
DeepSeek公布最新DeepSeek-V3实践成果,为破解AI规模化难题提供技术范本
![]() 前沿资讯
1747306240更新
前沿资讯
1747306240更新
![]() 0
0
在语言模型加速向通用人工智能(AGI)演进的浪潮中,模型规模的爆炸式增长与硬件架构的固有瓶颈间矛盾日益凸显,成为制约AI系统规模化发展的核心挑战。在这一背景下,DeepSeek-AI公布了最新的DeepSeek-V3实践成果,通过硬件感知的模型协同设计,在内存效率、计算成本与网络架构等维度实现突破性创新,为破解AI规模化难题提供了可落地的技术范本。
DeepSeek-V3的训练依托于2048块英伟达H800 GPU集群,通过模型架构创新与硬件特性深度绑定,实现了资源利用率的最大化。在模型层面,DeepSeek采用多头潜在注意力(MLA)技术压缩键值缓存(KV Cache),使每token的KV缓存占用仅为70KB,相比LLaMA-3.1(405B参数)的516KB和Qwen-2.5(72B参数)的327KB,分别降低了86%和79%,有效缓解了内存墙问题。混合专家(MoE)架构通过选择性激活部分参数,使模型总参数扩展至6710亿的同时,将单token计算成本控制在250 GFLOPS,仅为同规模稠密模型的十分之一左右,大幅降低了训练和推理的计算开销,而且在本地消费级GPU上可实现近20 tokens/秒的生成速度。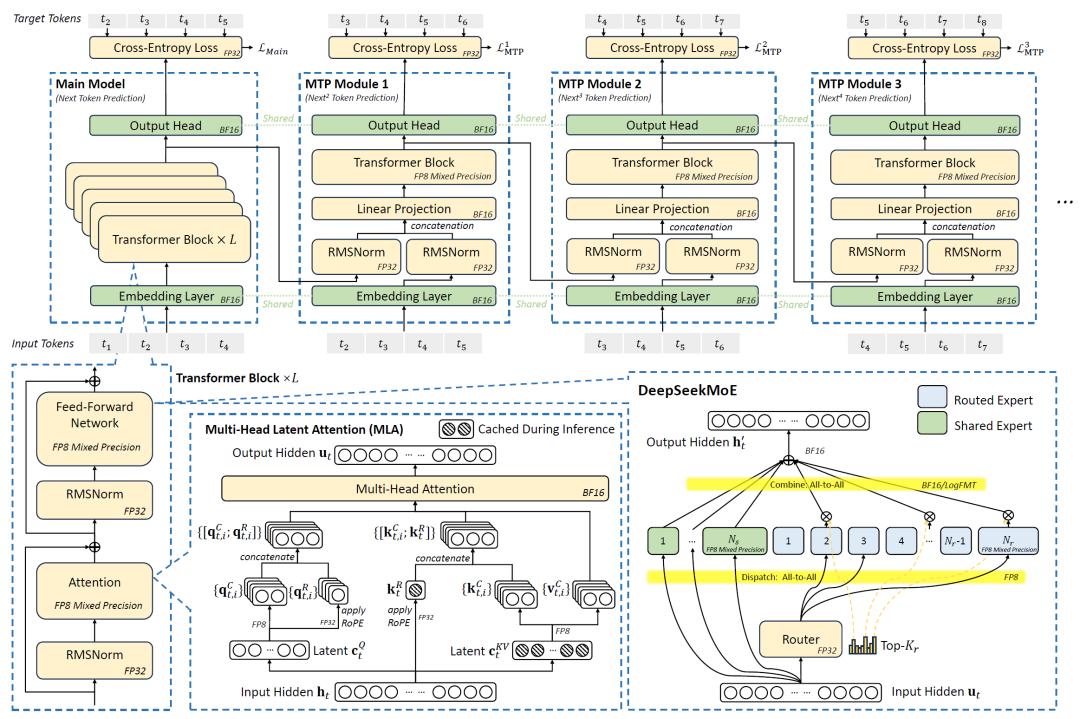
硬件协同设计方面,DeepSeek-V3引入FP8混合精度训练,充分释放硬件计算潜力,结合细粒度量化策略,使模型精度损失控制在0.25%以内,同时成本降低了约50%。网络架构上,采用两层多平面胖树(MPFT)拓扑替代传统三层结构,在保持低延迟的同时,将集群网络成本降低30%以上,并通过节点受限路由策略优化专家并行通信,平衡了节点内(NVLink)与节点间(InfiniBand)的带宽差异,实测显示,该网络在2048 GPU集群上的训练吞吐量与传统架构相当,但硬件成本显著降低。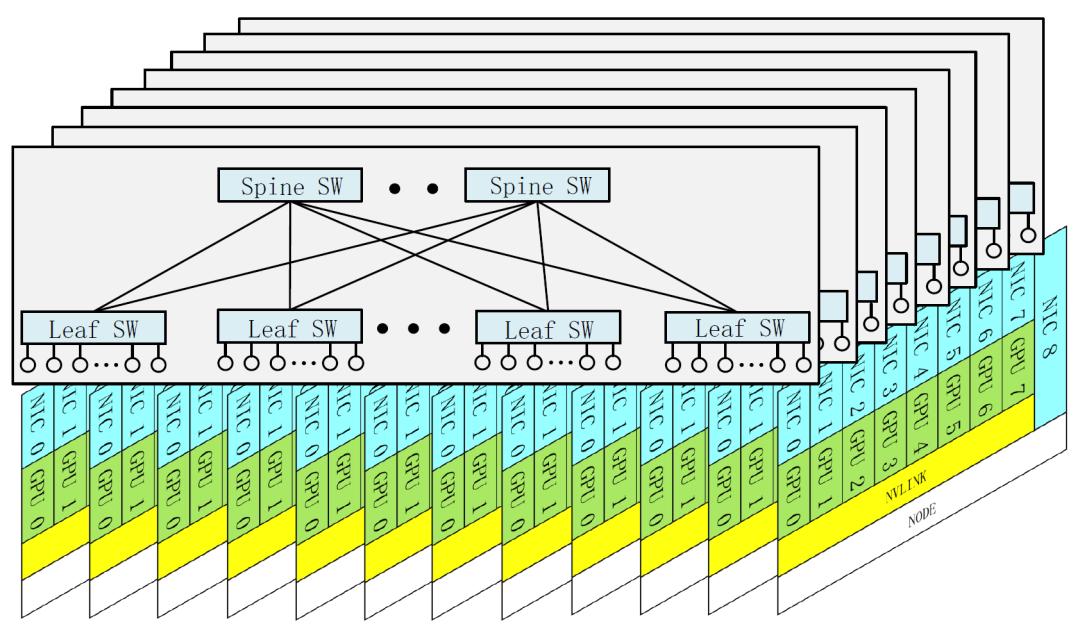
DeepSeek还指出,当前硬件在低精度计算、通信延迟和系统鲁棒性等方面仍存在局限,但通过硬件原生支持细粒度量化、动态带宽分配及智能路由算法,可进一步提升系统效率。例如,采用GB200 NVL72高带宽互联时,理论推理速度可达1200 tokens/秒,较现有架构提升近20倍。
DeepSeek-V3的实践表明,软硬件协同设计是应对AI工作负载规模化挑战的关键。未来,随着精确低精度计算单元、混合互联架构及内存语义通信等技术的成熟,未来AI系统将不再依赖单一维度的硬件升级,而是通过全栈优化实现“算力-成本-性能”的帕累托改进。
参考资料:https://arxiv.org/abs/2505.09343
 豫公网安备41010702003375号
豫公网安备41010702003375号