
清华大学提出“R2R”神经token路由方法,大模型“指挥”小模型“劳动”,效率飙升
![]() 前沿资讯
1748593500更新
前沿资讯
1748593500更新
![]() 0
0
当前的大语言模型(LLM)虽具备强大的推理能力,但其庞大的参数规模导致推理成本非常高,生成数千token需数百亿参数支持。而经过蒸馏的小语言模型(SLM)虽效率更高,却常因推理路径与LLM偏离导致性能下降。在数学基准AIME中,15亿参数的SLM(R1-1.5B)与320亿参数的LLM(R1-32B)在45%的问题上答案不同,准确率相差4.8倍。

研究发现,SLM与LLM的推理路径差异主要源于关键分歧token(divergent tokens),这类token数量仅占总生成量的约4.9%,却会导致后续推理路径大幅偏离。而剩下89%的token均为相同或中性差异,不影响推理结果。基于这一发现,清华大学联合Infinigence AI、上海交通大学的研究团队提出了一种名为Roads to Rome (R2R)的神经token路由方法,该方法通过仅对关键分歧token调用LLM修正,其余由SLM生成,实现了效率与性能的平衡。
R2R设计了一个仅5600万参数的轻量级路由器,通过分析SLM生成的token概率分布(logits)、token频率等特征,实时判断是否需要调用LLM修正。例如,高熵值(不确定性高)的token或低频token更可能引发推理偏差,需优先由LLM处理。

研究团队还开发了一套无需人工干预的标注流程,利用LLM生成参考推理路径,对比SLM与LLM的token差异,通过“延续-验证”机制,生成差异token后的后续推理并由另一LLM验证,自动区分中性与分歧token。该方法在760万token标注中实现高效并行处理,仅需2.3天、使用8块A800 GPU就完成了数据生成。
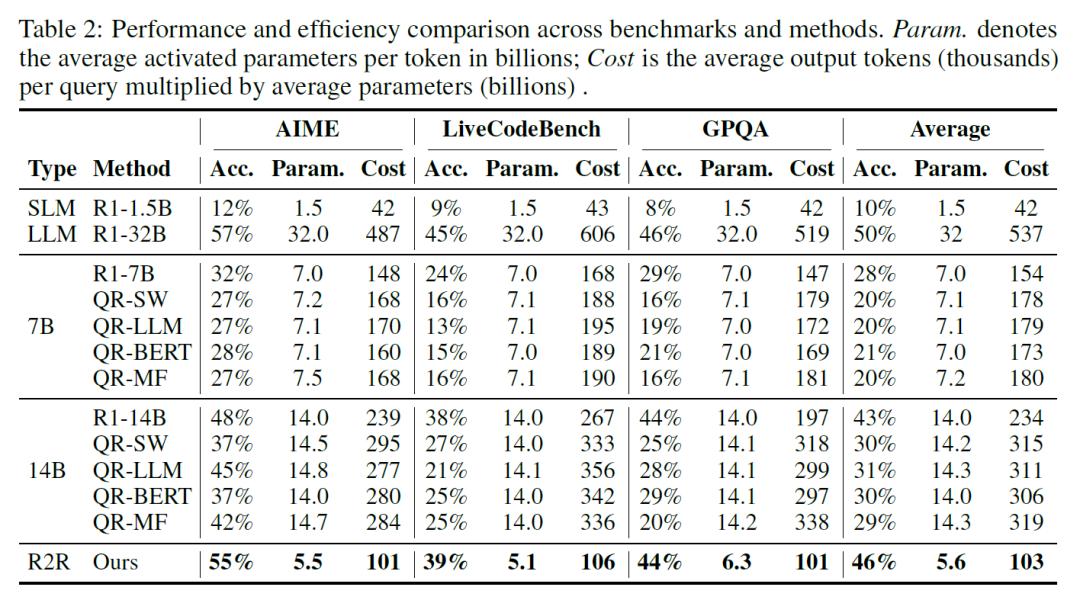
在数学(AIME)、编程(LiveCodeBench)、问答(GPQA)三大基准测试中,R2R展现出显著的综合优势。当平均激活参数为56亿时,仅为R1-32B的17%,R2R在AIME的准确率达55%,超过140亿参数的R1-14B(48%),且比R1-1.5B的准确率提升4.6倍。相比R1-32B,R2R的推理速度提升2.8倍,每查询总计算成本(参数×token数)降低至1/5,且LLM仅在12.4%的token生成中被调用。通过调整路由阈值,可灵活控制LLM使用率在5%-20%之间,在AIME中实现准确率从42%到55%的平滑过渡,满足不同场景的算力预算需求。
与现有方法相比,R2R的token级路由显著优于查询级路由(QR)和推测解码(Speculative Decoding)。QR需为整个查询选择单一模型,而R2R可在同一句子中混合使用SLM与LLM。在AIME推理中,R2R在“思考阶段”调用LLM修正关键步骤,在“结论陈述”阶段完全使用SLM,使LLM使用率降低40%。推测解码需周期性回滚验证,而R2R通过即时修正分歧token避免全局回滚,在长文本生成中效率提升1.5倍,且无输出不一致风险。
该技术在代码生成、科学计算等需要深度推理的场景具有直接应用价值。在LiveCodeBench编程任务中,R2R通过LLM修正算法逻辑中的分歧token,使通过率(Acc)从SLM的9%提升至39%,同时保持51亿的平均激活参数,仅为LLM的16%。
目前R2R代码已开源,支持DeepSeek-R1系列模型的混合推理。研究团队指出,当前方法基于贪心采样策略,未来将探索波束搜索等更复杂采样方式,并优化系统级并行调度,进一步提升吞吐量。此外,结合模型量化与稀疏注意力等技术,R2R可以在边缘设备实现高效推理,推动LLM在实时交互、物联网等场景的普及。
参考资料:https://arxiv.org/abs/2505.21600;https://github.com/thu-nics/R2R
 豫公网安备41010702003375号
豫公网安备41010702003375号