
清华大学联合上海人工智能实验室发布新型强化学习方法“TTRL”,模型性能狂飙159%
![]() 前沿资讯
1745491843更新
前沿资讯
1745491843更新
![]() 0
0
当下,提升语言模型的推理能力成为一个研究焦点。测试时缩放(TTS)作为新兴趋势,能够比预训练时缩放获得更高的计算效率,但现有基于TTS的方法在处理无标签新数据时仍面临难题。同时,强化学习在增强语言模型长链思维方面虽作用关键,但获取训练所需的真实标签成本高昂,限制了模型的持续学习能力。
在此背景下,清华大学与上海人工智能实验室的研究团队联合发布了一项名为测试时强化学习(Test-Time Reinforcement Learning,TTRL)的创新方法,旨在解决无明确监督情况下的模型训练问题。
TTRL的核心在于利用多数投票策略估算标签并计算奖励,使模型能够在无真实标签的测试数据上进行强化学习。具体而言,给定输入提示x,模型根据参数化策略生成多个候选输出,通过多数投票等聚合方法得到一个共识输出y*,将其作为最优行动的代理。环境依据采样行动y与共识行动y*的一致性提供奖励,模型通过梯度上升更新参数,以最大化期望奖励。在多数投票奖励函数的设计上,先通过多数投票估算标签,再据此计算基于规则的奖励,与共识输出一致的预测得1分,否则得0分。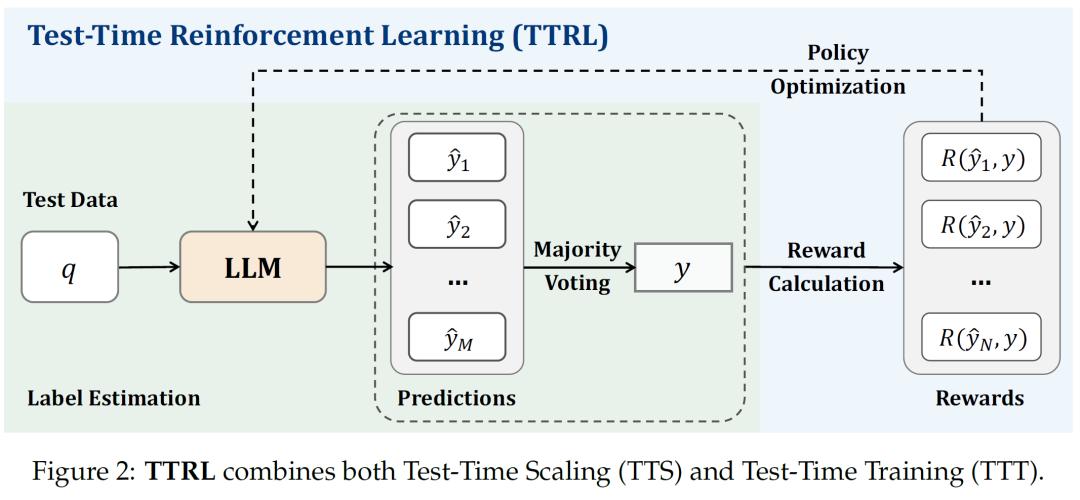
研究人员对TTRL进行了多方面的实验验证。在模型选择上,涵盖了基础模型和指令模型,包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B和LLaMA-3.1-8B-Instruct等。在基准测试中,选用了AIME 2024、AMC和MATH-500等数学推理数据集。
实验结果令人显示:在AIME 2024基准测试中,Qwen2.5-Math-7B应用TTRL后,pass@1性能提升了约159%,在三个基准测试中,该模型平均提升幅度达84.1%。此外,TTRL还展现出良好的扩展性,模型规模越大,性能提升越明显;在跨任务泛化方面表现出色,在不同分布的数据集上也能实现显著性能改进;并且与不同的强化学习算法兼容性良好,如使用PPO算法时能获得更稳定的结果。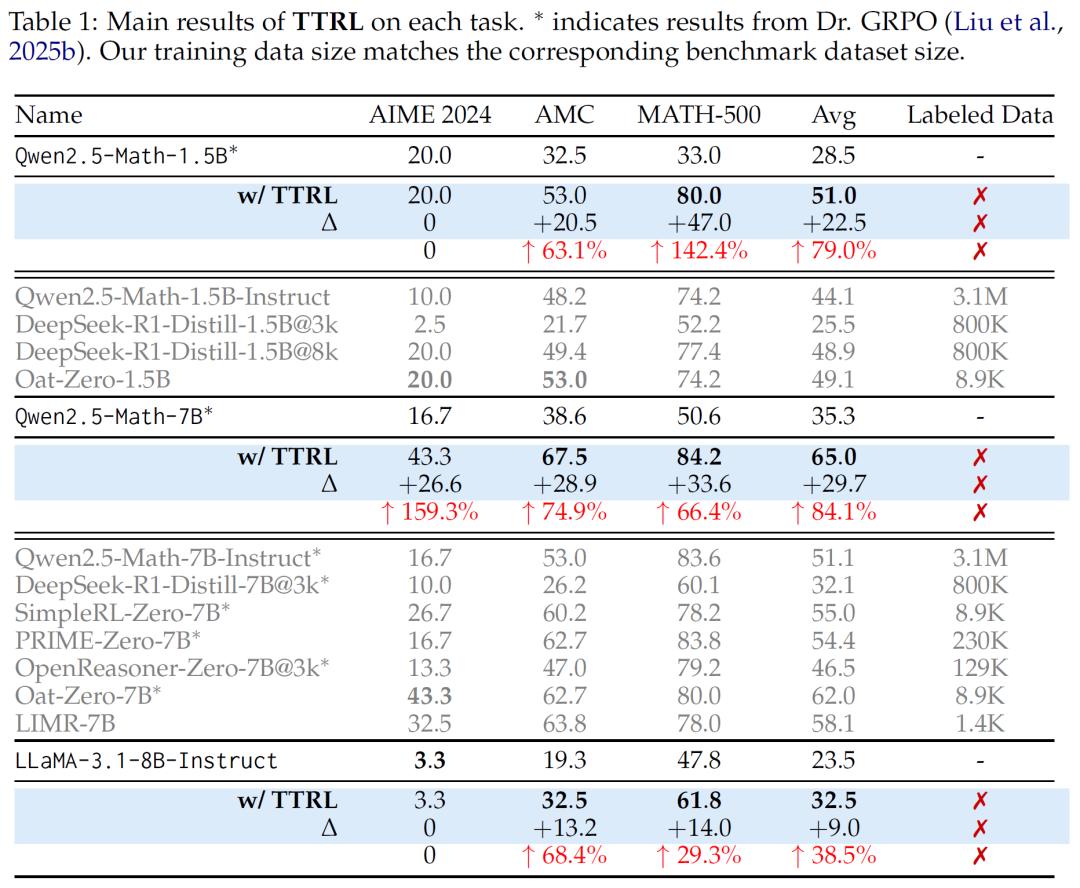
深入分析发现,TTRL不仅超越了初始模型的直观性能上限,还接近使用真实标签在测试数据上直接训练的模型性能。即使标签估计存在不准确的情况,由于强化学习对奖励不准确性的容忍度以及奖励计算的特性,TTRL仍能有效发挥作用。不过,TTRL也存在一定的局限性。当模型对目标任务缺乏先验知识时,可能无法有效学习,如Qwen2.5-Math-1.5B和LLaMA-3.1-8B-Instruct在AIME 2024任务上就未取得明显性能提升,此外,强化学习超参数设置不当也会导致训练失败。
研究团队表示,TTRL是迈向自我标记奖励强化学习的重要一步,为从连续经验流中学习指明了方向。未来,他们计划深入分析先验知识和超参数配置的影响,开展TTRL的理论收敛性分析,将其扩展到实时学习场景,并应用于更复杂的任务和领域,探索在大规模无监督训练中的潜力。
参考资料:https://arxiv.org/abs/2504.16084
 豫公网安备41010702003375号
豫公网安备41010702003375号