
国内首个“Deep Research”满血版上线,阶跃星辰这次要硬刚Gemini
![]() 工具推荐
1769337247更新
工具推荐
1769337247更新
![]() 1
1
导读:搜索工具已经很多,但真正能把“研究”这件事做完的并不多。阶跃星辰推出 Step-DeepResearch,并不是再造一个更快的搜索器,而是试图把专家在真实研究中的思考与行动闭环,压缩进一个可复用的智能代理里。
在过去一年里,“Deep Research”几乎成了所有大模型团队都会提到的方向,但搜索 ≠ 研究,这一点在真实工作中越来越明显。
Step 给出的判断很直接:大多数产品解决的是“找到信息”,但研究真正消耗时间的,是筛选、交叉验证、推理、计算和表达。
与常见的多 Agent 协作框架不同,Step DeepResearch 采用的是单 Agent 的端到端研究架构。 它的核心并不是“角色分工”,而是一个能够不断 规划—执行—校验—修正 的认知闭环。
官方将其能力描述为从 “下一 token 预测”,转向 “下一行动决策”: 模型不只是继续写,而是判断下一步该不该搜、该不该算、该不该验证来源。
在执行过程中,它可以:
- 搜索并筛选上百条网页与文献信息
- 调用代码执行统计、建模与计算
- 对多来源结论进行交叉验证
- 用表格和可视化方式交付结果
最终输出的是一份溯源清晰、结构完整、可复核的研究报告,而不是一段“看起来很懂”的总结。
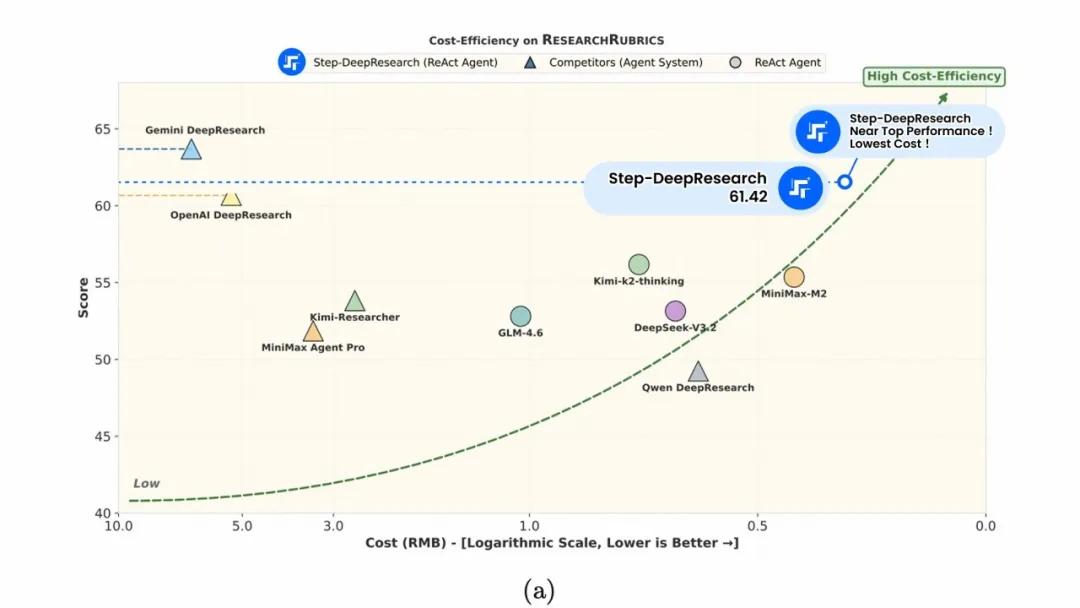
在数据侧,Step DeepResearch 并未完全依赖开放网页搜索,而是接入了超过 2000 万篇高质量论文与 600+ 个专业索引源。这也直接反映在其评测结果中。
在公开基准中:
- Research Rubrics 得分 61.42%,与 Gemini 持平,超过 OpenAI
- ADR-Bench 中对比头部模型,胜率 / 平局率合计 67.1%
- 在引用规范性与表达质量上获得最高等级评价
在中文场景下,表现同样值得注意:
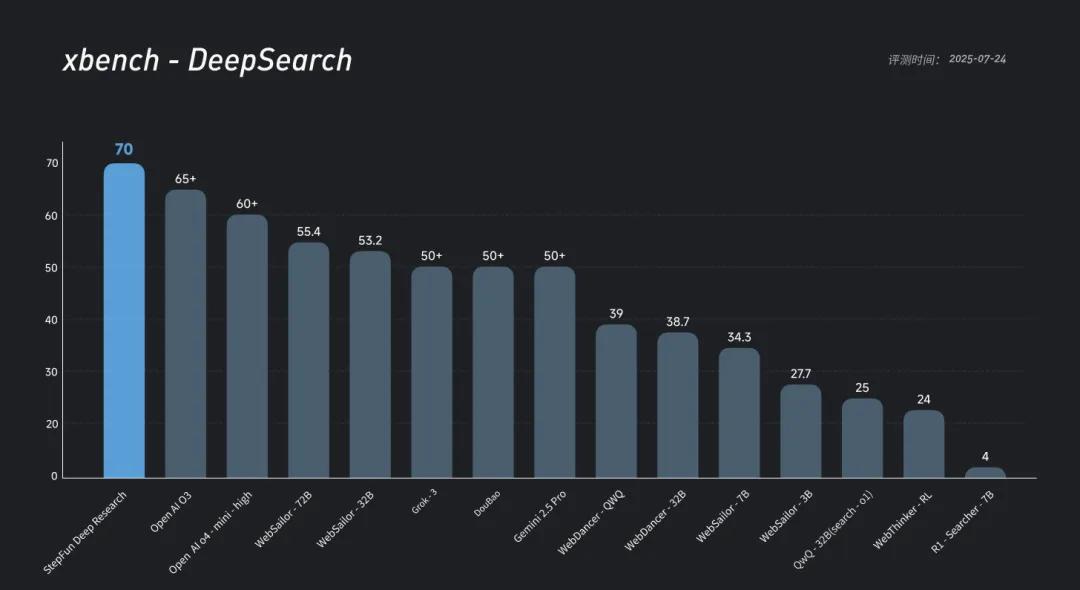
- 红杉中国 xBench-DeepSearch(中文复杂检索)通过率约 70%,位居榜首
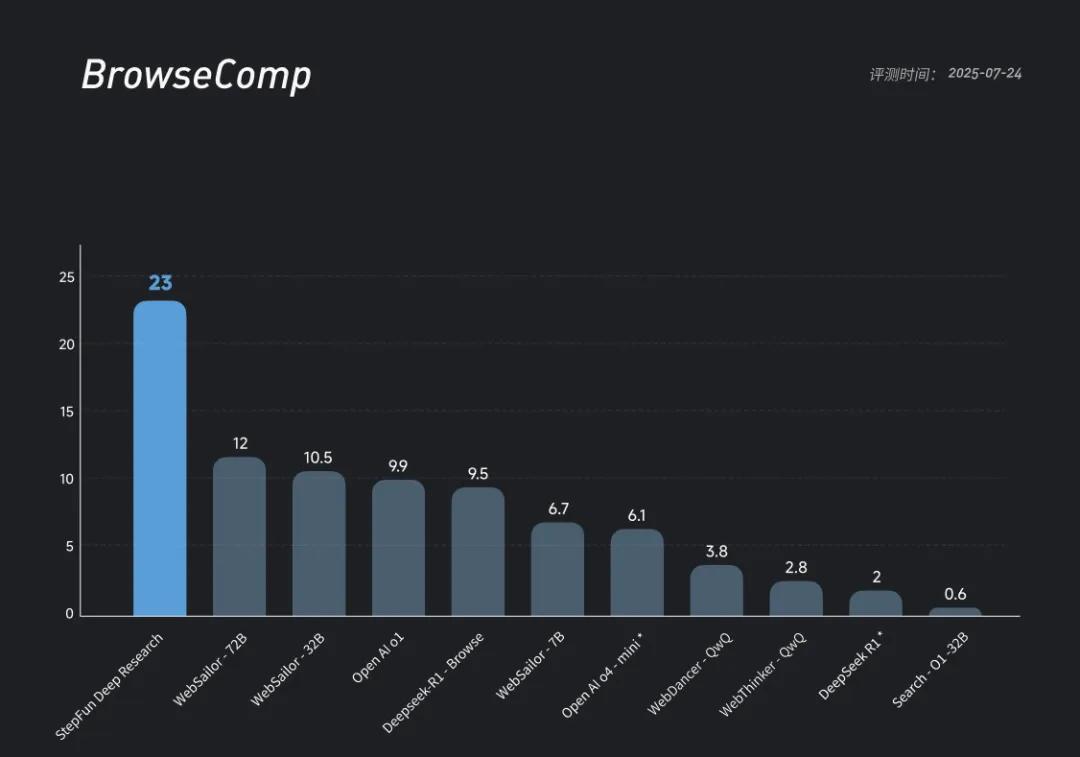
- OpenAI BrowseComp 基准中,通过率约 23%,达到已知领先水平之一
这些指标并不意味着“全面领先”,但至少说明:它不是只在 Demo 上好看。
从设计取向来看,Step DeepResearch 明确指向的是高频产出研究结论的人群:
- 投研、咨询、政策与行业研究
- 法律、医疗、学术与技术分析
- 需要反复做信息核查与趋势判断的管理岗位
它的价值不在于“替你思考”,而在于把低价值、高耗时的研究动作压缩掉,让人类把精力放回判断与决策本身。
某种程度上,它更像一个可以被纠正、被约束、被反复使用的研究助理,而不是聊天型工具。
如果你关心的是:
- Agent 是否真的能完成完整研究链路
- 中文复杂信息环境下是否可用
- 引用、验证、可复核是否被当成核心能力
那么 Step DeepResearch 至少值得进入你的观察列表。 它未必已经是“终极解法”,但它对“研究”这件事的拆解方式,明显比多数产品走得更远。
目前,Step DeepResearch 已作为「深入研究」模式,集成在阶跃 AI 的聊天产品中。 用户只需在对话界面中切换至「深入研究」模式,即可发起完整的研究任务。
在这一模式下,同一个入口同时支持文本提问、链接输入以及文件上传(包括 XLSX、CSV、PDF、DOCX 等格式),研究任务会在云端自动执行,用户无需保持在线。
此外,Step DeepResearch 已开放 API Beta,面向希望将深度研究能力嵌入自身系统或工作流的团队与开发者使用。
当前该能力仍处于测试阶段,需通过官方渠道申请体验或获取 API 访问权限。
参考资料:https://stepfun.ai/deep-research-invitation
 豫公网安备41010702003375号
豫公网安备41010702003375号