
Meta提出大型概念模型(LCM),可将语言进行抽象化处理
![]() 前沿资讯
1734343807更新
前沿资讯
1734343807更新
![]() 0
0
Meta在社交媒体平台的运营中面临着一个极为复杂的语言挑战,其平台上活跃着超过200种语言。在这样一个多语言的环境下,人力成本的消耗成为了一个显著的问题,无论是人工运营方面,还是涉及到不同语言之间的翻译工作,都需要投入大量的人力。例如,每一种语言的内容审核、用户交互管理等运营工作都需要专业人员的参与,而语言之间的差异使得翻译工作不仅量大,且需要精准的把握,同时,这些因素也在一定程度上限制了其向新市场拓展规模的速度,进而影响了利润的增长。
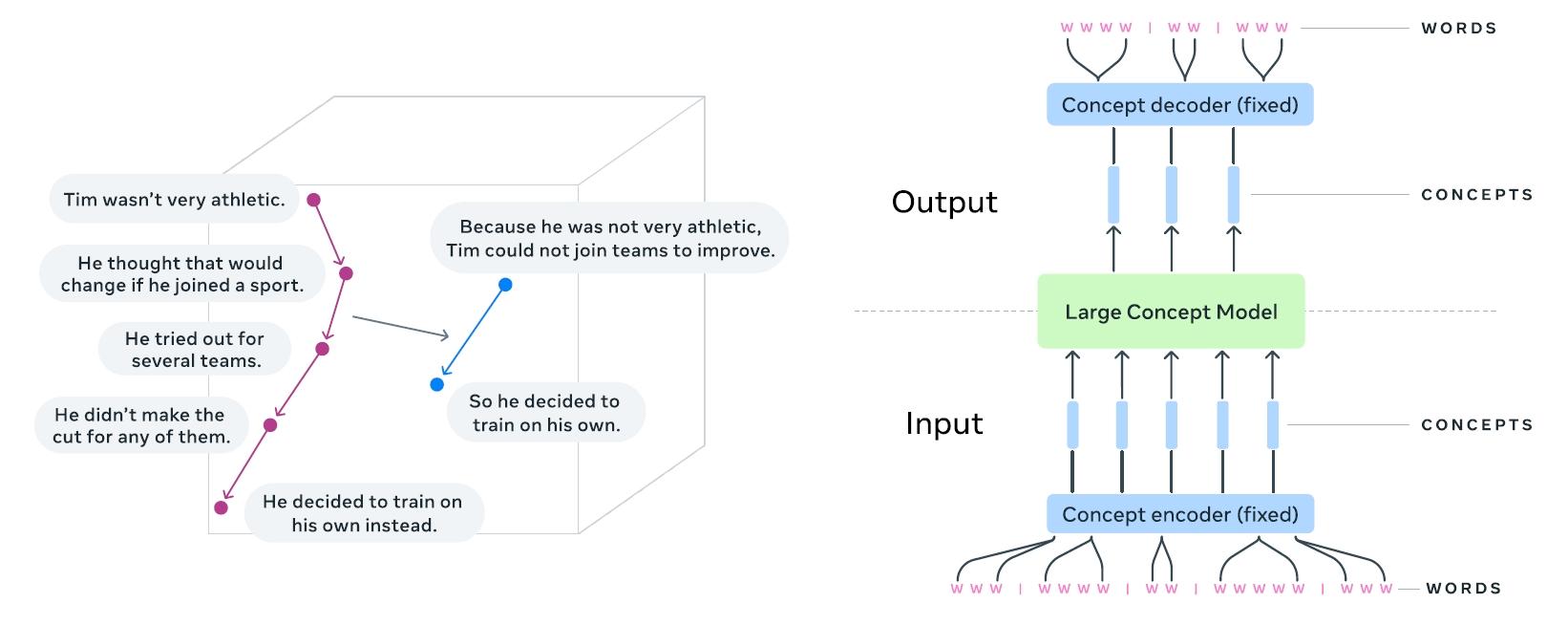
为了有效地解决这些问题,Meta提出了大型概念模型(LCM)。LCM的核心思路是将语言从通信过程中进行抽象化处理,它引入了“消息”的概念,将消息内容与编码消息的语言分离开来,这样一来,无论消息是用英语、法语、西班牙语、意大利语还是葡萄牙语等任何一种语言编写,都可以将其转化为一种基于数学概念的内容表示。通过这种方式,Meta希望能够简化操作流程,减少对大量人力的依赖,从而降低成本。在内容审核时,可以基于统一的数学概念对消息内容进行分析和处理,同时,这种抽象化的处理方式也有利于更好地整合不同语言的资源,提高信息处理的效率,为拓展新市场提供了可能。
LCM基于现有的句子嵌入机制Sonar来构建新的嵌入空间。Sonar通过特定的算法将句子转化为向量表示,从而在向量空间中对句子进行编码。在这个过程中,模型使用完整的Transformer架构,包括编码器和解码器,编码器负责将输入的句子进行编码,将其转化为向量形式,而解码器则在需要生成输出时发挥作用。初始化时,模型采用预训练的机器翻译模型权重结构,模型能够借助已有的语言知识进行快速的启动和优化。
与其他模型不同的是,LCM不使用token级别的交叉注意力,这一设计决策使得模型在处理句子时更加关注句子整体的概念表示,而不是单个token之间的关系。例如,在处理一个长句子时,模型会将其作为一个整体进行编码,而不是分散地处理每个单词或字符。每个句子在Sonar中被编码后,就可以在向量空间中构建概念或句子序列。LCM的训练方式类似于大语言模型(LLM),它能够从不同语言和模态中学习知识,无论是书面文本、口语表达,还是其他形式的信息,只要能够被转化为相应的向量表示,都可以被LCM学习和理解。
LCM具有显著的优势,首先,它能够处理多种语言和模态,无论是书面文字、口语表达,还是图像、音频等其他形式的信息,只要能够转化为相应的数学表示,LCM都可以进行处理。它可以在数学空间中整合不同语言的知识,将各种语言表达的概念映射到同一数学框架下,从而打破语言壁垒。此外,通过扩散过程,LCM能够处理有缺陷的数据。在实际应用中,数据往往存在各种噪声和不完整的情况,LCM的扩散过程可以对这些有噪声的句子嵌入表示进行逐步精炼,使其转化为干净、有意义的表示,进而生成逻辑结构化的输出。
Meta的大型概念模型为传统基于token的语言模型提供了一种有前景的替代方案,通过高维概念嵌入和模态无关处理,解决了现有方法的一些关键局限,有望重新定义语言模型的能力,为 AI 驱动的沟通提供更具可扩展性和适应性的方法。
 豫公网安备41010702003375号
豫公网安备41010702003375号