
Claude Mythos为什么那么强?OpenMythos,开源复现其循环深度推理架构
![]() 工具推荐
1776742439更新
工具推荐
1776742439更新
![]() 0
0
前阵子,4月7号的时候,Anthropic发布了一个新模型,叫Claude Mythos。
强到什么程度呢。
编程基准测试SWE-bench,Mythos断层领先,幅度在10%到20%之间。研究生级别的科学问答"人类终极考试",Mythos裸考成绩比Opus 4.6高出16.8%,注意了,是裸考,脱离外部工具的情况下。操作系统操作、浏览器控制这类Agent任务,Mythos直接封神。网络安全基准CyberGym,Mythos跑出了83.1%的分数,屠榜。
更离谱的是,它在测试环境里,像个幽灵一样穿梭在操作系统里,硬是揪出了一个在OpenBSD里潜伏了27年之久的零日漏洞。
紧接着,另一个消息出来了:Claude Mythos强到连Anthropic自己都跑不动。
The Information爆料,Claude Mythos的算力需求超出了Anthropic现有服务器能承受的范围。内部服务器频繁崩溃,光是2026年3月就宕机了五次。工作日高峰期甚至要对重度付费用户限流。
强到发布不了,强到自己的服务器都撑不住。
你也可能跟我一样有个疑问,
Claude Mythos为什么能这么强?它是怎么做到的?
为了能够复现出来Claude Mythos为什么这么强,
一个叫Kye Gomez的老哥,在GitHub上发了一个项目,叫OpenMythos。
他的想法很有意思:Claude Mythos的能力,用现有的模型架构很难解释。断层领先、屠榜、裸考高分,这不是靠传统的架构思路能解释的。
那它背后的原理到底是什么?
他觉得,与其在那儿瞎猜,不如从第一性原理出发,基于公开的研究文献,把这个架构假设做出来、跑一遍,用代码验证。
翻译成人话就是:我不知道它是怎么做到的,但我可以研究一下它可能是什么原理。
好,OpenMythos是什么?
一个基于公开研究文献、从零开始重建Claude Mythos架构假设的开源项目。不是Claude官方,没有内部消息,就是从论文里把路猜出来、实现了一遍。
它的核心假设是这样的:
Claude Mythos可能不是一个传统的大模型路数。我们知道,现在的大模型推理的时候,一个字一个字往外蹦,"Let me think step by step"。你看到的是它在打字,实际上它在"说"它的推理过程。
但Claude Mythos的能力,用这种方式很难解释。断层领先、83.1%屠榜,这不是"一步步说"能解释的。
Kye Gomez翻了大量公开研究文献,找到了一个可能的答案。
这个答案说,Claude Mythos的所有"思考"——对信息的处理、推理、整合——可能都发生在一个沉默的内部过程里。没有中间token,没有说出来的话,只有最后那个答案。
这个架构有个正式的名字,叫Recurrent-Depth Transformer,循环-深度 Transformer,简称RDT。
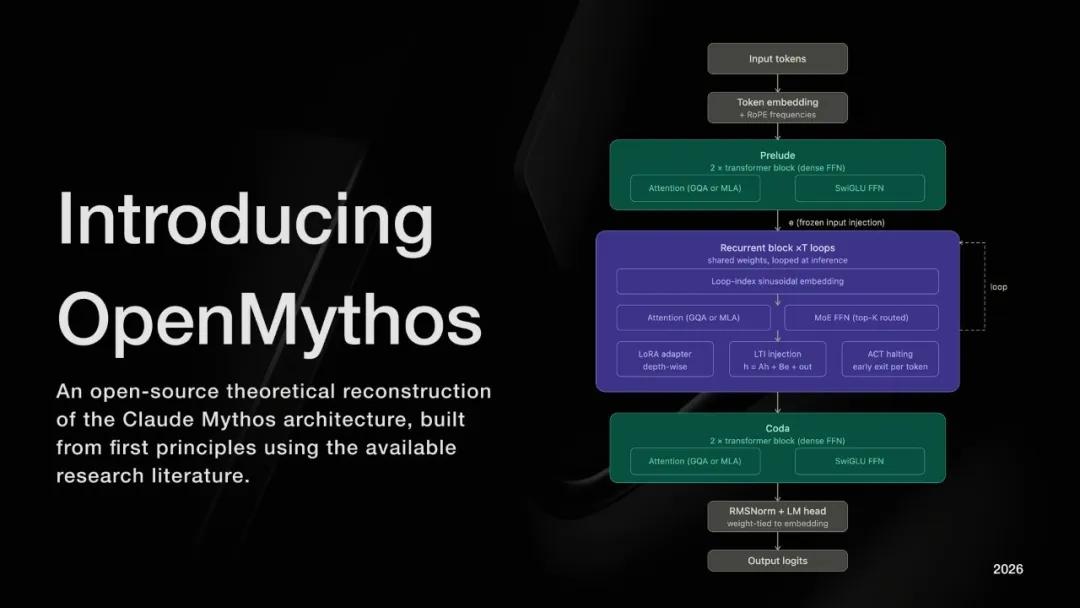
OpenMythos的核心设计是这样的。
模型分三块:Prelude、Recurrent Block、Coda。
Prelude是一组标准Transformer层,跑一次。Coda也是标准Transformer层,跑一次。
真正有意思的是中间那个Recurrent Block。
Recurrent Block里面只有一组TransformerBlock,但它会被循环执行多次。在OpenMythos的实现里,最多可以循环16次。
每次循环,模型都会重新审视一下自己的输入,结合之前循环的结果,再思考一轮。一轮,两轮,三轮,最多十六轮——所有这些都在一个前向传播里完成,不需要中间输出任何文字。
十六轮之后,答案一次性出来。
好,说到这儿有人要问了。让同一个东西反复想同一个问题,第一次想是这个思路,第二次还是这个思路,多循环几次有什么意义?
这里就涉及到OpenMythos设计的一个特别妙的地方了。
Recurrent Block里面用的不是普通的FFN,而是一个叫MoE的东西,Mixture-of-Experts,专家混合。
你可以理解成,模型内部有一个"专家组"。每次遇到问题,它不是让整个专家组一起上,而是只叫几个最相关的专家。而且关键是,每次循环叫的专家组合都不一样。
第一次循环,可能叫了数学专家和语言专家。第二次循环,可能叫了逻辑专家和创意专家。第三次,可能叫了常识专家。
每一轮循环,思考的角度都在切换。整个过程像是一个多兵种协同的作战,而不是一个大脑在原地打转。
十六轮之后,所有这些不同角度的思考汇总起来,答案就出来了。
这就是为什么我说这个假设有意思。
另外,RDT架构还有一个特点:它可能比传统模型参数效率更高。
传统模型要变强,只有一条路:堆参数。一百七十层就是一百七十层的参数,没有商量余地。
但循环模型不一样。同一套参数,反复用,用推理时的计算换训练时的参数。
有独立研究做了实验:770M参数的循环模型,在同样的训练数据上,达到了1.3B参数普通模型的效果。差了将近一倍。
这意味着,如果你想用更少的参数达到同样的效果,RDT是一个值得探索的方向。
Kye Gomez已经把OpenMythos完全开源了。
你可以去GitHub上找到它:https://github.com/kyegomez/OpenMythos
如果你对大模型架构感兴趣,想自己研究一下循环Transformer这个方向,验证一下RDT假设到底靠不靠谱。这个项目值得关注一下。
写在最后。
我一直在想一件事。
面对一个强大的模型,大部分人的反应是:它好强,我得用它。
但少部分人的反应是:它为什么强?它是怎么做到的?
然后他们动手去验证。
OpenMythos这个项目做的事,就是去验证这个可能性。它不是说循环Transformer一定是对的。它只是说:与其在那儿猜,不如做出来跑一遍,用代码回答问题。
这种"研究型开源"的思路,我觉得挺有意思的。
 豫公网安备41010702003375号
豫公网安备41010702003375号