组的令牌处理重叠起来。同时,他们还引入了ETP(专家张量并行)和EDP(专家数据并行)两个新的Process Group,通过设计EP-ETP重叠策略,使得MoE组件能够更加灵活地配置,从而减少了MoE组件的纯通信开销,让模型的训练效率得到了大幅提升。
在长上下文训练方面,由于真实的训练样本长度难以标准化,传统的填充方法会导致大量的计算浪费。为了解决这个问题,研发团队采用了“数据打包”技术,将不同长度的样本首尾相连,减少了计算浪费。此外,他们还提出了Varlen Ring Attention和改进的LASP+算法。Varlen Ring Attention就像是一个“智能裁剪师”,它能够直接对打包后的数据应用环形注意力算法,避免了传统方法中因样本长度限制而导致的过多填充和计算浪费。改进的LASP+算法则像是一个“高效协调员”,通过优化计算和通信流程,消除了计算过程中的依赖关系,将串行计算转化为并行计算,大大提高了系统的整体效率。
在推理方面,研发团队针对Lightning Attention进行了一系列优化。批处理内核融合技术就像是将多个小工具整合为一个大工具,通过融合多个内存受限的内核,减少了中间结果的存储和内存访问操作,从而提高了内存访问效率。分离预填充和解码执行策略则像是给不同长度的任务分配了专门的“生产线”,将长度为1的token处理与长度大于1的token处理分开,通过两个不同的内核和CUDA流并行调度,提高了计算效率。多级填充和Strided Batched Matmul扩展等策略也进一步提升了模型的推理效率,使得模型在处理不同长度的输入时能够更加灵活高效。
三、训练策略:精心打磨释放潜力
MiniMax-Text-01的训练过程从数据和训练策略等多个方面进行了精心打磨。
在数据方面,研发团队构建了一个丰富多样且高质量的预训练语料库。语料库涵盖了学术文献、书籍、网页内容和编程代码等多种来源。在数据质量提升上,通过规则清洗和去重,同时利用前一代模型作为奖励标记器,从多个维度评估文档质量,最终聚焦于知识深度、实际帮助和类别分布这三个关键维度。在数据格式优化方面,对于不同类型的数据,采用了合适的处理方式,既保留了数据的自然特性,又满足了模型训练的需求。在数据混合策略上,通过大量实验,确定了一种平衡的采样策略,既保证了高质量内容的优势,又兼顾了数据的多样性。
在训练策略上,研发团队采用了Xavier初始化方法,同时,他们精心设计了学习率和批大小的调整策略。在训练初期,学习率会通过线性预热逐渐上升到一个峰值,然后保持一段时间,在训练后期再逐渐降低。批大小则会根据训练数据的规模和模型的训练情况逐步增加,以提高训练效率。为了让模型能够处理更长的上下文,研发团队采用了三阶段训练过程,逐步扩展模型的上下文长度。在这个过程中,他们还通过实验不断调整RoPE的基频等超参数,以确保模型在长上下文处理能力提升的同时,不会影响在短上下文任务上的性能。
四、性能表现:实力彰显卓越品质
经过精心的设计和训练,MiniMax-01系列模型在多个基准测试中展现出了卓越的性能。
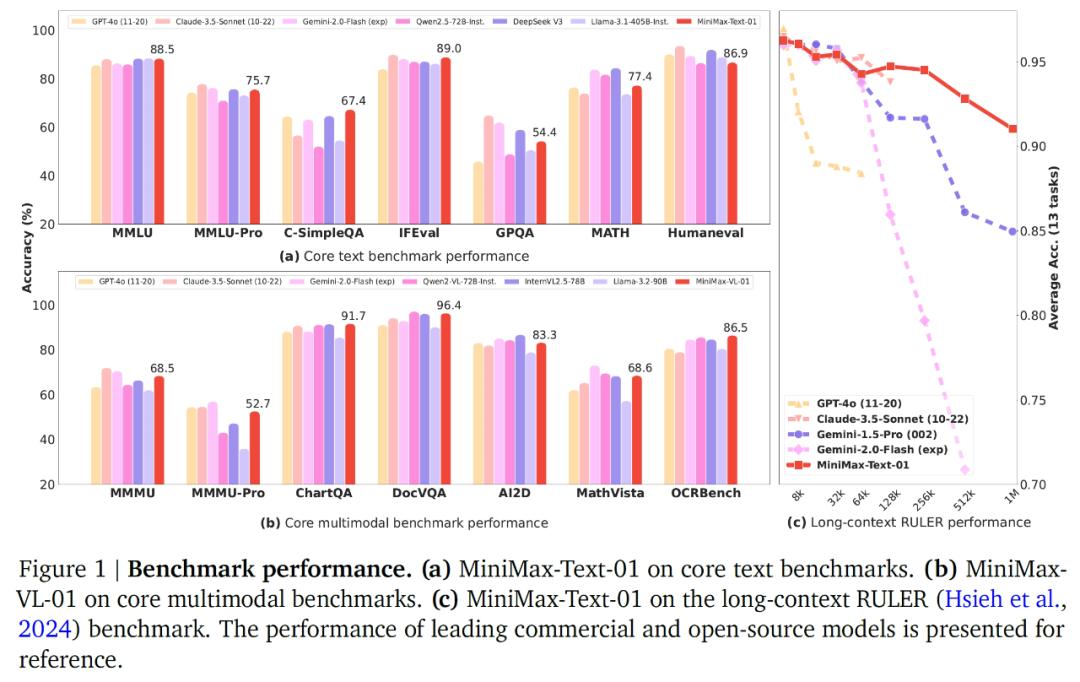
MiniMax-Text-01在核心学术基准测试中表现出色,在多个维度上都取得了优异的成绩。在C-SimpleQA测试中,它凭借更广泛的知识边界超越了所有模型,展现了强大的知识储备和理解能力。在MMLU、IFEval和Arena-Hard等测试中,它也取得了前三名的好成绩,证明了其在应用知识满足用户查询和符合人类偏好方面的出色能力。在数学问题解决方面,它的MATH pass@1率甚至超过了GPT-4o、Claude-3.5-Sonnet和Llama-3.1-405B等知名模型。
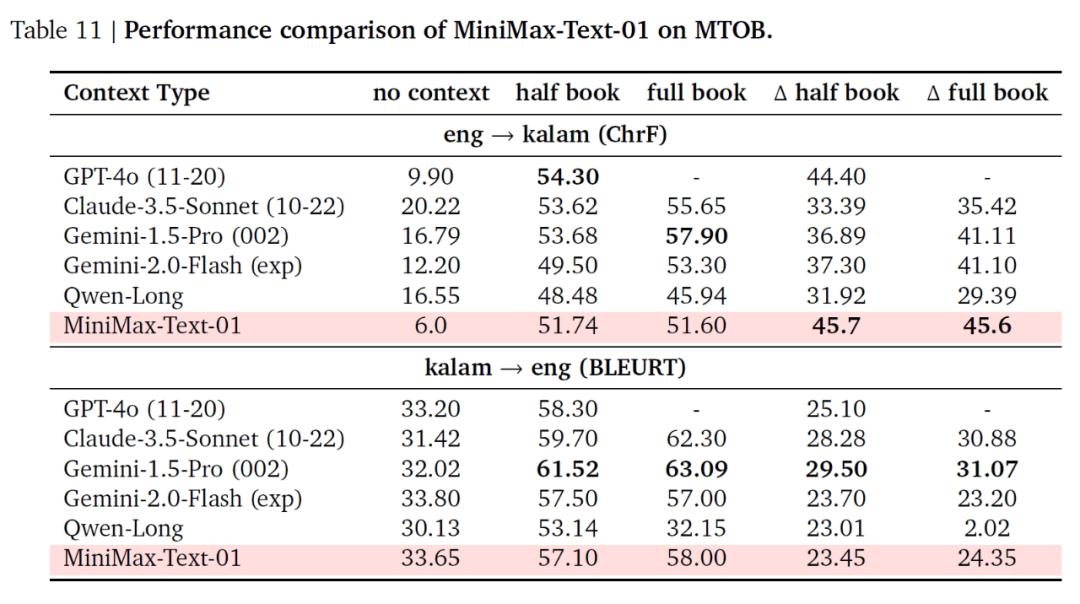
在长上下文基准测试中,MiniMax-Text-01更是展现出了独特的优势。在长上下文检索任务中,无论是在英语还是中文评估中,它都能在广泛的序列长度范围内表现出色,与其他领先模型相比,在大输入长度下的性能下降更少。在长上下文理解任务中,它在Ruler和LongBench-V2等数据集上的表现优异,在处理复杂推理任务时,能够在超长上下文场景中保持领先地位。在长上下文学习任务中,通过MTOB数据集的测试,它在从有限的上下文信息中学习新知识的能力方面也表现出色。
MiniMax-VL-01作为视觉语言模型,在多个视觉语言基准测试中也展现出了竞争力。在标准的视觉语言下游任务中,它的性能与GPT-4o相当,在视觉问答等任务中表现出色。在长上下文理解和检索任务中,虽然与GPT-4o-11-20相比还有一定差距,但在整体表现上仍优于大多数同类模型。在内部用户体验基准测试中,它与GPT-4o-11-20的性能差距很小,展现了良好的实际应用能力。
五、不足之处
尽管MiniMax-01系列模型展现出了强大的性能,但研究团队也表示这些模型仍存在一些局限性,需要在未来的研究中加以解决。
在长上下文评估方面,目前用于评估长上下文检索任务的数据集大多基于人工设计或简化的场景,对于实际应用中的长文本推理能力评估,如文档分析等,还存在一定的局限性。研究团队计划在未来的工作中,针对更接近现实场景的设置来提升长上下文检索的能力,并拓展长上下文推理的评估范围,以涵盖更多类型的任务。在模型架构方面,当前的模型设计中仍有一部分(约占1/8)采用了传统的softmax注意力机制。研究团队正在探索更高效的架构设计,目标是完全摒弃softmax注意力,努力使模型实现理论上无限长的上下文窗口,同时减少计算开销。在复杂编程任务的处理上,模型的表现还有提升空间,因为预训练阶段使用的编程数据集规模相对有限。为了克服这一局限性,研究团队正在持续优化训练数据的选择,并改进持续训练的流程,以期在下一代模型中实现更好的性能表现。
为了推动该领域的合作与进步,模型代码已公开在GitHub平台,此外,为了便于广泛使用和评估,他们还提供了具备在线搜索功能的聊天机器人和在线API。MiniMax团队承诺将继续保持该系列模型的开源状态,并在模型得到进一步发展时,及时发布更新。
 豫公网安备41010702003375号
豫公网安备41010702003375号