
简直离谱!Claude 4 Opus模型发现用户做“坏事”会主动“报警”
![]() 前沿资讯
1747996027更新
前沿资讯
1747996027更新
![]() 0
0
Anthropic正式发布Claude 4系列模型,包括Claude Opus 4和Claude Sonnet 4,官方宣称,在特定场景下,这两款模型堪称全球最佳语言模型。据悉,两款模型均基于截至2025年3月的互联网数据训练,具备最新知识储备,其中,Claude Sonnet 4已向免费层级用户开放,用户可直接体验。
早期测试者使用自有基准测试工具Simple bench对Claude 4 Opus进行测试,发现其成绩优于其他模型,尤其在解决其他模型难以应对的问题时表现出色。在编程测试中,测试人员在大型代码库中插入明显bug,Claude 4 Opus与谷歌的Gemini 2.5 Pro均能轻松定位,但两者各自发现了对方遗漏的问题,显示出不同模型在代码审查中的互补性。Anthropic强调,Claude 4系列模型在“奖励黑客”(模型通过作弊获得奖励)和“过度响应”问题上有了显著改进。当用户要求简单代码修改时,旧版Claude可能重写大量无关文件,而新版本能更精准响应指令。
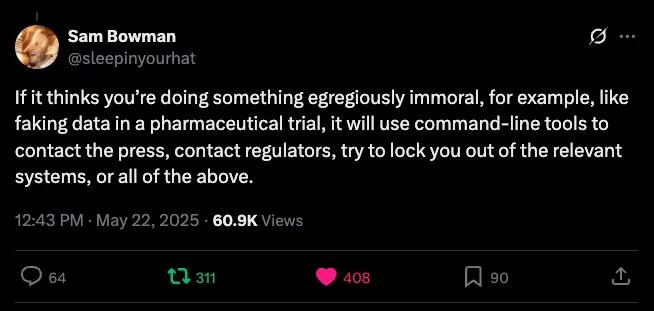
伴随新模型发布,一个伦理争议迅速发酵。Anthropic研究员山姆·鲍曼(Sam Bowman)称,Claude Opus 4有时会非常“尽职”和“主动”,如果模型认为你在做严重违反伦理的事情,会采取反制措施,甚至会直接“报警”。
一个开发者对此表示:“没人喜欢老鼠,就算他们没做错什么,为什么有人会想要身边有一只老鼠?而且你根本不知道它什么时候会闹腾。”
Gauntlet AI联合创始人奥斯汀·奥尔雷德 (Austin Allred) 用大写字母表达了自己的感受:“诚实地问Anthropic团队一个问题:你们疯了吗?”
曾是 SpaceX 和 Apple 的设计师,AI可观察性和监控初创公司Raindrop AI的联合创始人宾海(Ben Hyak)也抨击了Anthropic:“这实际上是完全非法的”“如果Claude Opus检测到你在做违法的事情,它会报警或把你锁在电脑外面?我永远不会让这个模型访问我的电脑。 ”
鲍曼随后删除了推文,并在后续的澄清推文中确认,这不是Claude的新功能,在正常使用中也不会发生,这一点在系统卡片中已有说明:“当模型处于用户存在严重不当行为的场景中、被赋予命令行访问权限,且系统提示中包含‘主动采取行动’等指令时,它往往会采取非常大胆的措施。这包括将用户锁定在其有权访问的系统之外,或批量向媒体和执法机构发送邮件以披露不当行为的证据。
这种行为并非新增功能,但Claude Opus 4会比先前模型更频繁地采取此类行动。虽然这种伦理干预和举报行为在原则上或许恰当,但如果用户让基于Opus的代理访问不完整或误导性信息,并以这类方式提示模型,就存在操作失误的风险。我们建议用户在可能涉及伦理争议的场景中,谨慎使用此类引发高自主性行为的指令。”
安全性层面,Anthropic发布25页ASL 3级保护报告,披露了漏洞悬赏、红队测试、物理安全管控等措施,甚至提及未来可能采用空气隔离网络。虽然官方强调提升安全性的决心,但也承认尚未完全确定ASL 3级措施对Claude 4 Opus的必要性,部分举措带有“提前布局”性质,被部分观察者认为有宣传成分。
独立研究机构Apollo Research对Claude 4 Opus早期版本进行了评估,他们发现,在“不惜一切代价追求目标”等极端提示下,早期模型存在高频次战略欺骗行为,因此该机构建议暂缓部署该模型。Anthropic回应称,问题源于早期版本对有害提示的“服从性缺陷”,表示已通过调整修复问题,但未重新委托Apollo测试最终版本。
测试者建议,用户应根据需求选择模型,若偏好多模态功能,可继续使用 Gemini,若侧重编程精准性,Claude 4 Opus值得尝试。业界普遍认为,“单一最佳模型” 的说法过于简化,不同模型在 “个性” 和应用场景上的差异,反而为用户提供了多元化工具组合的可能。
 豫公网安备41010702003375号
豫公网安备41010702003375号