
DeepSeek-GRM模型问世:解锁通用奖励建模新高度
![]() 前沿资讯
1743849593更新
前沿资讯
1743849593更新
![]() 0
0
【摘要:DeepSeek公布了《通用奖励建模的推理时缩放》研究,探索了如何通过增加推理计算量来改进通用查询的奖励建模,提出了自原则性批判调优(Self-Principled Critique Tuning)方法,借助在线强化学习,在点生成式奖励建模(GRMs)中培养可扩展的奖励生成行为,进而打造出DeepSeek-GRM模型。】

随着技术的不断迭代,大语言模型在自然语言处理的诸多任务上展现出了惊人的能力,从文本生成、问答系统到语言翻译等,都取得了显著的成果。这一快速发展不离不开各种优化手段的应用,强化学习便是其中一种被广泛采用的关键技术。强化学习通过设置奖励机制,让模型在不断的试错过程中学习如何更好地生成符合人类期望和实际需求的输出。例如,在文本生成任务中,模型生成的文本如果逻辑连贯、内容准确且符合用户的要求,就会得到较高的奖励。通过这种方式,模型逐渐学会生成更优质的内容,从而提升整体性能。
而在强化学习中,奖励建模是一个极为关键的环节,它直接关系到能否为语言模型生成准确的奖励信号。准确的奖励信号可以引导模型朝着更符合要求的方向进行优化,进而给予相应的奖励,使模型能够不断改进回答策略,提供更优质的服务。目前,通用领域的任务和场景复杂多样,不像一些特定领域(如数学计算、编程任务等)有明确的规则和标准答案。同时,现有的奖励建模方法在输入灵活性和推理时可扩展性方面存在不足,这限制了模型在实际应用中的表现,无法充分利用计算资源提升性能。
针对这些问题,Deepseek联合清华大学研究团队提出了Self-Principled Critique Tuning(SPCT,自原则性批判调优)方法。该方法的基础是点生成式奖励建模(GRM),它在理念和操作方式上与传统方法有着明显区别,尤其是在原则的生成与运用方面进行了重大创新。
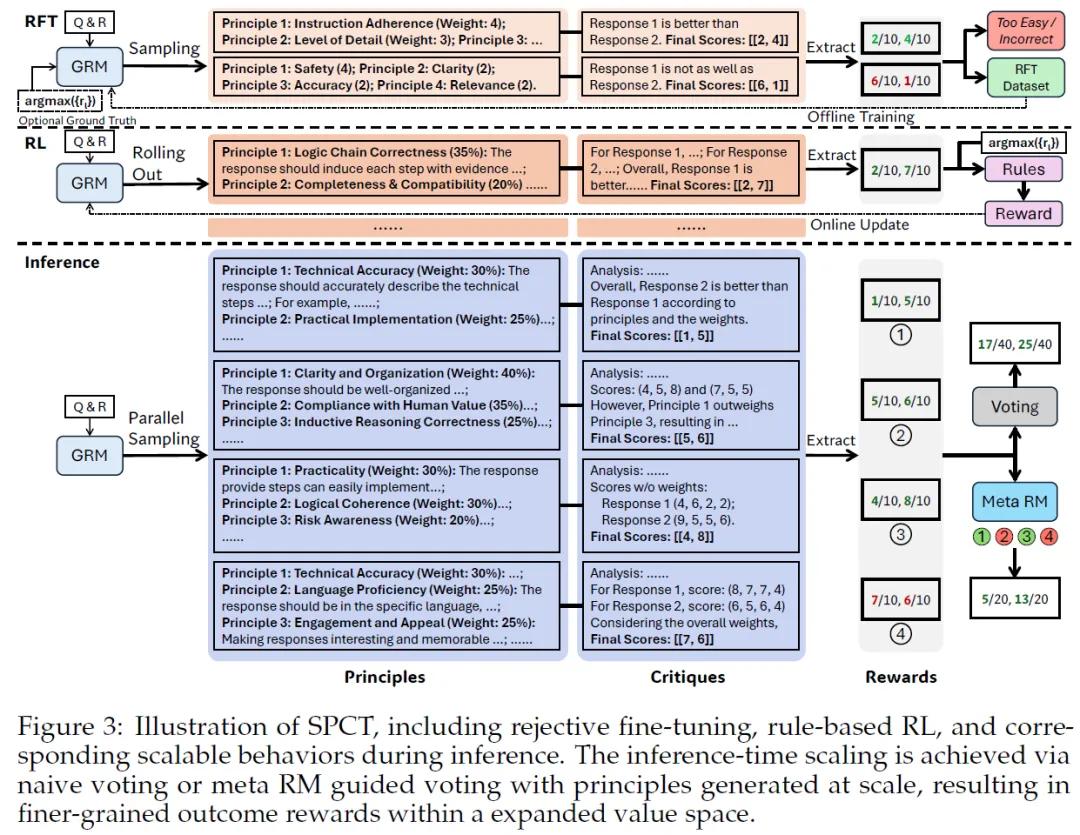
在传统的奖励建模模式中,原则通常被当作预先设定好的固定规则,这些规则一旦确定,在面对各种不同的输入时,往往缺乏足够的灵活性和适应性,而SPCT方法的核心突破,就在于将原则从这种固定、预定义的模式转变为动态生成的过程。在SPCT中,模型不再依赖于预先设定的固定原则,而是能够依据具体输入的查询内容以及相应的响应,实现自适应地生成原则和批评。
这一转变意义重大,它使得奖励生成过程能够紧密贴合多样化的输入。比如在文本创作的奖励建模场景中,当用户输入不同主题、风格要求的文本创作指令时,模型可以根据这些具体的查询,结合生成的不同文本响应,生成与之匹配的原则。如果用户要求创作一篇科技类的文章,模型会生成诸如内容的科学性、前沿性,术语使用的准确性等原则,并依据这些原则对生成的文本进行评估和批评,指出其中存在的问题,像概念错误、表述不够专业等。通过这样的方式,可以显著提升奖励的质量,使得奖励更能准确地反映模型输出的实际价值。
SPCT方法包含两个关键阶段。第一阶段是拒绝微调,作为冷启动步骤,其目的是让GRM适应生成各种输入类型的原则和批评,并确保生成的内容格式正确。研究团队摒弃了以往混合不同格式数据的做法,采用点式GRM,这种方式可以灵活地为任意数量的响应以相同格式生成奖励。第二阶段是规则基在线强化学习。在这一阶段,研究团队使用了“近端策略优化的广义优势估计”(GRPO)的原始设置,并结合基于规则的结果奖励。为了确保生成内容格式正确且避免严重偏差,团队引入了较大的KL散度惩罚系数。如果模型在某一次迭代中生成的内容格式混乱或偏离了合理的范围,较大的KL散度惩罚会使得模型在这次更新中受到较大的惩罚,从而促使模型在后续的学习中更加注重生成内容的质量和合理性。
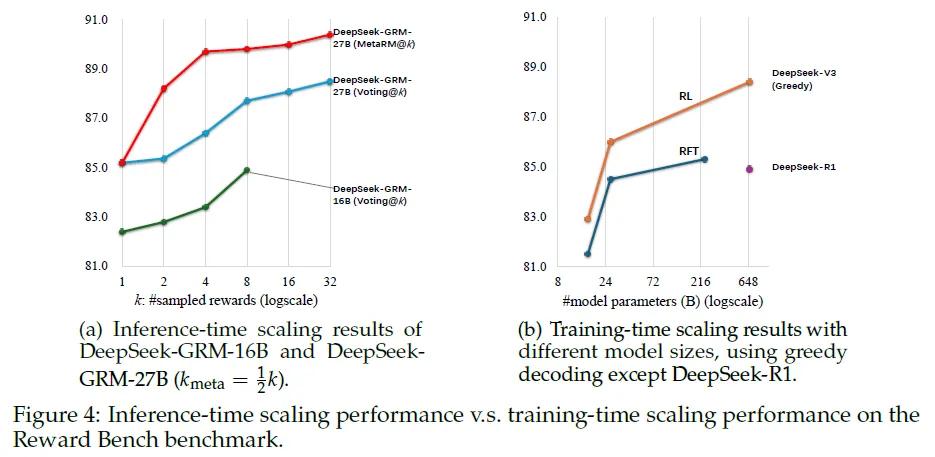
在推理时缩放策略上,团队采用了基于采样的方法:模型会通过并行采样的方式多次生成不同的原则和批评集合,然后对这些结果进行投票,以此得出最终的奖励。这种方式扩展了奖励空间,使得模型能够生成更多的原则,从而更准确地反映真实的判断分布,提高奖励的质量和粒度。为了进一步提升模型性能,研究团队还训练了一个元奖励模型来指导投票过程。在投票时,元奖励模型会为采样得到的奖励输出元奖励,最终的结果由具有较高元奖励的样本投票决定,这样可以有效过滤掉低质量的样本,提升整体性能。这个元奖励模型用于识别DeepSeek-GRM生成的原则和批评的正确性。
研究团队在多个奖励建模基准测试中对不同方法的性能进行了全面评估,涵盖了Reward Bench、PPE、RMB和ReaLMistake等多个不同领域的基准测试。在实验过程中,对于基线方法,研究团队基于Gemma-2-27B进行了重现,并确保所有训练数据和设置与DeepSeek-GRM兼容。对于DeepSeek-GRM-27B模型,团队在不同规模的模型上进行了实验,包括DeepSeek-V2-Lite(16B MoE)、Gemma-2-27B、DeepSeek-V2.5(236B MoE)和DeepSeek-V3(671B MoE)等。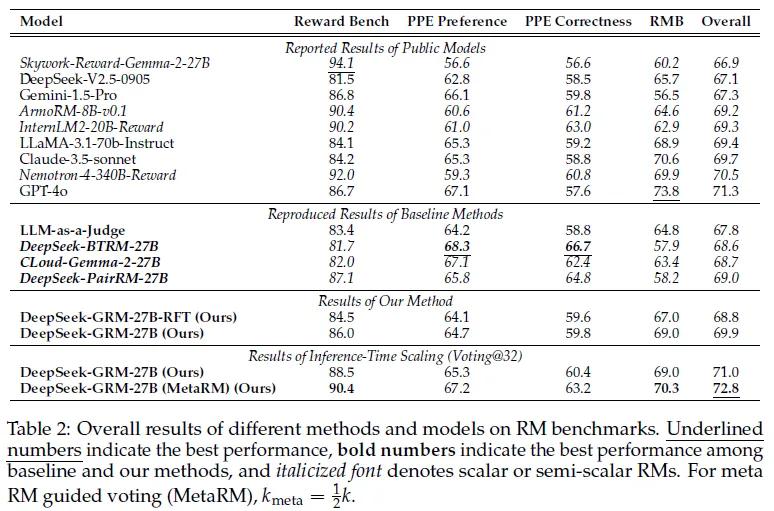
实验结果显示:基于SPCT训练的DeepSeek-GRM-27B模型在整体性能上显著优于基线方法。与强大的公共奖励模型(如Nemotron-4-340B-Reward和GPT-4o)相比,DeepSeek-GRM-27B也展现出了很强的竞争力。在推理时缩放的实验中,随着采样次数的增加,DeepSeek-GRM-27B的性能得到了进一步提升。在使用32次采样时,该模型在一些任务上的表现甚至超过了具有更大参数规模模型的训练时缩放效果,表明SPCT方法不仅提高了GRMs的通用性奖励生成能力,还显著提升了模型在推理时的可扩展性。
此外,研究团队还进行了详细的消融实验,深入验证了SPCT中各个组件的重要性。实验结果表明,原则生成对于模型在贪婪解码和推理时缩放的性能都至关重要,同时,非提示采样在训练过程中比提示采样更为重要,这可能是因为提示采样的轨迹有时会导致生成的批评出现捷径。这些实验结果充分证明了在线训练对于GRMs的重要性,也为后续的研究提供了重要的参考。
参考资料:https://arxiv.org/abs/2504.02495
 豫公网安备41010702003375号
豫公网安备41010702003375号