
通义千问团队发布Qwen2.5-VL应用案例集
![]() 前沿资讯
1738320762更新
前沿资讯
1738320762更新
![]() 0
0
刚刚,通义千问团队发布了Qwen2.5-VL的应用案例集,该案例集包含了多个文档,展示了其在本地模型和API方面丰富的应用场景。

在计算机操作应用中,模型能截取桌面截图并解读用户查询意图;空间理解应用展示了模型先进的空间定位与复杂场景解读能力;文档解析应用表明了模型强大的文档处理能力,还引入独特的Qwenvl HTML格式;移动智能体应用通过智能体函数调用可以与移动设备交互;光学字符识别应用可从图像提取识别文本;通用识别应用可接收图像和查询指令解读意图;视频理解应用能理解超1小时视频,可用于多种视频分析场景。
Qwen2.5-VL是通义千问团队于1月26日发布的全新旗舰视觉语言模型,相较于之前的Qwen2-VL有重大飞跃。用户可访问通义千问聊天平台,选择Qwen2.5-VL-72B-Instruct模型进行体验,其基础模型和指令模型在Hugging Face和魔搭社区(ModelScope)开放,涵盖30亿、70亿和720亿参数规模。

该模型具备诸多核心特性:视觉理解能力出色,能识别常见物体,还能分析图像中的文本、图表等;智能体功能强大,可作为视觉智能体推理并动态调用工具;能理解超1小时长视频,新增精准定位相关视频片段捕捉事件能力;多格式视觉定位精准,可精准定位图像中物体并输出JSON格式数据;支持发票、表单等扫描数据结构化输出,方便金融、商业领域应用。
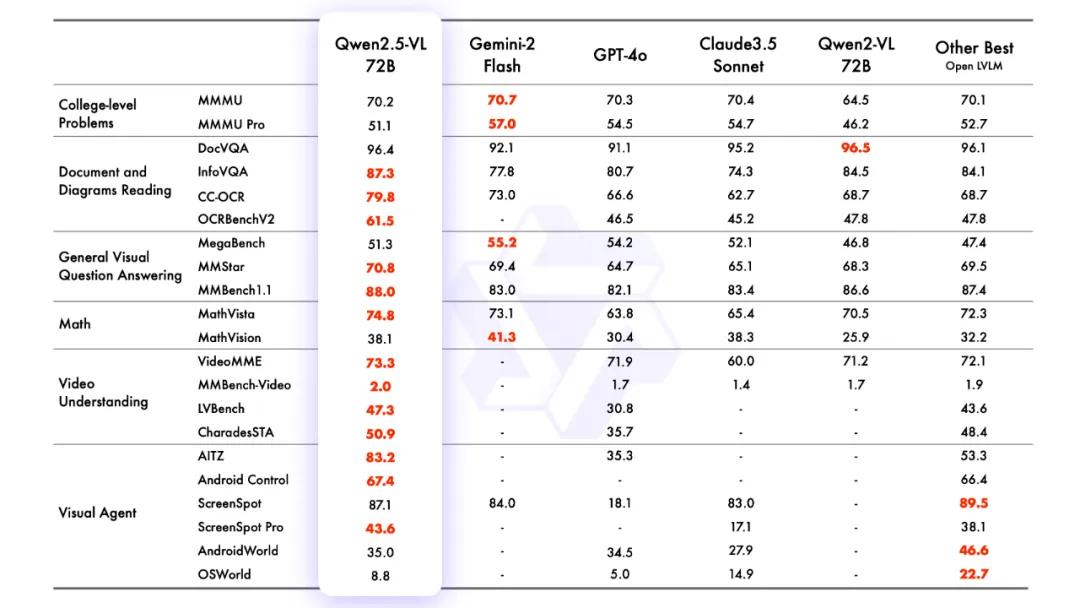
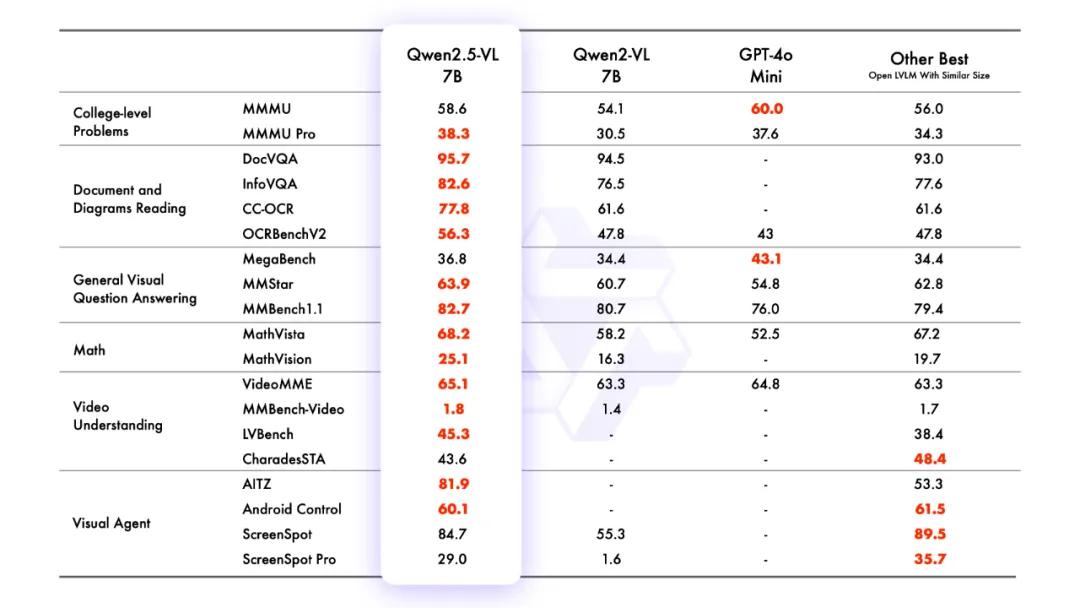
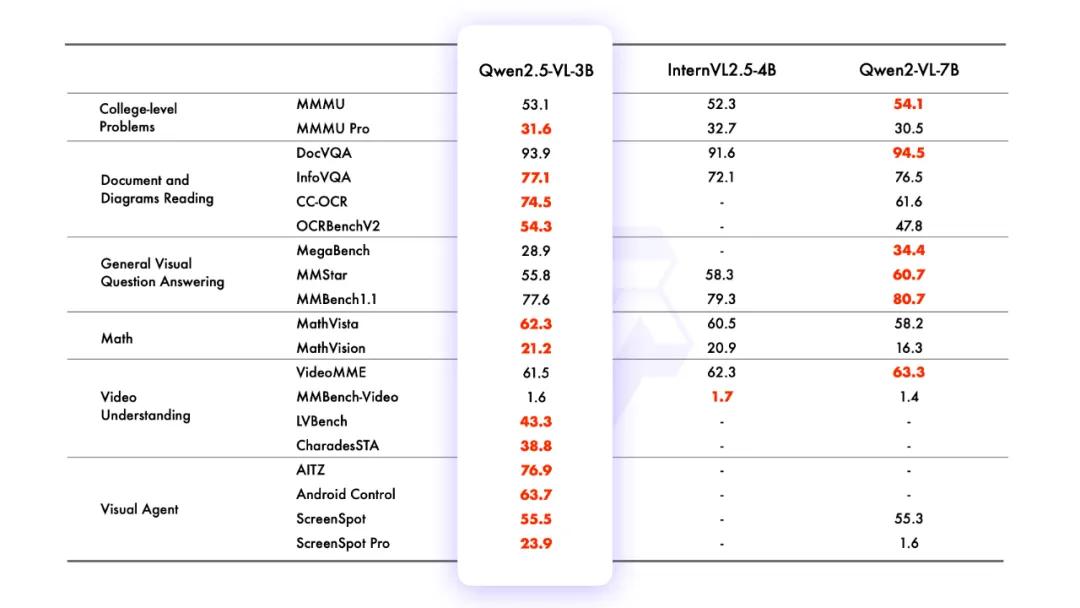
性能表现上,旗舰模型Qwen2.5-VL-72B-Instruct在多领域多任务基准测试中表现出色,在文档和图表理解方面优势显著,无需针对特定任务微调就能发挥视觉智能体作用。较小参数模型中,Qwen2.5-VL-7B-Instruct在多项任务上超越GPT-4o-mini,Qwen2.5-VL-3B作为边缘AI解决方案性能超过上一版本Qwen2-VL的70亿参数模型。
模型能力方面,全球图像识别能力卓越,图像类别扩展到超大量级;能精确目标定位,利用边界框和基于点的表示实现分层定位和标准化JSON输出;文本识别与理解能力升级,OCR识别及多场景文本定位性能增强,信息提取能力也显著提升;有强大的文档解析能力,设计独特的QwenVL HTML格式基于HTML提取布局信息,可在多种场景解析文档;视频理解能力增强,引入动态帧率训练和绝对时间编码技术,支持超长视频理解和秒级事件定位。
相较于Qwen2-VL,Qwen2.5-VL增强了模型对时间和空间尺度的感知能力,简化了网络结构以提高效率。在空间维度能动态转换图像尺寸标记,直接用实际尺寸比例表示坐标;时间维度引入动态帧率训练和绝对时间编码,让模型学习时间节奏。全新训练原生动态分辨率的视觉Transformer,引入窗口注意力机制降低计算负载,采用RMSNorm和SwiGLU结构简化网络,使ViT架构与大语言模型更一致。未来,该团队表示还将进一步提升模型的问题解决和推理能力,融入更多模态,使其朝着集成全能模型迈进。
 豫公网安备41010702003375号
豫公网安备41010702003375号