
「找了2小时没找到」:我用LEANN把微信、邮件、浏览器全变成AI可检索的知识库
![]() 工具推荐
1779070766更新
工具推荐
1779070766更新
![]() 0
0
昨晚跟一个朋友聊天,他跟我吐槽,说他老婆翻遍了他三年的微信聊天记录,就为了找一个他记得提过一嘴的餐厅名字。找了俩小时,没找到。
我当时就想,这应该是很多人都遇到过的痛点。
我们每天在微信上聊了多少东西,工作安排、灵感闪现、甚至半夜突然想起来要买的东西。结果这些信息就这么散落在时间的洪流里,想找的时候跟大海捞针似的。
邮件也一样。浏览器历史也一样。ChatGPT的对话记录、Claude的对话记录,通通都是这样。
今天要聊的这个东西,就是来解决这个问题的。
它叫LEANN,一个开源项目,最近在GitHub上火得不行。
LEANN,说到底,就是一个本地向量数据库,但它做的事情比普通数据库有意思多了。它能让你RAG Everything。
RAG就是检索增强生成,简单说就是先把你的数据切分成小块,计算特征向量存起来,然后当你问问题的时候,它先找到最相关的块,再让AI基于这些内容回答。
比如你问「我去年推荐过朋友看什么书来着」,系统会自动找到那段聊天记录,AI基于真实内容给你回答,而不是凭空瞎编。
这玩意儿最大的特点,是它的存储效率。
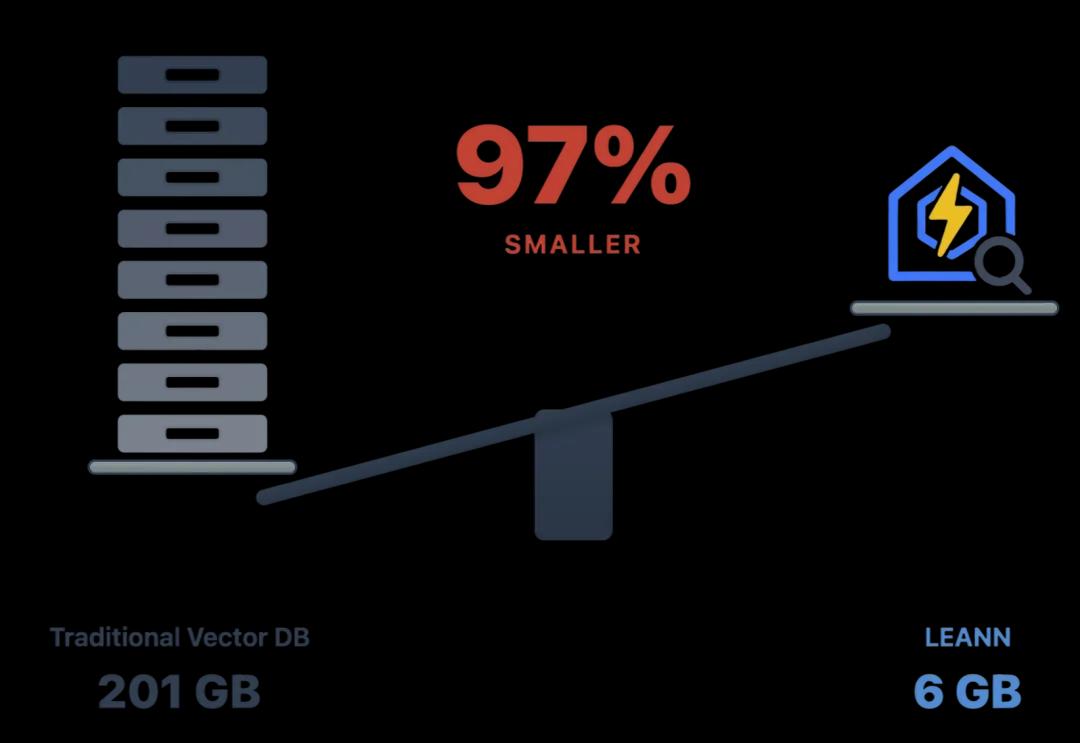
官方给的数据是这样的:处理6000万条文本片段,传统向量数据库需要201GB存储空间,而LEANN只需要6GB。97%的存储节省。
怎么做到的呢?
LEANN用的是图剪枝加选择性重计算的技术。它不像传统数据库那样把所有特征都提前算好存起来,而是只存储一个优化的图结构,搜索的时候动态计算相关特征。
打个比方,传统数据库就像你提前把所有书籍都复印了一份存到仓库里,仓库自然越来越大。而LEANN相当于只保留了一个「索引目录」,需要的时候再临时调取,而不是每次都抱着复印件跑。
真正让我觉得LEANN有意思的,是它支持的RAG场景。
它不只是一个技术框架,它是真的能做事情。
比如RAG邮件,目前支持macOS系统,你可以直接问「我上个月跟供应商讨论交货期的那封邮件在哪」。
比如RAG浏览器历史,你可以问「我之前看的那个讲Python异步编程的教程是哪来着」。
比如RAG微信聊天记录,需要先装个微信导出工具,装好之后找东西真的太好用了。
比如RAG你的知识库,本地文档、PDF、Markdown文件,通通扔进去,让AI基于你的资料回答问题。
LEANN还支持MCP集成,通过配置可以连接Slack、Twitter等平台,需要先安装对应的MCP服务器并配置API凭证,相当于给AI装了一个实时的信息触手。
说完功能说说安装使用。
最简单的方式是先clone项目代码,然后安装依赖:
git clone https://github.com/yichuan-w/LEANN.gitcd leannuv venvsource .venv/bin/activateuv pip install leann然后运行以下命令就能体验完整功能了:
python demo.ipynb这个notebook里面有几个完整的示例,跑一遍你就知道这东西能干嘛了。
我建议先从最简单的文档RAG开始玩,就是把你电脑上的PDF、TXT、Markdown文件扔进去,然后问AI几个问题,感受一下「让AI读我的文档」是什么体验。
如果你特别在意隐私,不想让任何数据离开你的电脑,那完全可以全程本地模型搞定,从embedding到最后的LLM生成,一条龙纯本地。
说实话,我第一次玩LEANN的时候,有那么一瞬间,感觉有点像当年第一次用搜索引擎。就是那种,「原来信息可以这么被检索」的感觉。
以前我们找东西,要么记得关键词去搜索,要么靠记忆在文件夹里一顿翻。但现在,你可以用自然语言问问题,「我上次跟朋友聊的那个电影叫啥来着」,AI会一瞬间帮你找到相关内容。
它意味着,你的个人数据开始真正变成你的「知识资产」了,而不是一堆躺在硬盘里的二进制文件。
这种去中心化的AI知识管理,可能真的是未来。
好了,今天就聊到这儿。
我是真的觉得LEANN这个项目挺有意思的,它让AI从「云端的服务」变成了「人人可用的本地工具」,让技术真正服务于个人。
如果这篇文章对你有一点点启发,欢迎点个赞或者转发给朋友~~
 豫公网安备41010702003375号
豫公网安备41010702003375号