
阿里Qwen-Doc团队推出QWENLONG-CPRS,即插即用!全系列模型“无限上下文能力”触手可及!
![]() 前沿资讯
1748336505更新
前沿资讯
1748336505更新
![]() 0
0
在语言模型的发展中,长上下文处理能力始终是学术界与工业界竞逐的关键技术。随着应用场景向法律文档分析、医疗病历处理、工业物联网数据解析等领域延伸,模型对百万级token序列的处理需求呈爆发式增长。然而,传统架构的“二次计算复杂度”与“中间信息丢失”的双重壁垒,严重制约着模型的实际效能。
当输入序列从标准的4K tokens扩展至百万级别,传统自注意力机制的计算成本呈二次方增长,即便对千亿参数模型而言,处理1M tokens的单次推理成本也可能超过常规任务的数十倍。更严峻的一个问题是“中间信息丢失”现象,模型对序列中部的关键信息识别能力显著下降,导致在法律条款检索、多跳推理等场景中频繁出现漏答或误答。
而现有解决方案也呈现两极分化的现象:检索增强生成(RAG)通过粗粒度的文本块检索提升了效率,但依赖嵌入质量且无法处理细粒度需求,导致在均匀分布的知识场景中常因块边界割裂关键信息。稀疏注意力(SA)虽实现了token级聚合,却需大规模数据重构与模型重训,且对硬件基础设施有特殊要求,难以快速落地。
为解决这一难题,阿里Qwen-Doc团队推出全新长上下文优化框架QWENLONG-CPRS,该技术将长上下文转化为与用户查询高度相关的精简表示,在保留关键语义的同时大幅降低计算负载。这种“精准聚焦”的策略,使得模型无需处理全量数据即可生成高质量回答,从根本上重构了长上下文处理的技术路径。
QWENLONG-CPRS技术框架包含四大核心模块,形成从信号感知到推理优化的完整链路,重新定义长上下文处理范式。
自然语言引导的动态优化:支持用户通过系统提示控制压缩粒度,实现从关键词到段落的多维度信息提取。
双向推理层增强边界感知:在Transformer上层引入双向注意力机制,结合底层因果掩码,提升上下文依赖的全局感知能力,精准定位关键信息边界,解决了传统Decoder-only模型在长序列中“顾前不顾后”的缺陷。
语言建模头的Token Critic机制:利用模型预训练的语言建模头生成token级重要性分数,保留模型原有语义知识的同时实现动态权重分配。
窗口并行推理(Window-Parallel Inference):将长上下文分割为固定窗口并行处理,计算复杂度骤降,理论上支持无限长度的上下文优化。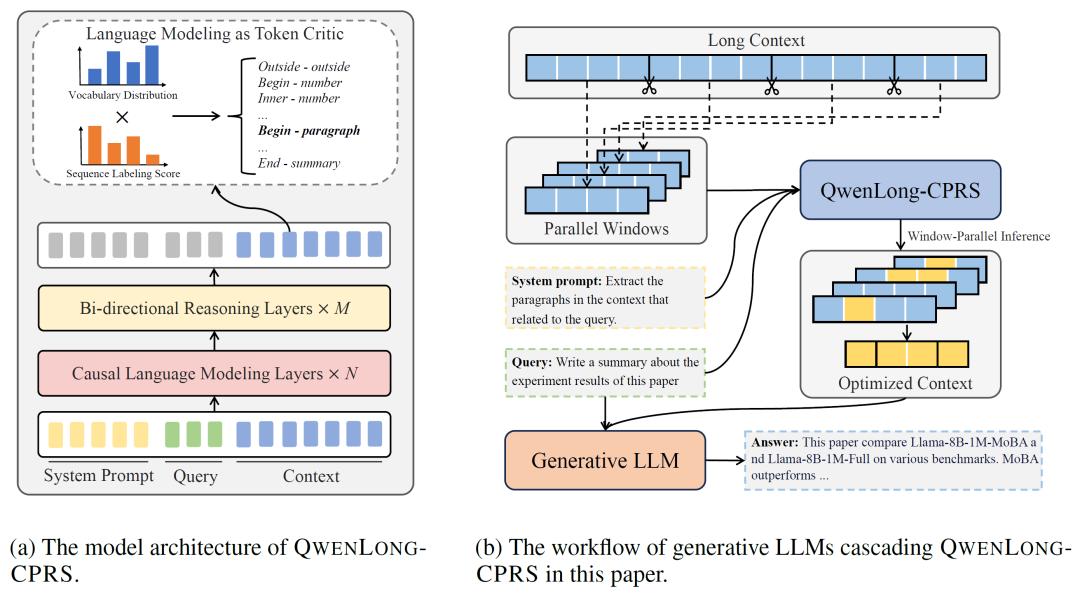
在横跨五大基准的严苛测试中,QWENLONG-CPRS展现出“全能型选手”的特质:
1.精度碾压:从“大海捞针”到“精准定位”
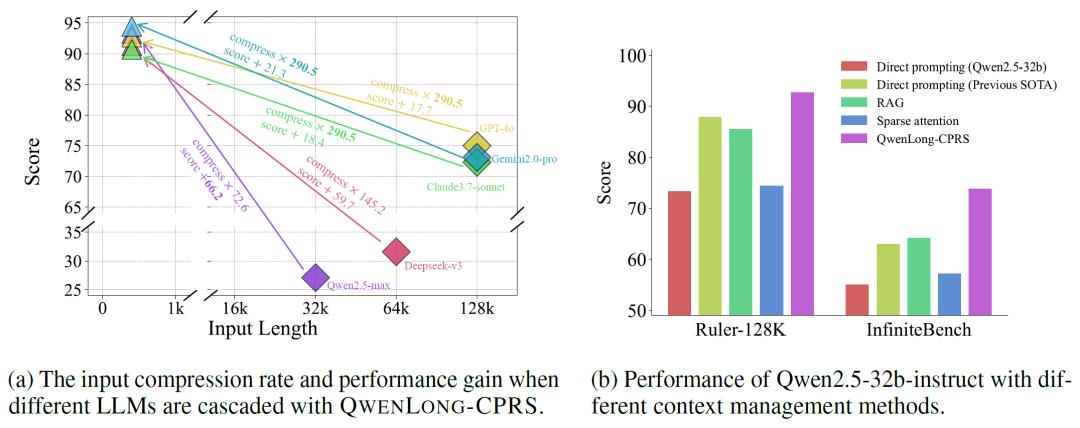
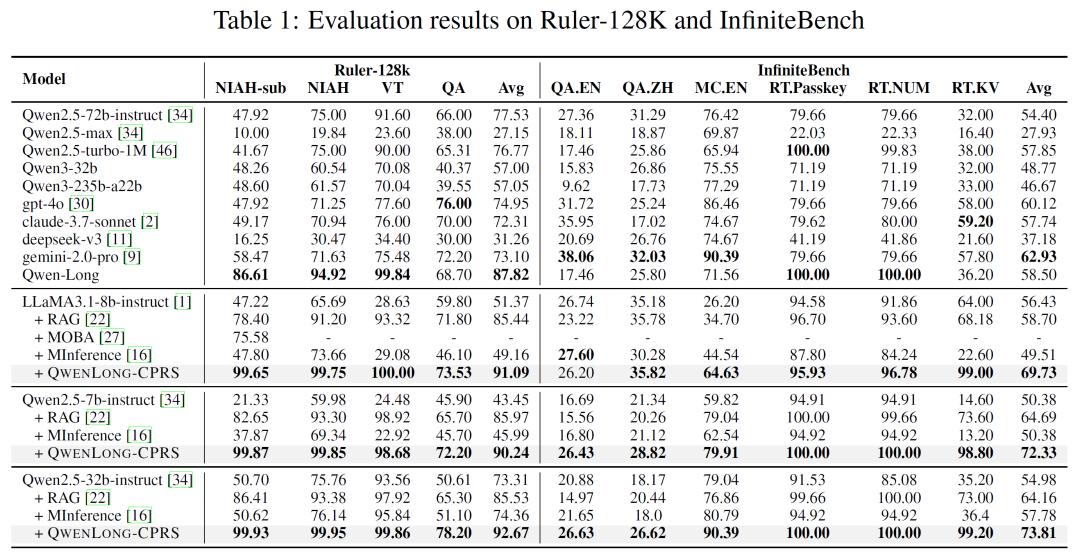
在Ruler-128K的“Needle-in-a-Haystack”任务中,模型需从混入噪声的128K tokens文本中定位目标语句。QWENLONG-CPRS的准确率达99.65%,远超RAG的82.4%与稀疏注意力方案Minference的47.8%。另外,当上下文长度扩展至1M tokens且目标语句深埋序列中部,深度100%时,模型仍能保持完美识别,而GPT-4o、Gemini 2.0-pro等专有模型的准确率已降至70%以下。
2.效率革命:压缩21倍,性能反超
在InfiniteBench多语言问答基准中,QWENLONG-CPRS实现了21.59倍的上下文压缩率,即在处理2M tokens输入时,仅需保留约92K tokens的核心信息,即可使下游模型的回答准确率提升19.15分。以Qwen2.5-32B-Instruct为例,集成该框架后,其在Ruler-128K与InfiniteBench的得分分别达到99.93%与73.81%,超越了GPT-4o(76%)、Claude3.7-sonnet(70%)等付费模型,甚至比自身直接提示的性能提升了48.2%。
3.架构无关性:兼容一切,激活所有
QWENLONG-CPRS的另一大亮点是其即插即用特性。无论是开源模型还是专有模型,只需通过单一前向传播即可完成集成,无需重新训练或修改底层架构。实验显示,即便是最大上下文窗口仅32K的Qwen2.5-32b-instruct模型,在集成后处理128K tokens任务时,准确率从50.7%跃升至99.93%,实现了“小马拉大车”的性能飞跃。
QWENLONG-CPRS为现有模型注入了处理百万级token的能力,更通过“小模型逆袭大场景”的实践,证明了优化算法与架构创新的价值远胜于单纯的参数堆砌。
当前,QWENLONG-CPRS的70亿参数版本已在Hugging Face与ModelScope平台开源,吸引了超过2.3万次下载。阿里方面表示,将持续推动该框架与Qwen3等新一代模型的深度整合,并通过阿里云API开放长上下文优化服务,降低企业级应用的技术门槛。
 豫公网安备41010702003375号
豫公网安备41010702003375号