
模型中转站:9Router,统一管理API密钥+自动切换模型+RTK压缩=省钱80%
![]() 工具推荐
1778556462更新
工具推荐
1778556462更新
![]() 0
0
你有没有想过一个问题。
你买了GLM的Coding Plan,买了MiniMax的API,买了Claude Code的订阅,还在用OpenAI的点数。
然后呢?
OpenClaw要配一套密钥,Cursor要配一套密钥,Claude Code要配一套密钥,VS Code的Cline又要配一套。
每个工具都要单独配置,每个账号都要单独管理,密钥散落一地。
更要命的是,你发现没有,配额永远不够用。
Claude Code用完了,Cursor还在那闲着。GLM额度用超了,MiniMax还有一堆没用。一边是资源浪费,一边是配额告急。
我当时就在想,这不对劲啊。
为什么不能一个账号的配额用完了,自动切换到另一个?为什么不能统一管理、统一路由、统一监控?
然后我就发现了9router这个项目。
它解决的,就是这个问题。
它本质上就是一个本地运行的AI流量中转站。你所有的AI编程工具,都只需要连接它。它再帮你把请求分发到具体的后端。
┌─────────────────────────────────────────────────────────────┐│ ││ OpenClaw ──→ 9Router ──→ GLM (你的Coding Plan) ││ │ (中转站) ──→ MiniMax (备用) ││ │ ──→ Kiro (免费Claude 4.5) ││ │ ──→ Claude Code (你的订阅) ││ ↓ ││ 配置一次,全网通用 ││ │└─────────────────────────────────────────────────────────────┘你只需要在这个中转站里配置一次你的API密钥,以后所有工具都只需要连这个中转站。
它会自动帮你路由,自动切换,自动压缩token,自动记录用量。
说实话,刚看到这个东西的时候,我就一个感觉,卧槽这也太理所当然了。
为什么这种东西之前没有人做?
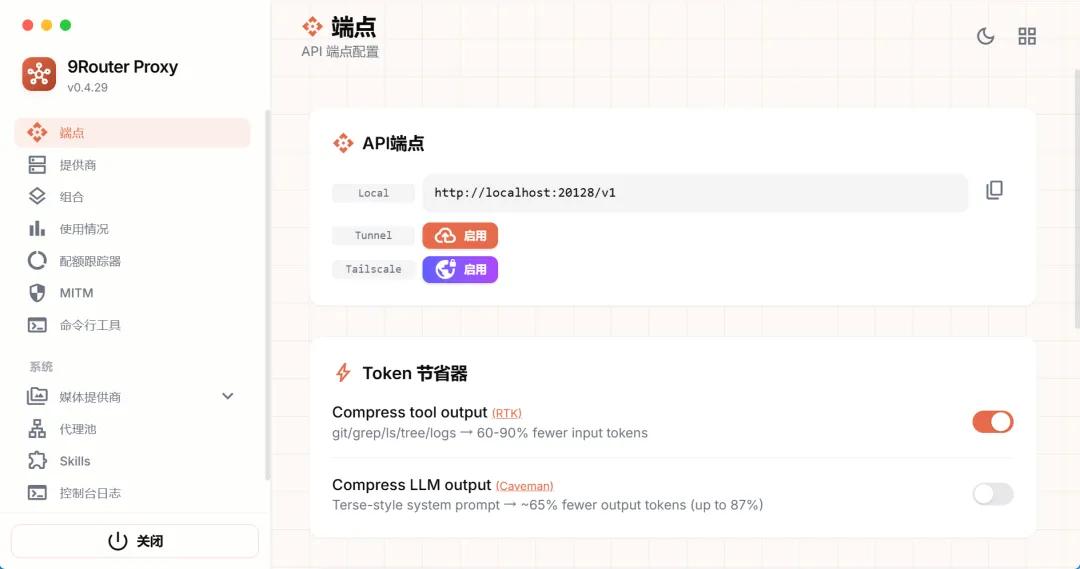
它是怎么省钱的?
既然叫中转站,光转发流量那不叫省钱,那叫多此一举。
它省钱的逻辑有两层。
第一层,3-tier自动切换。
你设置一个Combo,可以理解为一个自动档的档位配置:
第一档,主力,用你最强的AI订阅。
第二档,备用,便宜的按量付费AI。
第三档,保底,免费的AI。
举例来说,我的Combo是这样配置的:
主力:cc/claude-opus-4-7(Claude Code订阅,$20/月)
备用:glm/glm-5.1(输入6.5元/百万token)
保底:kilo-auto/free(Kiro免费模型)
工作流程是这样的:Claude Code订阅还有额度的时候,用最强的主力。订阅快用完了,或者出错了,自动切到GLM。GLM也用完了,自动切到Kiro。
整个切换过程是全自动的,你那边的编程工具完全感知不到。
这意味着什么?你不需要再每天盯着配额看,不用手动切换,不用焦虑会不会用超。一切都是自动的,你只管写代码,剩下的交给系统。
第二层,RTK Token节省器。
这个是我见过最离谱的省token方案。
你用AI编程工具的时候,AI需要阅读大量的工具输出。git diff、grep结果、ls列表、tree目录结构,这些内容有时候占你请求token的30%到50%。
RTK会自动检测这些内容,然后压缩它。
举个例子,你执行了一个git diff,原来的输出是:
diff --git a/src/app.jsindex 8f1234a..9b5678c 100644--- a/src/app.js+++ b/src/app.js@@ -1,5 +1,6 @@ function hello() {- console.log("Hi");+ console.log("Hello World");+ return true; }压缩之后变成:
[f:src/app.js] [-Hi → +Hello World, +return]内容量完全一样,但token消耗减少了60%到90%。
这意味着什么?意味着你同样的配额,能用更久。更猛的是,它还支持Caveman模式,压缩AI的输出,最多能节省65%的输出token。
输入压缩加输出压缩,双重省token。
你说这东西省不省钱?我就问你省不省钱?
甚至,如果一分钱都不想花,也有办法。
方案一:NVIDIA NIM免费模型。
NVIDIA提供了免费模型访问,也是最慷慨的,通过NIM端点:
Base URL: https://integrate.api.nvidia.com/v1可用的,基本能正常响应的有如下几个模型,包括:
- openai/gpt-oss-120b
- qwen/qwen3-next-80b-a3b-instruct
- qwen/qwen3.5-397b-a17b
- qwen/qwen3.5-122b-a10b
- nvidia/nemotron-3-nano-omni-30b-a3b-reasoning
方案二:DeepSeek免费聊天转API。
ds2api是一个开源项目,可以把DeepSeek官方免费聊天能力转换成API使用。
这样你就能用DeepSeek的免费模型,通过API方式接入9Router。
方案三:OpenCode和Kilo的免费模型。
minimax-m2.5-free以及kilo-auto/free模型,完全免费。
说了这么多,怎么用起来?
第一步,安装9Router。
它支持Docker安装,一条命令的事:
docker run -d --name 9router -p 20128:20128 -v 9router-data:/app/data 9router安装完成后,打开浏览器访问 http://localhost:20128 ,初始密码是123456。
第二步,连接模型提供商。
Dashboard点击Providers,找到自己已经订阅的模型提供商。
设置名称,填入API key,同时支持多key。选择模型保存。
第三步,创建Combo。
Dashboard点击Combos,点击Create New。
Name随便取,比如free-forever,Models配置:
主力:kilo-auto/free
备用:minimax-m2.5-free
保底:openai/gpt-oss-120b
保存。
第四步,配置你的编程工具。
主流的编程工具都支持,OpenClaw、Hermes、Claude Code、Cursor、Cline等,直接在9Router的Dashboard里找到对应的工具卡片,选择你刚才创建的Combo,点击Apply,它会自动帮你写入配置文件。
以OpenClaw为例,我用的就是这个。
Dashboard找到OpenClaw那张卡片,选择free-forever,点击Apply。
对于不支持自定义端点的工具,比如Antigravity IDE、GitHub Copilot,9Router还提供了MITM Proxy模式,通过中间人代理的方式拦截流量实现路由。配置稍微复杂一点,但也就装一次,一劳永逸的事情。
最后说两句。
可能有小伙伴说,这东西靠谱吗?
我没法打包票,但9Router本身是开源的,GitHub上7万8千多颗星,还在迅猛增长,社区活跃度很高。
更重要的是,它本地运行,不是在云端,你的数据不经过任何第三方服务器,这个项目只是帮忙转发一下流量,隐私方面应该没什么问题。
说真的,AI编程工具这个领域,信息差太大了。
很多人不知道有免费的Opencode/Kilo模型可以用,不知道有输入6.5元/百万token的GLM便宜替代,不知道token可以压缩,不知道配额可以自动切换。
这篇文章,就是帮你磨平一些信息差。
要不要试试,你自己决定。
 豫公网安备41010702003375号
豫公网安备41010702003375号