
Surya:开源OCR工具 ,650M参数硬刚35B级,支持91种语言,让文档识别变得又快又准
![]() 工具推荐
1780369737更新
工具推荐
1780369737更新
![]() 0
0
最近,在GitHub上冲浪的时候,看到一个项目叫Surya。
说实话我第一反应是,又一个OCR工具。
OCR这东西大家都不陌生了,就是把图片里的文字识别出来嘛。这么多年下来,从最早的Tesseract到后来的各种商业方案,我们又不是没见过。
但是我往下翻了翻这个项目的README,Surya是一个650M参数的OCR模型。
然后我看到了一个 benchmark 叫 olmOCR-bench,这是现在OCR领域最权威的评测标准之一。
在这个榜单上,Surya得分是83.3% 。
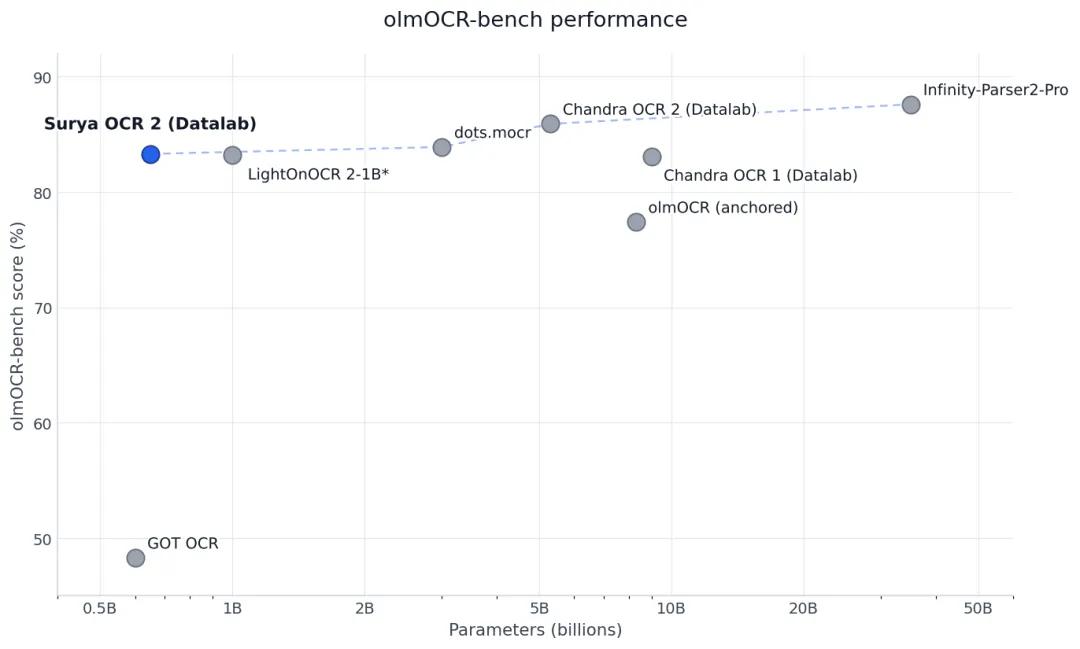
大家知道排在前面的都是些什么怪物吗?
Infinity-Parser2-Pro,35.1B参数,得分87.6。Chandra OCR 2,5.3B参数,得分85.9。dots.mocr,3B参数,得分83.9。
而Surya,一个650M参数的小家伙,得分83.3。
我看到这里的时候真的愣了一下。参数差了5到50倍,但分数就差那么一点点。
Surya(音:苏-瑞-亚)这个词大家可能有点陌生,但是如果我告诉你这是印度神话里的太阳神,你应该就能get到了。
太阳神苏利耶在印度神话里有个很重要的能力,叫"普照万物,无所不见"。
我觉得开发者给这个项目起这个名字,可能就是想表达:不管是报纸、教科书、手写笔记、表格、公式,我都能给你看清楚。
说起来,项目里还真就展示了这几种文档类型的处理效果。新闻报纸、教材、手写笔记、税务表格,甚至还有数学公式(LaTeX格式),统统都能识别。
甚至连那种年代久远的扫描件,它也能处理。当然了,评测数据也诚实说了,老扫描件的得分只有41.8% ,不算高,但是能跑起来已经很不错了。
OCR工具处理PDF的速度一直是大家关心的问题。
Surya官方给出了详细的性能数据:在RTX 5090上(96 DPI输入条件下),吞吐量是每秒5.35页,一分钟能处理超过300页。对比Apple Silicon的表现,在Metal加速、并发8的情况下约为0.108页每秒。这个数字跟并发设置关系很大,调高并发配置可以进一步提升速度。
按照官方给出的测试数据,日常处理几十页的PDF通常只需要十几秒,这个速度对于个人使用来说确实很可观了。
现在市面上很多OCR工具,中文勉强能行,日文韩文就开始拉胯,小语种更是想都别想。
但是Surya在这块的表现则就夯了不少。
官方说,他们在91种语言上做了内部测试,综合通过率是87.2% 。
我摘几个大家熟悉的语言出来看看:英文92.3% ,法语89.3% ,德语89.7% ,日语86.2% ,中文82.5% ,阿拉伯语稍微低一点72.7% 。
91种语言,整体能维持在87%以上的通过率,这个覆盖度确实可以的了。
以后要是有人让你帮忙识别个日语文档、阿拉伯语合同什么的,扔给它就行了,不用再满世界找小语种OCR方案。
光说数字可能有点虚,我给大家拆解一下Surya具体能处理哪些任务。
第一个,文本检测。就是告诉你这张图里的文字都在什么位置,框出来。
第二个,文字识别。找到文字之后,把内容读出来。
第三个,布局分析。不只是读文字,它还能分清楚这是标题、这是正文、这是表格、这是图片说明。顺便把阅读顺序也排好。
第四个,表格识别。不只是识别表格,还能标出行和列的位置,把表格结构还原出来。
第五个,数学公式识别。Surya 2能把图片里的公式转成代码,而且是作为全页OCR的一部分统一输出的,公式会以<math>...</math>标签的形式嵌入HTML文本,LaTeX格式是KaTeX兼容的。这比很多需要单独调用OCR工具来处理公式的方案方便多了。
第六个,手写识别。手写笔记这种东西,普通的OCR基本抓瞎,但是Surya是可以处理的。当然了,手写体这东西识别难度本来就高,效果肯定不如印刷体,但是"有"这个功能本身就已经很有价值了。从官方展示的效果图来看,英文手写的识别效果看起来还可以,中文手写的话可能因为训练数据的缘故,还需要再观察观察效果。

用起来麻烦吗?
说实话,一开始看到它依赖vllm或者llama.cpp的时候,我心里是有点犯嘀咕的。以为又要折腾一堆环境配置。
但是看完文档之后发现,其实还好。
如果你有NVIDIA的显卡,它会自动用Docker启动vllm服务,你基本上不用管。
如果是Mac或者纯CPU环境,它会走llama.cpp那条路,brew install llama.cpp或者手动下载二进制文件都行。
安装就一行命令:pip install surya-ocr
使用也简单,命令行直接 surya_ocr 文件路径,完事儿。
它支持图片、PDF、文件夹,扔进去就行。也可以用Python调用,三五行代码就能跑起来。
最后说两句。
其实我之前对OCR这个领域关注不多,总觉得是个成熟市场,没什么新鲜的。
但是Surya让我意识到一个问题:大模型时代,很多事情的性价比正在被重新定义。
以前觉得只有几十B的大模型才能做好的事情,现在可能一个650M的模型就能做到七八成的水准。
这对于我们普通用户来说意味着什么?
意味着更低的硬件门槛,更快的处理速度,更少的成本。
以后,在笔记本上跑一个本地OCR工具,不再是痴人说梦。
AI这东西,真的越来越接地气了。
今天就聊到这儿。如果你对这个项目感兴趣,直接去GitHub搜surya-ocr就行,文档写得很清楚。
大家有什么问题欢迎留言,我们下次见。
 豫公网安备41010702003375号
豫公网安备41010702003375号