
英伟达提出ProRL,首次通过系统性实验证明:强化学习并非只是简单优化已有答案
![]() 前沿资讯
1748937914更新
前沿资讯
1748937914更新
![]() 0
0
近年来,大语言模型在数学解题、编程和逻辑推理等复杂任务上表现日益出色,而强化学习(RL)被认为是推动这些进步的关键技术之一。但一个关键问题一直困扰着研究者:这些模型是通过训练“学会”了新的推理方法,还是只是更加高效地“记住”了已有的知识?
针对这一问题,英伟达的研究团队提出了一种新的训练方法,叫做“延时强化学习”(ProRL,Prolonged Reinforcement Learning),这种方法延长了训练周期,给模型更多时间和更多任务去“思考”,从而获得更深层次的理解能力。
研究团队使用GRPO(Group Relative Policy Optimization)算法替代传统PPO,简化了训练结构并提高了稳定性。在训练过程中,模型容易出现“熵塌缩”现象,即只倾向于生成少数高概率答案,导致思维方式单一。为了解决这一问题,ProRL结合了高温采样、DAPO算法中的动态采样和解耦clip边界机制,使模型能持续产生多样化输出。此外,ProRL引入了KL散度惩罚项,防止模型偏离已有能力范围过远。更重要的是,研究人员设置了周期性的参考策略重置机制,帮助模型在保持稳定的同时不断推进边界探索,避免陷入旧策略的惯性。
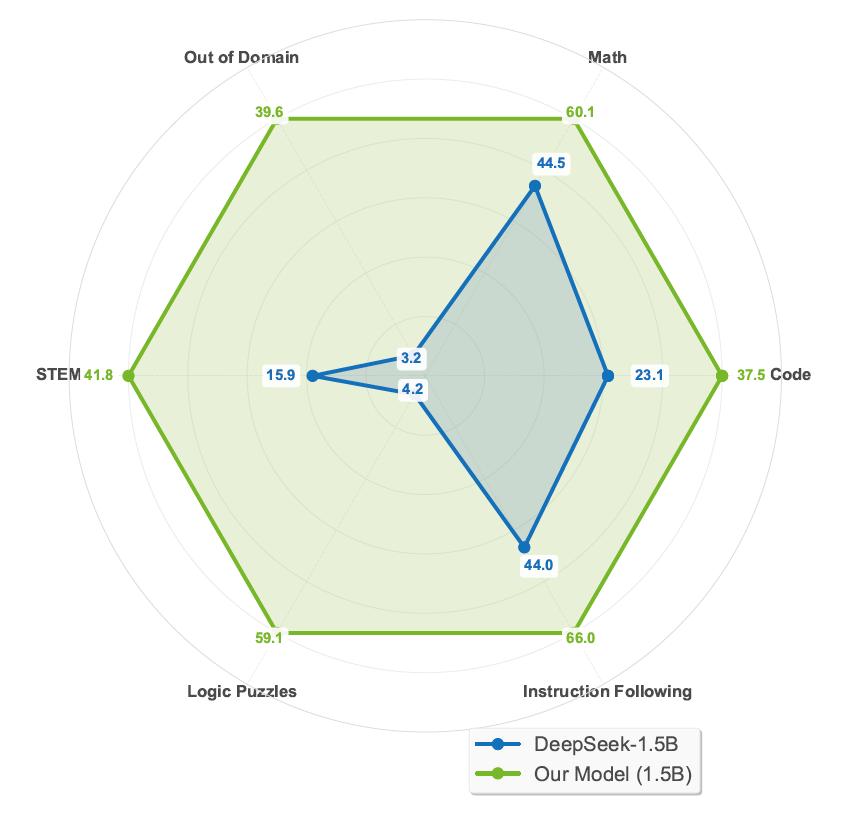
训练数据方面,研究团队构建了一个涵盖13.6万个任务样本的大规模多领域数据集,覆盖数学、编程、STEM科学、逻辑谜题以及指令执行五大类任务。在此基础上训练出了一个Nemotron-Research-Reasoning-Qwen-1.5B模型,参数规模仅为15亿,但在各类评估任务中取得了远超基础模型(DeepSeek-R1-1.5B)的表现。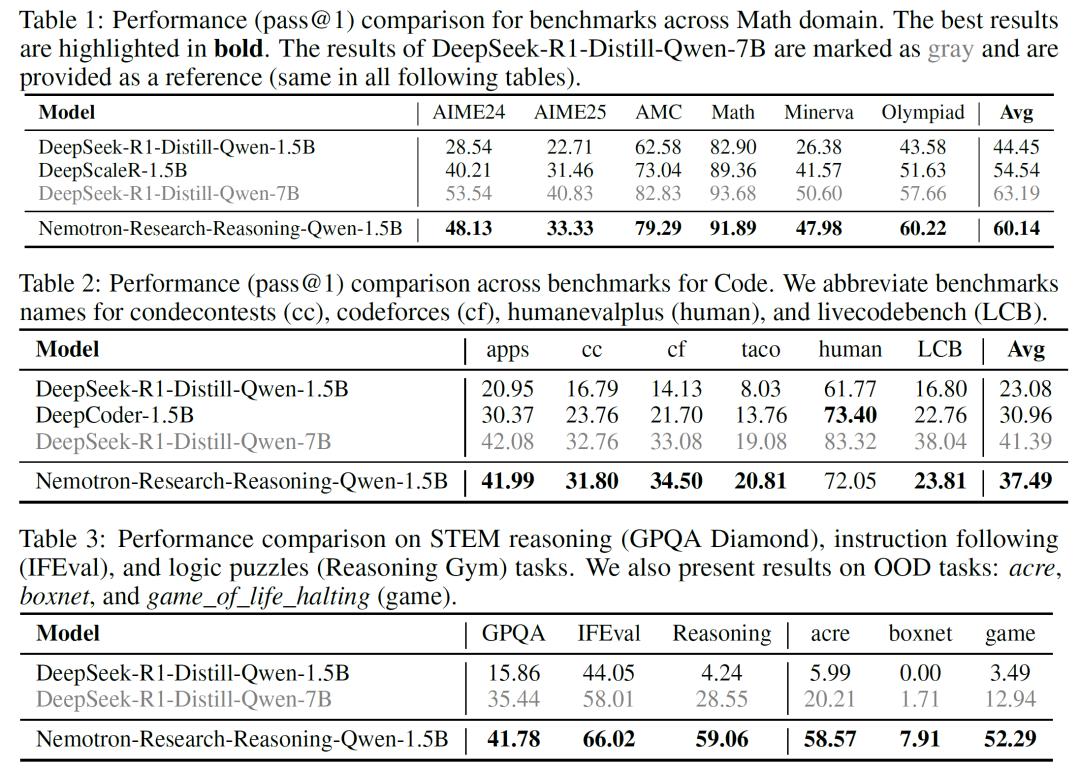
在逻辑推理任务上,Nemotron提升幅度超过54%,STEM推理任务(GPQA Diamond)准确率提升25.9%,显示出对复杂逻辑和科学问题的更强理解能力。在部分逻辑谜题任务中,基础模型无论尝试多少次均无法正确解答,而ProRL模型的pass@1准确率可达100%。此外,模型在分布外(OOD)任务中,表现出显著的泛化能力,准确率远高于基础模型,表明其能够内化抽象推理模式,适应未见过的复杂场景。实验还表明,在足够的计算资源支持下,强化学习可推动模型不断探索新的解空间。
在训练过程中,为衡量模型是否真正“学会新东西”,研究团队引入了创造力指数(Creativity Index)的概念,用以量化模型输出与预训练数据的相似度。他们发现,ProRL训练后的模型输出在多个任务上表现出更高的新颖性,说明其推理方式已发生根本变化,非简单重复已有数据。此外,进一步分析表明,强化学习在模型原本不擅长的任务上提升最为显著,而在原本表现较好的任务上收益较小甚至略有下降,验证了“越弱的起点,越大的进步”这一结论。
这项研究首次通过系统性实验证明了:强化学习不仅能优化现有能力,更能解锁基础模型无法触及的推理策略。ProRL的成功得益于三大关键因素:足够长的训练周期、多样化的任务覆盖,以及稳定的训练技术。未来,更小参数规模、更强推理能力的模型可能成为现实,推动AI在医疗、科学发现等关键领域的普及。
参考资料:https://arxiv.org/abs/2505.24864
 豫公网安备41010702003375号
豫公网安备41010702003375号