
强化学习提升语言模型推理能力?清华大学LeapLab研究发现:并非如此
![]() 前沿资讯
1745400409更新
前沿资讯
1745400409更新
![]() 0
0
近年来,语言模型发展迅猛,如何进一步提升其推理能力成为科研攻关的关键方向。基于可验证奖励的强化学习(RLVR)技术应运而生,它以预训练的基础模型为起点,通过简单且可自动计算的奖励机制进行强化学习优化,在数学和编程等任务场景中取得了一定成果,因此被不少研究者认为能助力模型获得超越基础模型的推理能力。
然而,清华大学LeapLab、上海交大两机构的研究人员通过一系列严谨的实验对这一论点发起挑战。研究人员采用了一种名为“pass@k”的指标来评估模型的推理能力边界。传统的评估指标,如单轮成功率或平均核采样等,往往只能反映模型的平均表现,容易低估模型的真实推理潜力。而“pass@k”指标让模型进行k次采样,如果其中至少有一次采样结果正确,就认定该问题被解决。通过这种多次采样的方式,能更精准地评估模型的推理能力。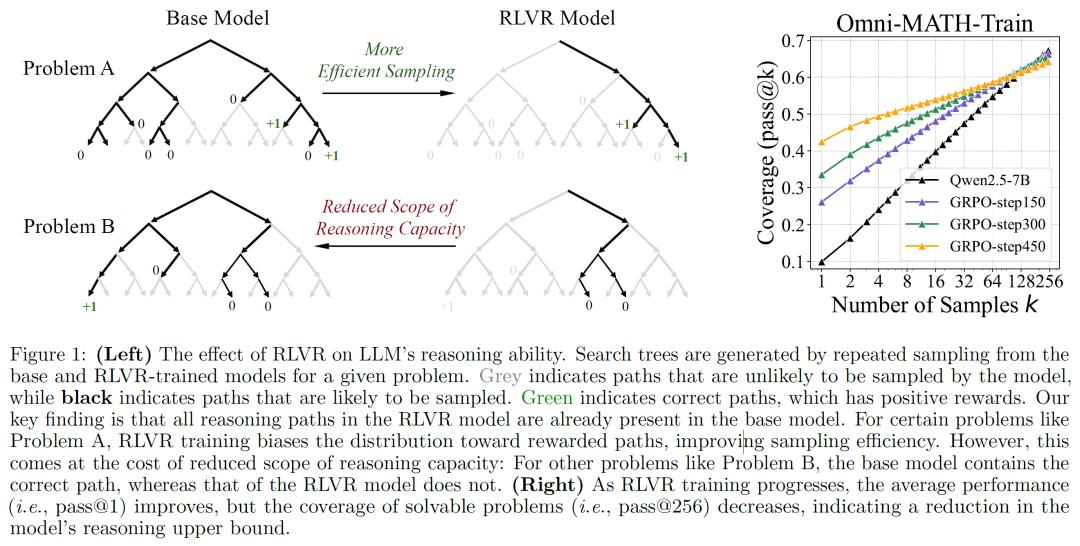
在实验过程中,研究人员对多个不同的语言模型家族展开研究,涵盖了像Qwen-2.5系列、LLaMA-3.1-8B等模型,同时测试了多种强化学习算法,包括近端策略优化(PPO)、分组近端策略优化(GRPO)等,并且选用了丰富的数学和编程基准测试,例如数学领域的GSM8K、MATH500、Minerva、Olympiad、AIME24、AMC23,以及代码生成领域的LiveCodeBenchv5、HumanEval+、MBPP+等。
实验结果令人颇为惊讶:在较大的k值情况下,经过RLVR训练的模型在“pass@k”指标上的表现竟然不如基础模型。这一发现意味着,只要给予基础模型足够多的采样机会,它完全能够解决那些以往被认为只有经过RLVR训练的模型才能处理的难题。以数学推理任务为例,当k值较小时,比如k=1时,RLVR训练的模型确实表现更优,这与过往的一些研究结论相符。
但当k值逐渐增加到几十甚至几百时,情况发生反转,基础模型的表现开始超越RLVR训练的模型。在代码生成任务中,以LiveCodeBench为例,原始模型的pass@1得分是23.8%,RLVR训练后的模型提升到28.1%,然而当采样128次后,原始模型能解决约50%的编码问题,RLVR模型却只能解决42.8%,视觉推理任务同样呈现出类似趋势。
研究人员进一步深入分析,发现RLVR训练虽在一定程度上提高了模型采样正确推理路径的效率,但却导致模型的推理能力范围变窄。这背后的原因在于,RLVR训练使得模型的输出分布过度偏向于能够获得奖励的路径,在提升采样正确路径概率的同时,大大降低了模型的探索能力。与之形成鲜明对比的是,蒸馏方法可以从强大的推理模型中汲取新知识,从而真正为模型引入全新的推理模式,有效扩大模型的推理边界。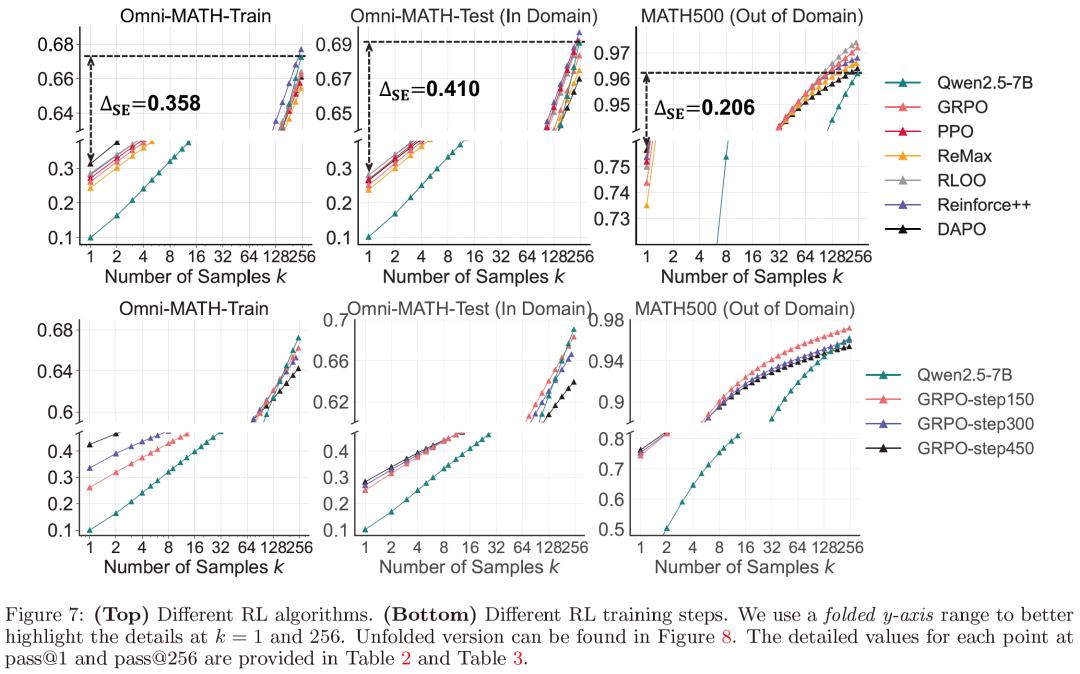
此外,研究团队还对不同的RL算法进行了细致分析。他们重新实现了多种流行的RL算法,如PPO、GRPO、Reinforce++、RLOO、ReMax、DAPO等,并构建了相应的实验数据集进行测试。结果显示,虽然不同算法在性能上存在些许差异,但在提升采样效率方面都远未达到最优。例如,不同算法的采样效率差距在不同数据集上始终较高,表明当前的RL算法在通过提高采样效率来提升模型性能的道路上还有很大的改进空间。
研究人员表示:“我们的研究结果清晰地表明,RLVR在提升大语言模型推理能力方面存在关键限制,它并不能让模型获得超越基础模型的全新推理能力。这一发现将促使整个研究领域重新审视RLVR训练在大语言模型推理中的实际作用,也让我们更加明确寻找更好训练范式的紧迫性。”
参考资料:https://arxiv.org/abs/2504.13837
 豫公网安备41010702003375号
豫公网安备41010702003375号