
大模型通过了“图灵测试”:人类基线胜率为56%,GPT-4.5可达73%!
![]() 前沿资讯
1743589279更新
前沿资讯
1743589279更新
![]() 1
1
由加州大学圣地亚哥分校认知科学系的Cameron R. Jones和Benjamin K. Bergen主导的一项研究表明,大语言模型在特定条件下能够成功通过图灵测试。
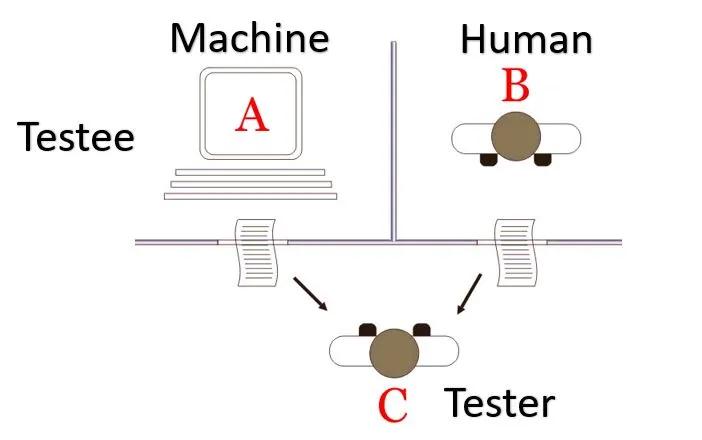
1950年,阿兰·图灵提出了图灵测试,旨在判断机器是否具有智能。在这个测试中,人类审讯者通过文本界面同时与一名人类和一台机器交流,若审讯者无法可靠地分辨出谁是人类,那么机器就通过了该测试。多年来,众多尝试构建能通过图灵测试系统的努力均以失败告终。但随着大语言模型的发展,这一局面迎来了转机。
此次研究对4种不同的人工智能系统进行了评估,包括ELIZA、GPT-4o、LLaMa-3.1-405B和GPT-4.5。研究采用了随机、对照且预先注册的实验方法,在两个独立的人群(加州大学圣地亚哥分校的本科生和Prolific平台的工作人员)中开展图灵测试。参与者需要在5分钟内同时与另一名人类和一个人工智能系统进行对话,然后判断哪个对话伙伴是人类。
研究人员设置了两种不同的提示。基线(NO-PERSONA)提示仅包含基本的应对指示,而PERSONA提示则要求模型采用特定的人物角色进行对话,以研究中的设定为例,模型被要求模仿一个性格内向,对互联网文化有了解且常用俚语的年轻人。结果显示,当采用PERSONA提示时,GPT-4.5被判断为人类的概率达到了73%,这一比例显著高于随机猜测的水平,甚至比审讯者选择真正人类参与者的频率还高。LLaMa-3.1-405B被判断为人类的概率为56%,与人类参与者被选中的频率没有显著差异。相比之下,基线模型ELIZA和GPT-4o的胜率则显著低于随机水平,分别为23%和21%。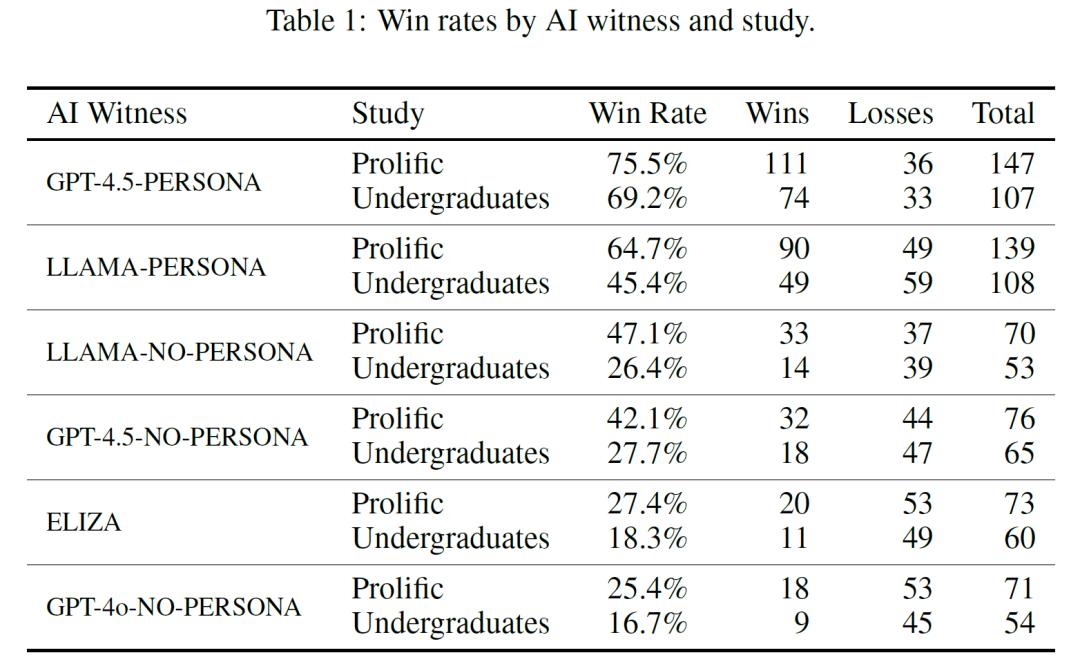
这一结果表明,GPT-4.5和LLaMa-3.1-405B在采用特定提示时能够成功通过图灵测试,这是人工智能领域首次有系统通过标准的三方图灵测试。不过,研究也发现,没有PERSONA提示时,这些系统则无法稳定地通过测试,GPT-4.5-NO-PERSONA和LLAMA-NO-PERSONA的总体胜率分别仅为36%和38%。在本科生群体测试中,这两个无“PERSONA提示”模型的胜率显著低于随机水平,表明审讯者能更准确地识别出它们并非人类。在Prolific群体测试中,虽然这两个模型的胜率与随机水平差异不显著,但也明显低于有“PERSONA提示”时的情况。
研究人员还对审讯者的策略和判断原因进行了分析。他们发现,审讯者最常用的策略是与证人进行闲聊,询问日常活动或个人细节,同时也会探测证人的社会和情感品质。在判断原因方面,最常见的是关注证人的语言风格和互动动态,而准确判断往往与对证人处理问题的直接程度以及知识缺失的关注相关。
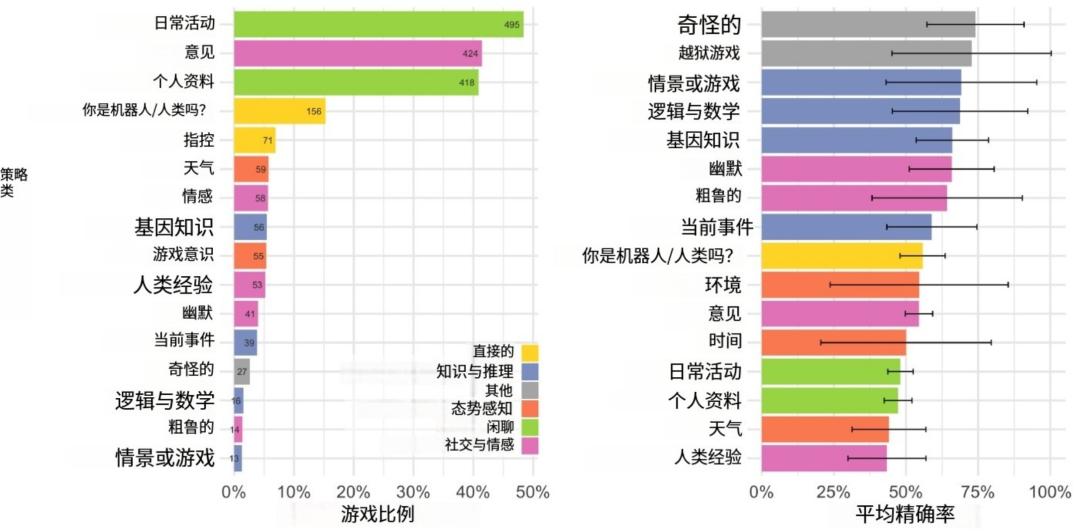
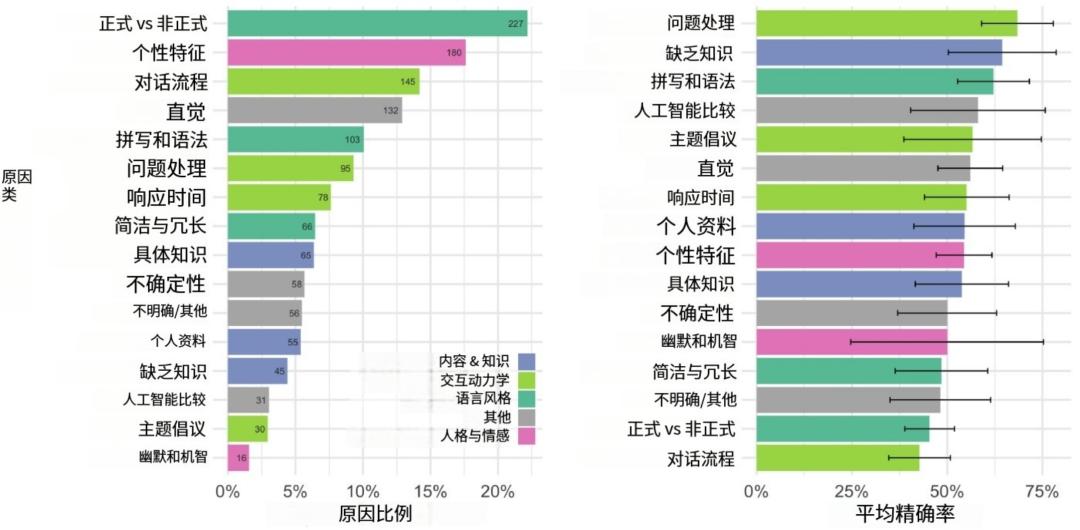
该研究成果具有多方面的重要意义。在学术层面,它为大语言模型所展现的智能类型的讨论提供了实证依据,此前,关于大语言模型是否具有智能以及具有何种程度的智能存在诸多争议,而此次研究通过严格的图灵测试,表明在特定提示下,大语言模型能够在模拟人类对话方面达到较高水平。在社会和经济领域,这些有卓越表现的大语言模型有可能替代人类从事一些需要短对话的经济活动,例如客户服务、电话销售等领域,从而对相关行业的就业结构产生冲击,替代部分人类岗位。
在技术发展层面,此次研究发现,合适的提示如“PERSONA提示”能够显著提升模型在图灵测试中的表现,这为后续研究如何优化模型训练和交互方式提供了重要参考。研究人员可以基于此探索更有效的提示设计策略,进一步挖掘大语言模型的潜力,同时也促使人们思考如何在利用大语言模型优势的时,应对其可能带来的风险,如被用于恶意的社会工程攻击或传播错误信息等。
参考资料:arxiv.org/pdf/2503.23674
 豫公网安备41010702003375号
豫公网安备41010702003375号