
清华大学提出AdaptThink,可让推理模型根据问题难度自适应选择“思考深度”
![]() 前沿资讯
1747910945更新
前沿资讯
1747910945更新
![]() 0
0
当前主流推理模型通过“深度思考”功能显著提升了推理能力,但也带来了高昂的推理成本与延迟。尤其在处理简单问题时,这些模型总会生成冗长的思考步骤,导致用户体验下降。如何让模型“聪明地”判断何时需要深度思考、何时可直接解答,成为亟待解决的关键问题。
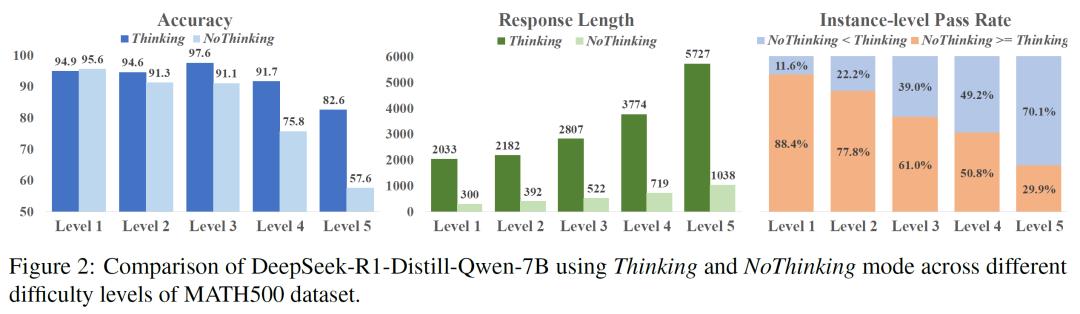
清华大学团队通过实验发现,对于相对简单的任务,一种名为“NoThinking”(无需思考)的模式通过提示模型跳过深度思考、直接生成最终答案,不仅能节省70%以上的tokens使用量,还能在部分场景下提升准确性。在MATH500数据集测试中,当使用NoThinking模式处理最简单的Level 1问题时,模型准确率(97.6%)甚至略高于传统深度思考模式(94.9%),且响应长度从5727 tokens骤降至2033 tokens,表明传统模型在简单问题上的“过度思考”不仅低效,还可能引入不必要的复杂性。
基于上述发现,该团队提出一个名为AdaptThink的算法,其核心目标是教会推理模型根据问题难度自适应选择“深度思考”或“直接解答”模式,实现效率与性能的平衡。
该算法包含两大创新组件:一是约束优化目标,通过设计带约束的优化目标,算法在最大化NoThinking模式使用率的同时,确保模型整体准确率不低于原始水平。二是重要性采样策略,为解决模型初始阶段仅能生成深度思考样本的“冷启动”问题,算法引入重要性采样策略,在训练中强制平衡两种模式的样本比例(各占50%),使得模型从训练初期就能接触到NoThinking样本,逐步学会根据问题特征动态选择最优模式。
在三大数学数据集(GSM8K、MATH500、AIME2024)上的实验表明,AdaptThink实现了“效率提升+性能优化”的双重突破。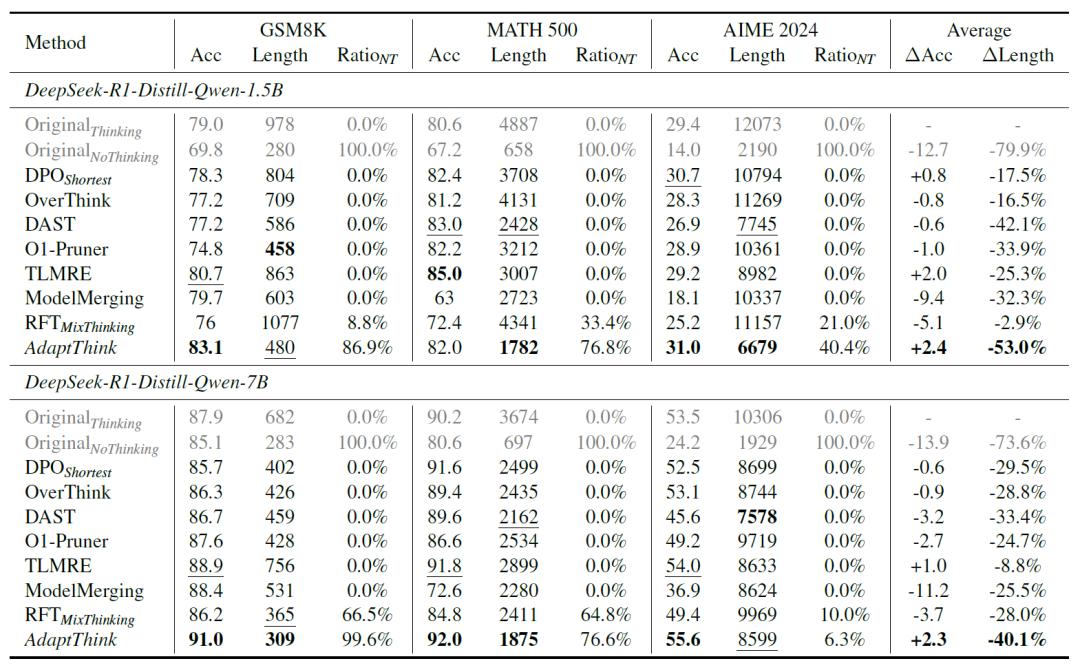
以DeepSeek-R1-Distill-Qwen-1.5B模型为例,平均响应长度减少53%,其中GSM8K数据集从978tokens降至480 tokens,MATH500从4887 tokens降至1782 tokens。在减少计算量的同时,模型准确率平均提升2.4%。比如,GSM8K准确率从79.0%提升至83.1%,AIME2024(高难度奥数题)准确率从29.4%提升至31.0%。此外,模型在简单数据集(如GSM8K)上86.9%的情况选择NoThinking模式,而在高难度的AIME2024中仅40.4%使用该模式,体现了对该技术能够对问题复杂度进行精准判断。在跨领域测试(MMLU多学科数据集)中,AdaptThink同样表现出色,响应长度减少30%以上,准确率提升0.2%-6.5%,证明其具备良好的泛化能力。
AdaptThink标志着推理模型从“一刀切”的固定思考模式向“智能化自适应”的重要转变。通过模拟人类在不同任务中的思维策略,该算法为降低大模型推理成本、提升实际应用中的响应效率提供了可行路径。研究团队表示,未来将进一步拓展算法在多模态推理、通用领域任务中的应用,并探索更大规模模型的优化潜力。
参考资料:https://arxiv.org/abs/2505.13417
 豫公网安备41010702003375号
豫公网安备41010702003375号