
麻省理工学院发布Omni-R1,首次证明“仅用文本数据”微调即可显著提升音频问答性能
![]() 前沿资讯
1747385863更新
前沿资讯
1747385863更新
![]() 0
0
麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)与 IBM 研究院的研究团队联合发布了全新音频大语言模型 Omni-R1。该模型通过创新的强化学习方法与数据生成技术,首次证明“仅用文本数据微调”即可显著提升音频问答性能,为低成本构建音频模型提供了新思路。
研究中,最重要的发现便是文本推理能力对音频任务的关键作用。该团队通过实验证明,即使完全移除音频输入,仅使用文本数据对模型进行微调,依然能显著提升音频问答性能。
Qwen2.5-Omni 在纯文本科学问答数据集 ARC-Easy 上微调后,其音频问答准确率从 65.9% 提升至 68.2%,接近使用原始音频数据微调的 68.6%。表明多模态模型的底层文本知识储备是音频理解的核心基础,强化学习优化的文本推理能力可直接转化为音频任务的性能提升,而非依赖对音频信号的直接处理。
为解决传统音频数据集人工标注成本高、规模受限的问题,研究团队提出利用 ChatGPT 自动生成音频问答数据的方法。他们先通过 Qwen-2 Audio 模型为 AVQA 和 VGGSound 等音频数据集生成文本字幕,随后基于字幕提示使用 ChatGPT 生成问题及选项,最终形成了包含 4 万样本的 AVQA-GPT 和 5.4 万样本的 VGGS-GPT 数据集。实验显示,基于 VGGS-GPT 的 Omni-R1 在 MMAU 测试中实现了更高的准确率,使用自动生成数据微调的模型性能优于人类标注数据。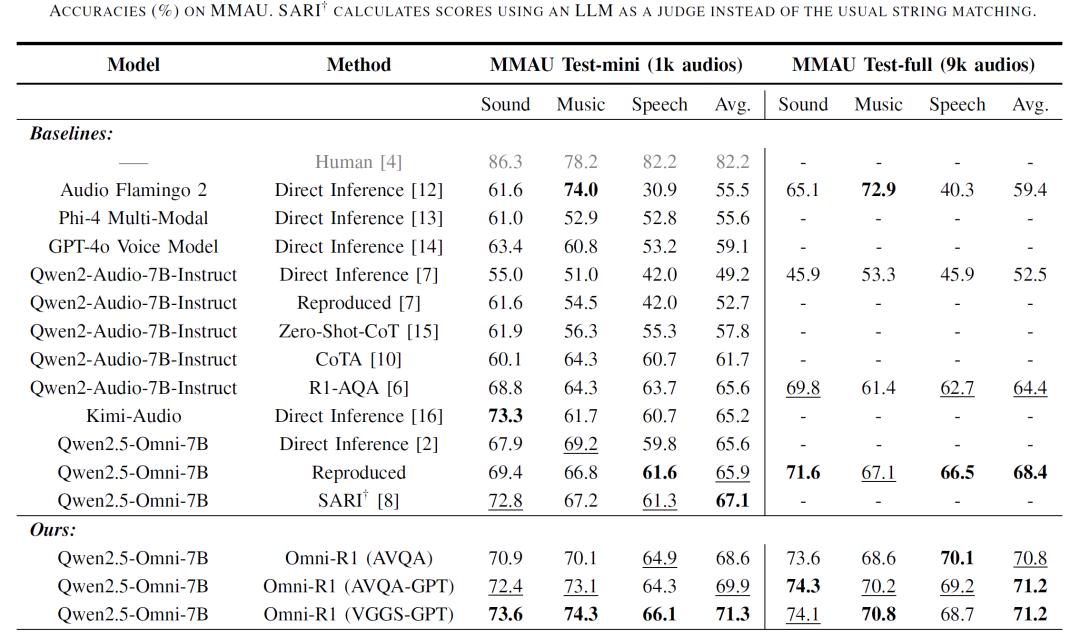
在训练框架设计上,研究团队采用极简提示策略 “<问题> 请从以下选项中选择答案:< 选项 >”,使模型无需生成复杂的思维链,直接输出答案选项。这一设计将 GPU 内存需求降至 48GB,较同类需 80GB 显存的方法,优化显著。通过对比实验,研究团队进一步揭示了强化学习 GRPO 方法的作用机制。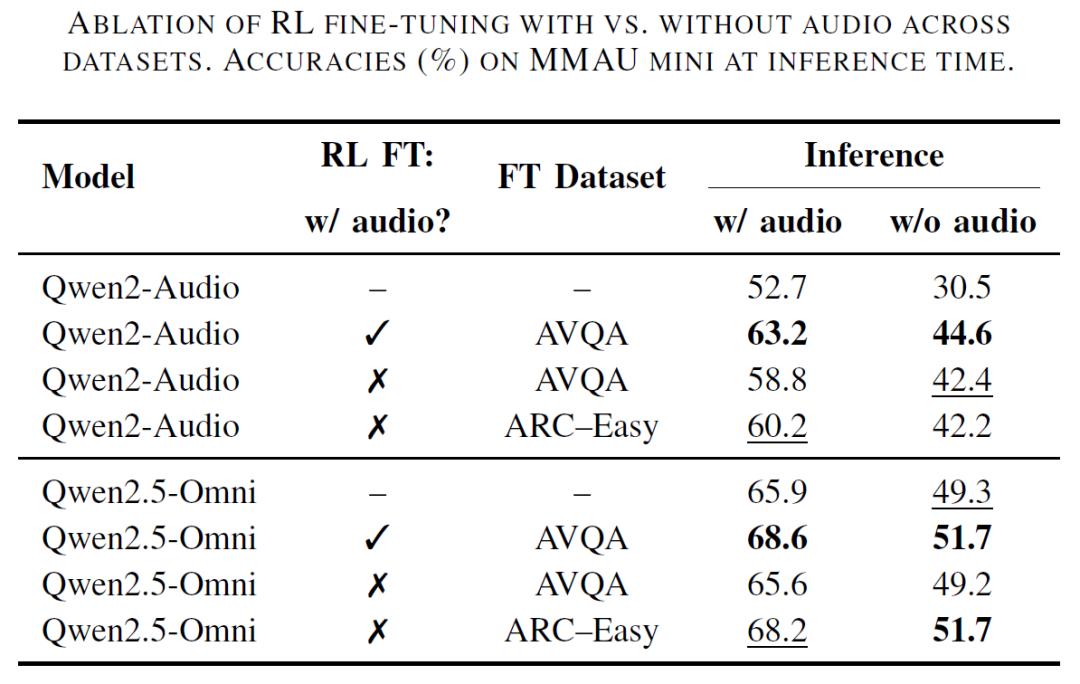
文本推理能力的提升是性能优化的核心: Qwen2-Audio 模型在 GRPO 微调后,无音频输入时的文本推理准确率从 30.5% 提升至 44.6%,带动音频问答准确率提升 12.9%,而对于本身具备较强文本基础的 Qwen2.5-Omni 模型,GRPO 对文本推理的提升幅度较小(49.3%→51.7%),音频任务的准确率提升也相应有限(65.9%→68.6%),印证了文本推理能力对模型表现的决定性影响。
该研究不仅为音频大语言模型提供了无需依赖音频数据的高效训练范式,还通过自动数据生成技术降低了数据采集成本,为智能语音助手、音频内容分析等实际应用场景提供了新路径。研究团队计划公开代码、模型及数据集,推动该领域的产学研合作,为未来跨模态学习的发展提供了重要理论与方法参考。
参考资料:https://arxiv.org/abs/2505.09439
 豫公网安备41010702003375号
豫公网安备41010702003375号