
阿里开源发布首个用于从首帧到末帧视频生成的14B参数模型:Wan2.1-FLF2V-14B
![]() 前沿资讯
1744966118更新
前沿资讯
1744966118更新
![]() 0
0
自OpenAI推出Sora以来,视频生成领域取得了长足的进步,能够生成专业制作水准视频的模型不断涌现,极大地提高了内容创作效率,同时降低了视频制作成本。然而,不可忽视的是,优秀的开源模型与最新的闭源模型之间仍存在显著差距。
一方面,商业模型凭借强大的资源支持,发展速度远超开源模型,在性能上具有明显优势,另一方面,大多数基础模型局限于通用的文本到视频任务,难以满足视频创作多样化的需求。此外,现有的模型在效率方面也存在不足,对于计算资源有限的创作团队来说,这些模型的实用性大打折扣。这些问题严重制约了开源社区在视频生成领域的进一步发展与创新。在此背景下,阿里巴巴的Wan团队提出并公开了一个高性能的视频生成模型基础——Wan,旨在突破现有困境,为视频生成领域树立新的标杆。
WAN视频模型基于主流的扩散变压器范式打造,在多个关键层面实现了创新突破,进而显著提升了自身的生成能力。该模型具有四大突出特性:
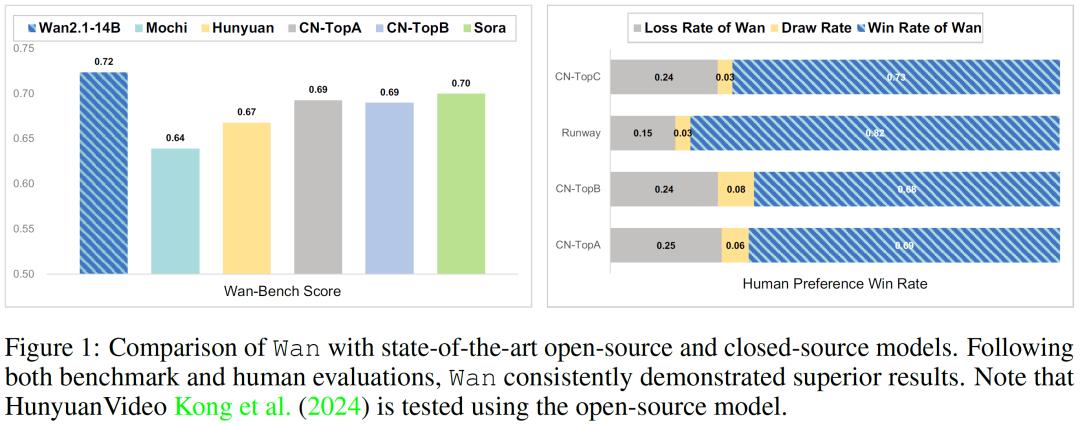
性能卓越:其140亿参数的模型依托由数十亿图像和视频构成的海量数据集进行训练,在众多内部和外部基准测试中,WAN模型的表现持续超越现有的开源模型以及顶尖的商业解决方案,展现出无可比拟的性能优势。
功能完备:WAN模型提供了两种不同参数规模的模型版本,分别是13亿参数和140亿参数,以此满足不同场景下对效率和效果的需求。它涵盖了多种下游应用任务,包括图像转视频、指令引导视频编辑、个人视频生成等多达八项任务。值得一提的是,WAN是业界首个能够生成中英双语视觉文本的模型,这一特性极大地拓宽了其实际应用范围,提升了实用价值。
高效亲民:13亿参数的WAN模型在资源利用效率上表现卓越,仅需8.19GB的VRAM,便能在常见的消费级GPU上流畅运行。在文本转视频任务中,它的表现超越了许多参数规模更大的开源模型,真正做到了高效且亲民。
开源共享:WAN团队秉持开源精神,将整个系列的源代码和所有模型全部开源。
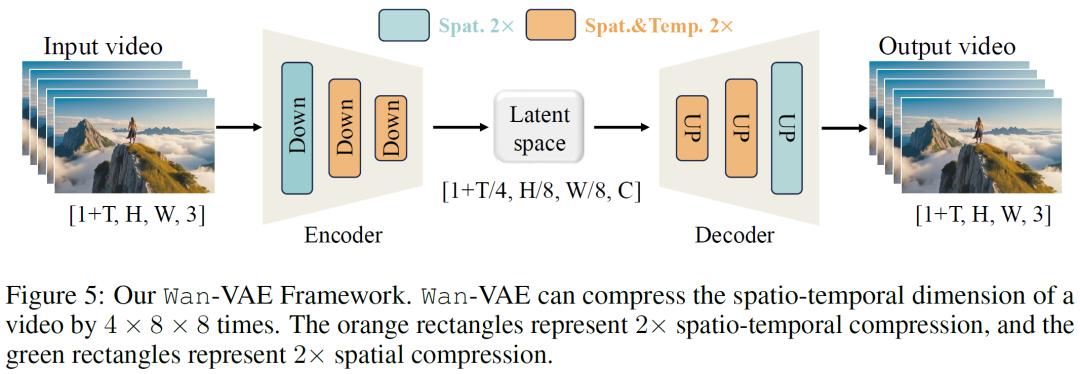
在模型设计上,WAN视频模型采用了全新的时空变分自编码器(VAE),有效应对了视频生成中VAE设计面临的一系列难题。它能够精准捕捉视频中复杂的时空依赖关系,显著降低内存消耗,同时确保时间因果性,保证生成视频的真实性和连贯性。通过严谨的实验对比发现,WAN-VAE在视频重建质量和处理效率方面表现极为出色,其重建速度比现有最先进的方法快2.5倍。此外,WAN模型还对模型训练、加速和推理等环节进行了全方位的优化。
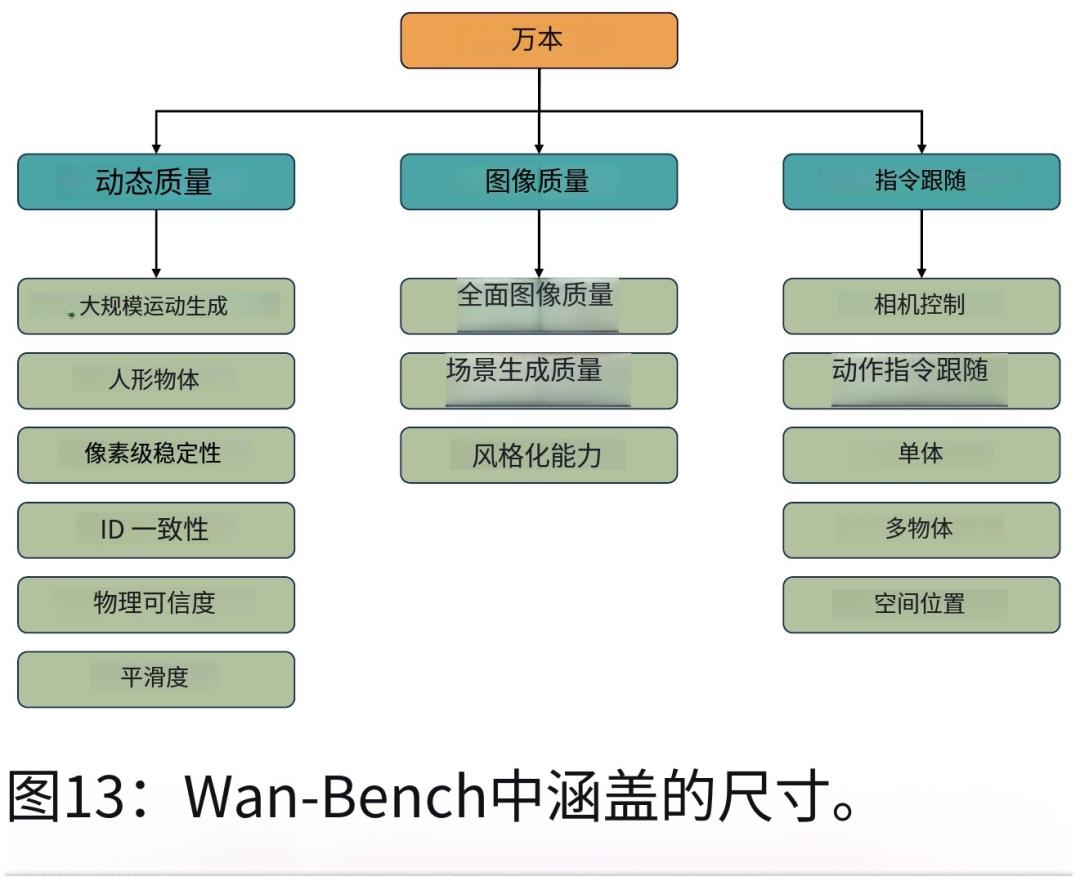
为了科学、全面地评估模型性能,WAN团队创新性地提出了Wan-Bench评估标准。该标准具有自动评估、全面覆盖、符合人类感知等特点,由动态质量、图像质量和指令跟随三个核心维度以及14个细粒度指标组成。在与众多商业和开源模型的对比测试中,WAN模型在各项指标上均表现优异。无论是在动态质量方面,还是在图像质量方面,WAN模型都全面超越了竞争对手。
除了强大的基础模型,WAN在多个扩展应用领域也展现出了巨大的潜力。在图像转视频任务中,WAN-I2V模型能够依据静态图像和文本提示,合成高质量的动态视频。它引入了额外的条件图像作为第一帧来控制视频合成,并采用了独特的掩码机制,使模型能够更好地处理不同的任务需求。在统一视频编辑方面,基于WAN预训练模型构建的VACE框架实现了多种视频编辑和生成任务的统一,通过创新的概念解耦策略和上下文适配器调整策略,提升了模型在处理复杂编辑任务时的能力。此外,WAN在文本转图像、视频个性化、相机运动控制、实时视频生成和音频生成等领域也取得了不俗的成果。
未来发展计划方面,WAN团队表示将通过进一步扩大数据规模、持续优化模型架构等方式,不断提升WAN模型的性能和能力,推动视频生成技术向更高水平迈进。
参考资料:https://arxiv.org/abs/2503.20314
 豫公网安备41010702003375号
豫公网安备41010702003375号