
清华大学团队提出ZeroGUI框架,推动GUI代理训练从“人工驱动”迈向“自主进化”
![]() 前沿资讯
1748774637更新
前沿资讯
1748774637更新
![]() 0
0
随着视觉语言模型的快速发展,基于纯视觉的GUI代理已能通过感知和操作界面完成用户指令。然而,现有方法普遍采用离线学习框架,存在人工标注成本高昂和动态环境适应性不足两大核心问题。
在此背景下,清华大学与上海人工智能实验室联合发布了一个全新的在线学习框架ZeroGUI。该框架借助视觉语言模型,成功实现了图形用户界面代理(GUI Agent)的自动化训练,彻底摆脱了对高质量人工标注数据的依赖。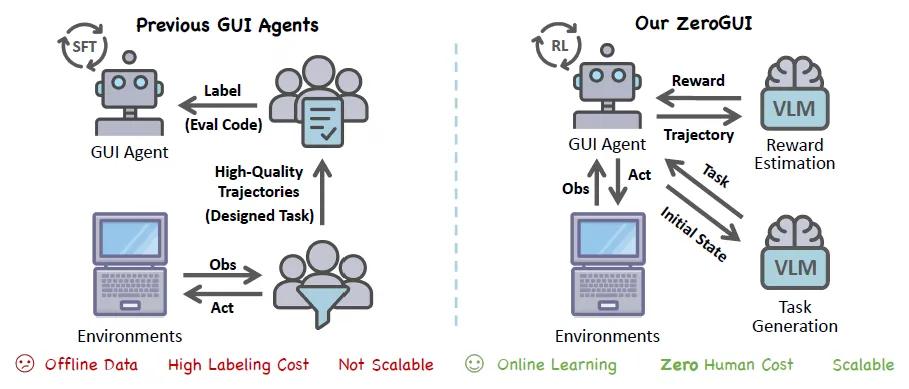
ZeroGUI框架的核心在于设计的三大模块,它们共同构成了一个不需要人工参与的全自动训练体系,让图形界面代理(GUI Agent)能够自主学习如何完成各种任务。
第一个模块是自动任务生成器,它的作用是利用类似GPT-4o的语言模型,根据当前界面的截图自动生成训练任务。为了让任务更丰富多样,模型每次会同时生成多个不同的任务,其中还包括一些“不可能完成的任务”,专门用来训练代理识别哪些任务是行不通的。通过这种方式,系统能自动产生数千个涵盖办公软件、手机操作等不同场景的任务。
第二个模块是自动奖励评估器,它的任务是判断代理执行任务的结果是成功还是失败。以往的方法需要人工编写代码来验证任务是否完成,而ZeroGUI则利用另一个语言模型来自动评估。评估时,系统会把代理执行任务过程中的所有截图都交给模型分析,而不是只看最后一张截图,这样能更准确地判断任务是否真的完成。同时,系统不会参考代理自己声称的“任务完成”等文本反馈,避免代理“说谎”误导评估。为了减少误判,模型会对同一个任务结果进行多次评估,只有当多次判断结果一致时才会给出最终奖励分数(成功为1,失败为0)。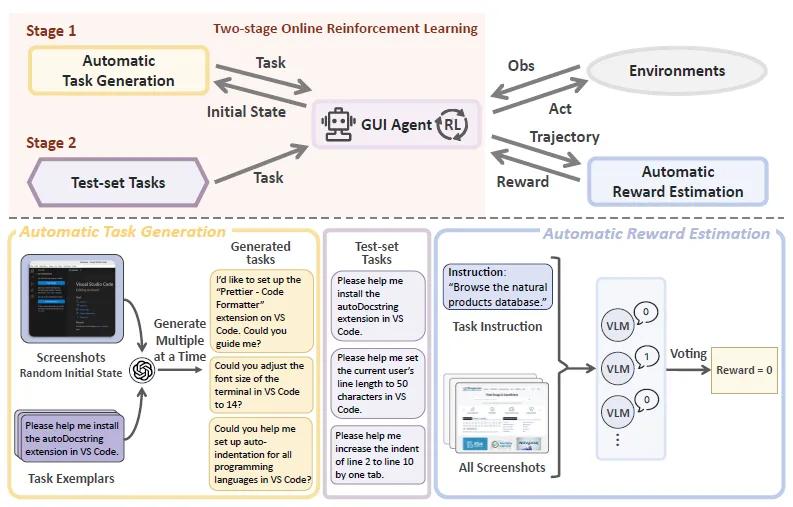
第三个模块是两阶段强化学习引擎,它负责让代理通过不断尝试来优化自己的操作策略。第一阶段,代理会在自动生成的任务上进行基础训练,使用改进后的GRPO算法。传统算法在计算奖励时容易出现数值不稳定的问题,ZeroGUI换成了更稳定的计算方式,就像给算法加了一个“稳定器”,让训练过程更顺畅。第二阶段,当代理面对真实的测试任务时,会利用评估器给出的实时反馈继续学习,调整自己的操作步骤,就像学生通过模拟考试查漏补缺一样。
自动生成的任务为代理提供了“练习题”,自动评估模块给出“评分标准”,强化学习引擎则根据评分不断改进代理的“解题方法”,这三个模块环环相扣,最终实现了从任务生成、结果评估到策略优化的全流程自动化,让代理无需人工指导就能自主提升完成任务的能力。
为验证ZeroGUI的有效性,研究团队在桌面环境OSWorld和移动环境AndroidLab进行了全面测试,结果显示,其性能远超传统训练模式,在多个关键指标上实现突破性提升。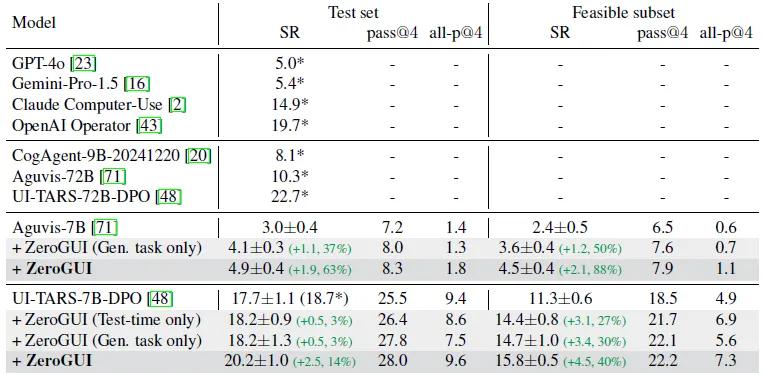
在OSWorld桌面测试中,以UI-TARS-7B-DPO模型为例,原本只能完成17.7%的任务,经过ZeroGUI训练后,成功率提升至20.2%,相当于每100个任务能多完成3个。而在排除故意设计的不可行任务的“可行任务子集”中,成功率提升更为显著,从11.3%跃升至15.8%,提升幅度达40%。
另一模型Aguvis-7B的基础成功率仅为3.0%,但在ZeroGUI加持下直接提升63%,达到4.9%,尤其在可行任务中提升88%,说明即使是“基础较弱”的模型,也能通过ZeroGUI大幅提升能力。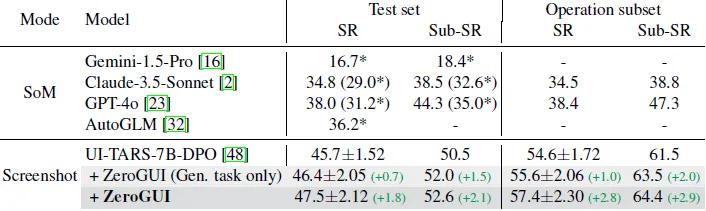
在AndroidLab移动测试中,针对设置闹钟、编辑联系人等的操作类任务,模型成功率从54.6%提升至57.4%,子目标成功率从61.5%提升至64.4%。值得注意的是,ZeroGUI仅依赖界面截图,就能在纯视觉模式下超越部分依赖结构化数据的模型,证明其适应移动复杂界面的能力更强。
ZeroGUI的诞生标志着GUI代理训练从“人工驱动”向“自主进化”的范式转变,其完全摒弃手工标注,大幅降低数据获取门槛,加速了模型在新场景的部署。研究团队表示,未来将进一步探索低资源场景下的快速适应、多代理协作机制以及更复杂的长程任务规划,推动GUI代理在智能助手、自动化办公等领域的实际应用。
参考资料:https://arxiv.org/abs/2505.23762
 豫公网安备41010702003375号
豫公网安备41010702003375号