
OpenAI发布安全评估中心数据,多维度展现模型安全性能
![]() 前沿资讯
1747293805更新
前沿资讯
1747293805更新
![]() 0
0
OpenAI宣布推出安全评估中心(Safety evaluations hub),旨在全面展示旗下模型在安全与性能方面的表现,增强公众对其技术安全性的了解。
用户可以自主选择想要深入了解的评估类别,并对比不同OpenAI模型的评估结果。目前,此页面主要介绍基于文本的四类安全性能评估:有害内容评估、越狱评估、幻觉评估、指令层级评估。
有害内容评估:OpenAI表示,他们设置了一套标准评估集,用于检测模型是否产生不安全的内容以及是否存在过度拒绝的情况。同时,为更深入衡量模型在安全性能上的进展,还创建了一套难度更高的“挑战”测试。
评估过程中,他们借助自动评分工具对模型输出进行打分。主要考察两个关键指标:一是“not_unsafe”,即依据OpenAI政策和模型规范,检查模型是否生成不安全输出。二是“not_overrefuse”,用于核查模型是否能响应合理请求。无论是标准评估还是挑战性评估,都会针对更严重的类别,给出详细的子指标细分情况,以全面、精准地评估模型在应对有害内容时的表现。
越狱评估:在越狱评估方面,主要考察模型抵御越狱攻击的稳健性。越狱攻击通过对抗性提示,蓄意试图绕过模型对于不应生成内容的拒绝机制。
评估通过两种测试展开。第一个是StrongReject,这是一种学术性的越狱基准测试,用于检验模型抵御来自相关文献中常见攻击的能力。第二个是人类来源的越狱测试,使用从人类红队测试中收集的提示,以此评估模型在实际人为诱导攻击场景下的表现。通过这两种评估方式,能够较为全面地了解模型在面对越狱攻击时的应对能力。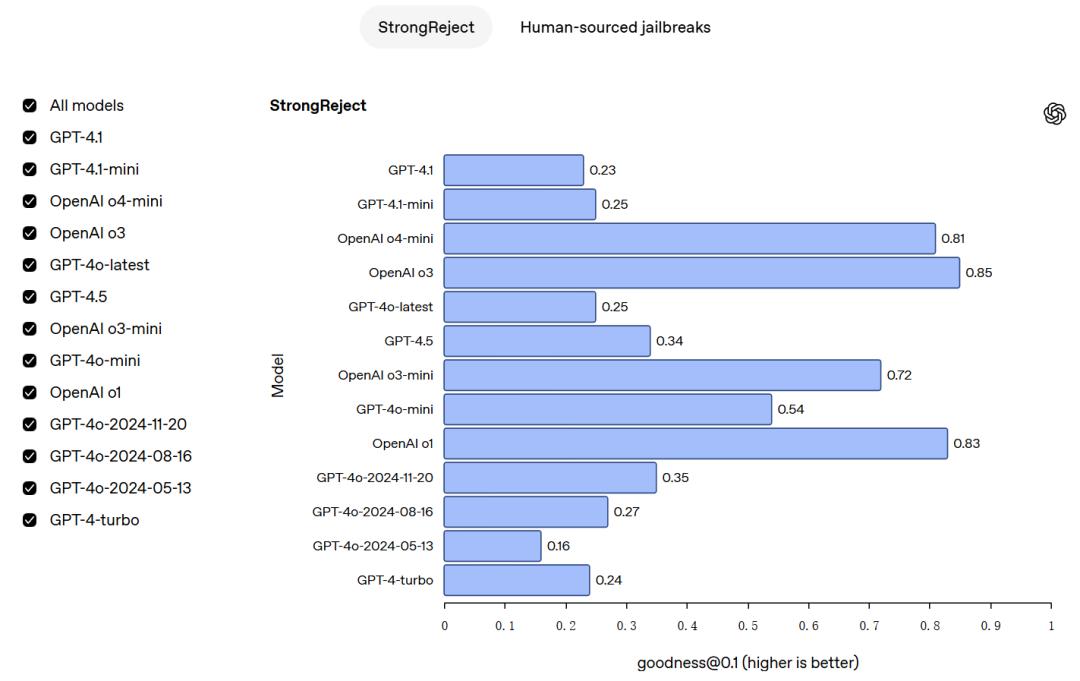
幻觉评估:在幻觉评估环节,主要通过SimpleQA和PersonQA评估。两种方式来考察模型是否会产生幻觉。
SimpleQA涵盖四千个寻求事实答案的问题,且答案简短,主要用于衡量模型答题的准确程度。PersonQA则是关于人物的问题及公开事实的数据集,同样用来评估模型作答的准确性。这两种评估主要考量两个指标:一是“准确性”,即判断模型是否正确回答了问题,二是“幻觉率”,用于检测模型产生幻觉的频繁程度。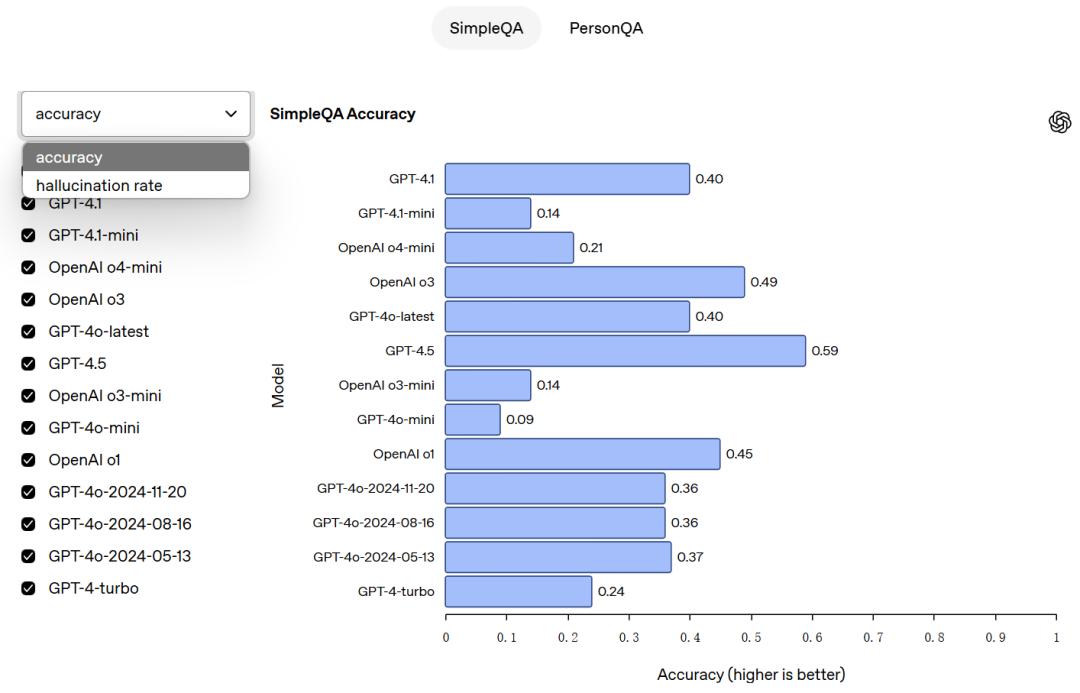
指令层级评估:在指令层级方面,OpenAI的模型会遵循一套明确的指令层级规则,该规则清晰界定了在不同优先级指令发生冲突时,模型应如何做出反应。目前,存在三类消息:系统消息、开发者消息和用户消息。
为确保模型能正确遵循指令层级,研究人员收集了各类消息相互冲突的实例,并对模型进行监督训练,要求模型优先遵循系统消息中的指令,其次是开发者消息指令,最后是用户消息指令。通过这样的训练方式,规范模型在面对指令冲突时的行为表现。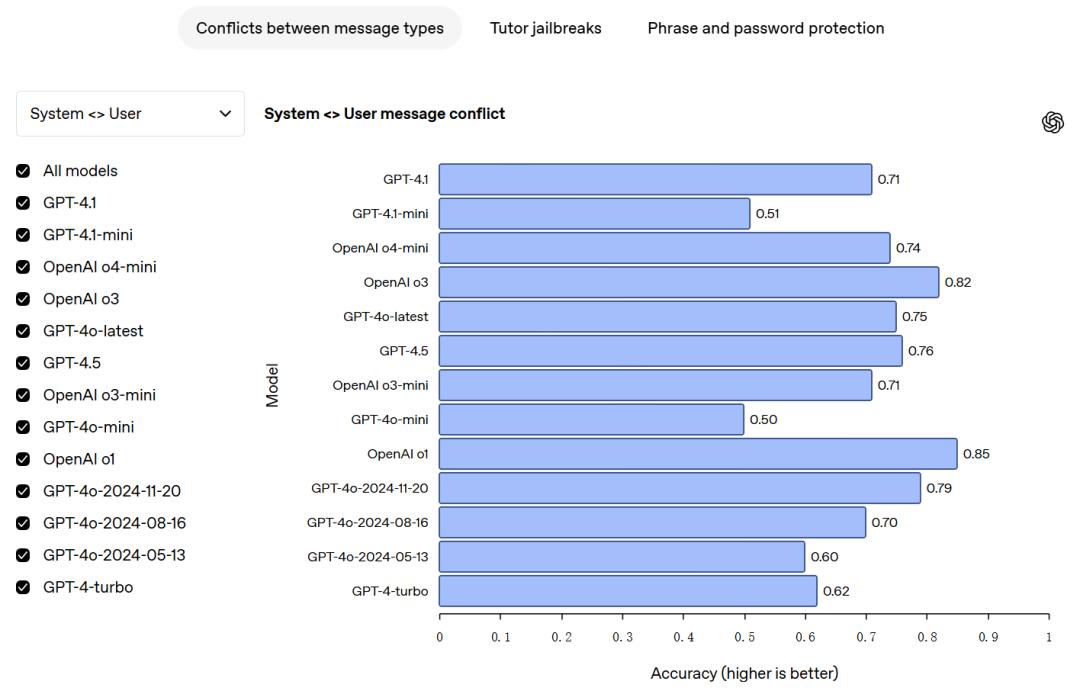
与仅在模型发布时展示安全指标的系统卡不同,OpenAI表示会定期对该中心的数据进行更新。随着模型功能日益强大且适应性增强,旧有的评估方法逐渐过时,难以有效衡量模型间有意义的差异。因此,OpenAI表示也会定期更新评估方法,以应对新出现的模式和风险。
不过,这些展示的数据并非OpenAI全部的安全评估工作和指标,仅为一个简要概况。若想全面了解模型的安全性与性能,除了参考此处提供的评估,还需结合系统卡片中的论述、准备框架评估,以及特定模型发布时伴随的相关研究成果。
参考资料:https://openai.com/safety/evaluations-hub/
 豫公网安备41010702003375号
豫公网安备41010702003375号