
字节跳动Seed团队提出DanceGRPO,首次将强化学习中的GRPO技术引入视觉生成领域
![]() 前沿资讯
1747734200更新
前沿资讯
1747734200更新
![]() 0
0
近年来,以扩散模型和整流流模型为代表的生成模型在视觉内容创作领域取得了革命性突破。扩散模型如StableDiffusion通过迭代去噪过程生成高保真图像,整流流模型如FLUX则通过线性插值和向量场建模实现高效生成,两者均显著提升了图像与视频生成的质量和多样性。然而,这些模型在预训练阶段虽能捕捉基础数据分布,但如何将模型输出与人类偏好、审美标准及语义需求对齐成为关键瓶颈。
针对这个问题,现有的基于强化学习(RL)的对齐方法存在三大局限:与现代采样范式不兼容;大规模训练不稳定;缺乏对文本到视频、图像到视频等复杂任务的有效支持,限制了其在更广泛场景中的应用。组相对策略优化(GRPO)是近期一种取得突破的强化学习技术,该技术通过分组样本的相对奖励比较,有效提升了模型在数学推理、代码生成等复杂任务中的稳定性和泛化能力。受此启发,有研究人员试图将GRPO引入视觉生成领域,但面临以下适配难题:
理论框架差异:语言模型的离散token序列与视觉模型的连续像素空间本质不同,需重新设计状态空间、动作空间和奖励函数。
生成范式统一:扩散模型和整流流模型的采样机制差异显著(前者基于噪声逐步退火,后者基于线性插值),需找到统一的数学表达以支持GRPO的随机优化框架。
多模态奖励整合:视觉生成需融合美学评分(如HPS-v2.1)、语义对齐(CLIP分数)、视频运动质量(VideoAlign)等多维度奖励,而传统GRPO仅支持单一奖励信号。
针对此痛点,字节跳动旗下的Seed团队联合香港大学联合构建了一个统一的强化学习框架DanceGRPO,首次将强化学习中的组相对策略优化(GRPO)引入视觉生成领域。
DanceGRPO的核心是通过随机微分方程(SDE)重新构建扩散模型和整流流的采样过程,将它们统一成“马尔可夫决策过程(MDP)”。这就好比给不同类型的车辆设计了一个通用的导航系统,让它们能在同一个框架下运行。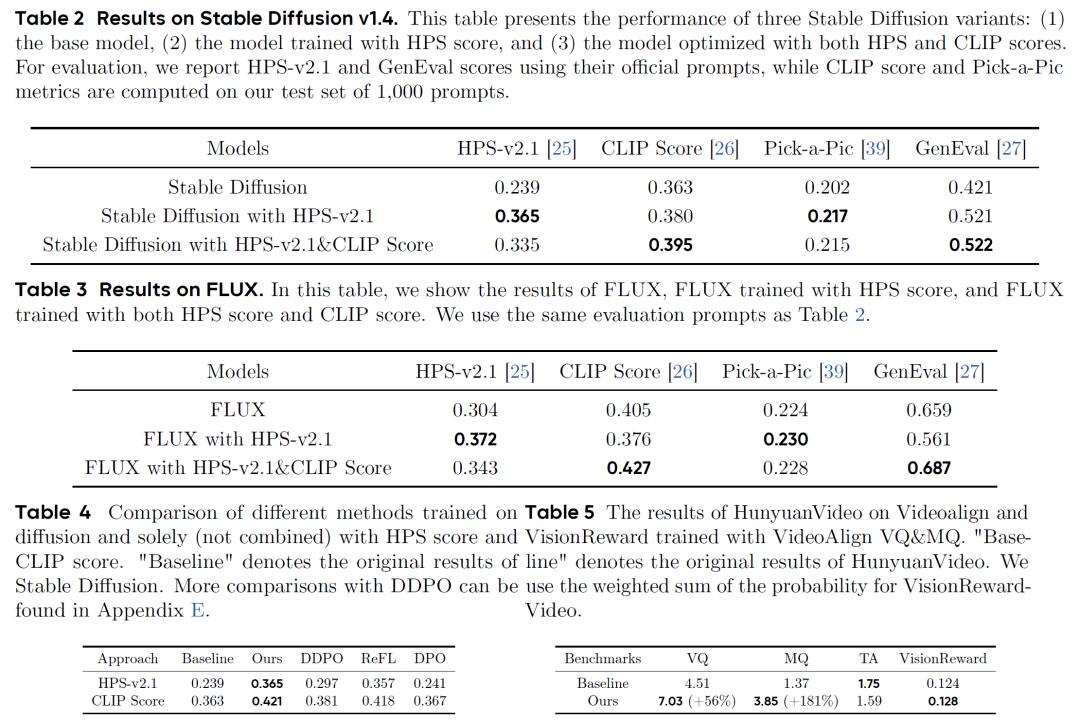
三大关键技术创新细节
(一)共享噪声策略:让训练更“稳”
在传统方法中,给同一个文本提示生成不同样本时使用不同的初始噪声,容易导致模型“钻空子”,通过生成不符合逻辑但能获得高评分的内容来“欺骗”奖励机制(即“奖励hacking”)。DanceGRPO通过给同提示样本分配共享初始化噪声,强制模型在相同噪声基础上优化生成质量,就像让学生在相同试题下比拼解题能力,有效抑制了这种投机行为。实验显示,在HunyuanVideo模型上,该策略使训练稳定性提升40%,视频运动质量评分从1.37跃升至3.85。
(二)多奖励“混合双打”:让生成更“准”
单一奖励模型容易导致生成偏差。DanceGRPO通过聚合多奖励的优势函数,而非直接相加奖励值,平衡了不同维度的优化目标。具体来说,它先对每个奖励模型的分数进行标准化,再将它们线性组合,使模型既能捕捉“画面好不好看”,又能确保“内容对不对题”。实验中,融合HPS和CLIP评分后,StableDiffusion生成图像的CLIP评分从0.380提升至0.395,同时避免了美学评分的下降。
(三)Best-of-N采样:让训练更“快”
在模型训练中,并不是所有生成样本都同等重要。DanceGRPO提出的Best-of-N推理缩放策略,会从每个提示生成的N个样本中筛选出前k个高奖励样本和后k个低奖励样本,仅用这些关键样本进行训练。实验表明,这种策略使StableDiffusion的训练收敛速度提升30%,同时保持相同的性能提升幅度。
DanceGRPO为视觉生成任务提供了首个兼具通用性与高效性的强化学习框架,不仅为文本到图像、视频生成等现有应用场景提供了更贴合人类偏好的解决方案。研究团队表示计划将GRPO技术扩展至多模态生成领域,深入探索其在跨语言、跨媒介内容创作中的潜力。
参考资料:https://arxiv.org/abs/2505.07818
 豫公网安备41010702003375号
豫公网安备41010702003375号