
语言模型能记住多少信息?研究表明:每参数能存储3.6比特的信息
![]() 前沿资讯
1749115513更新
前沿资讯
1749115513更新
![]() 0
0
随着大语言模型在自然语言处理领域日益普及,人们对其“记忆”能力也愈发关注。Meta(FAIR)、Google DeepMind、康奈尔大学和英伟达的研究人员联合发布了一项最新研究,探索了语言模型在训练过程中到底记住了多少数据,以及这种记忆是如何形成的。
研究提出了一种新方法,将模型记住的信息分为两种类型,用于评估模型到底“知道”某个数据点的多少信息。非预期记忆:模型记住了特定训练样本的细节,通常是不希望发生的。泛化能力:模型学习到数据背后的普遍规律,能对新数据做出合理预测。这种区分有助于理解模型究竟是在“理解”语言,还是仅仅在“背诵”内容。
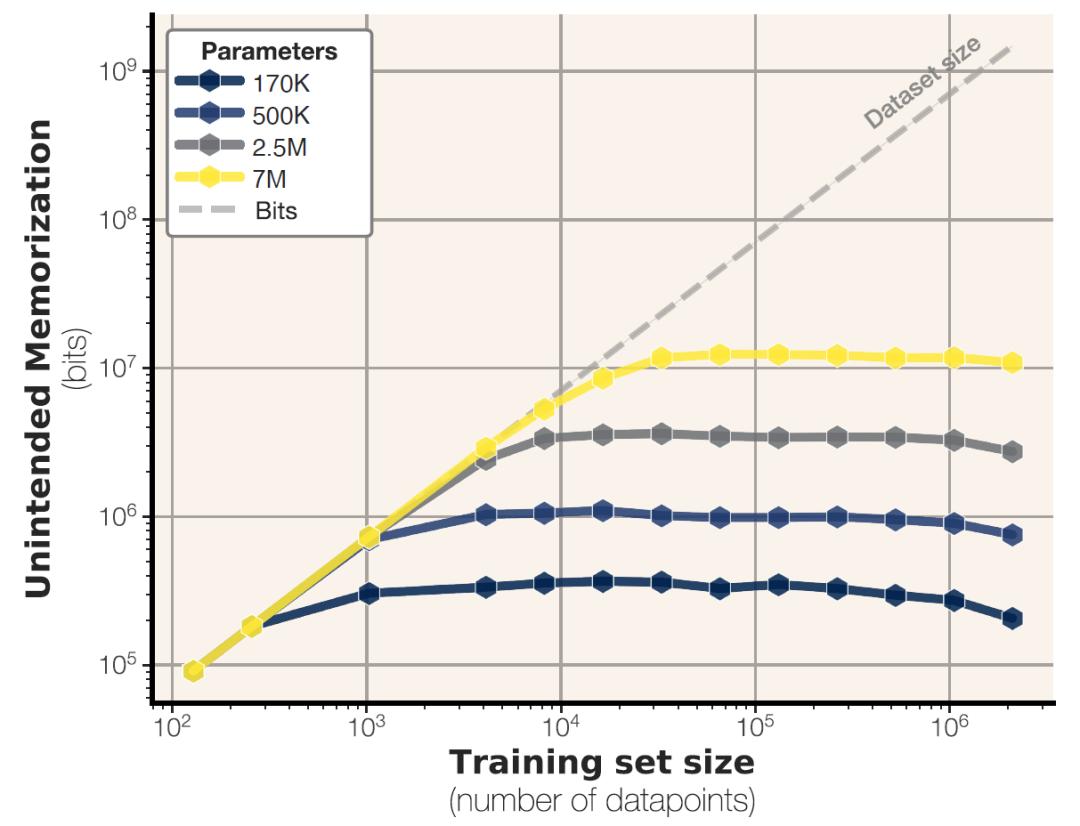
为了精确衡量语言模型是否记住了某些训练数据,研究人员提出了一种基于“信息压缩”的全新评估方式。他们将这种“记住”的行为称为“非预期记忆”,也就是模型在训练过程中无意中牢牢记住了某些具体数据点,而不是从中提取出规律或泛化能力。
这个方法的核心思路是:如果一个数据点,比如一句话,在有模型存在的前提下能够被压缩成更短的表示,那么说明模型对这个数据点的记忆程度较高。反过来说,如果该数据点无法被有效压缩,说明模型对它并不熟悉,也没有特别记住它。这种“压缩测记忆”的方法,就像是在测试一个学生对文章的记忆程度。若只需一点提示,他就能准确复述内容,说明他记得非常牢固,而如果提示很多还断断续续,说明记忆程度不高。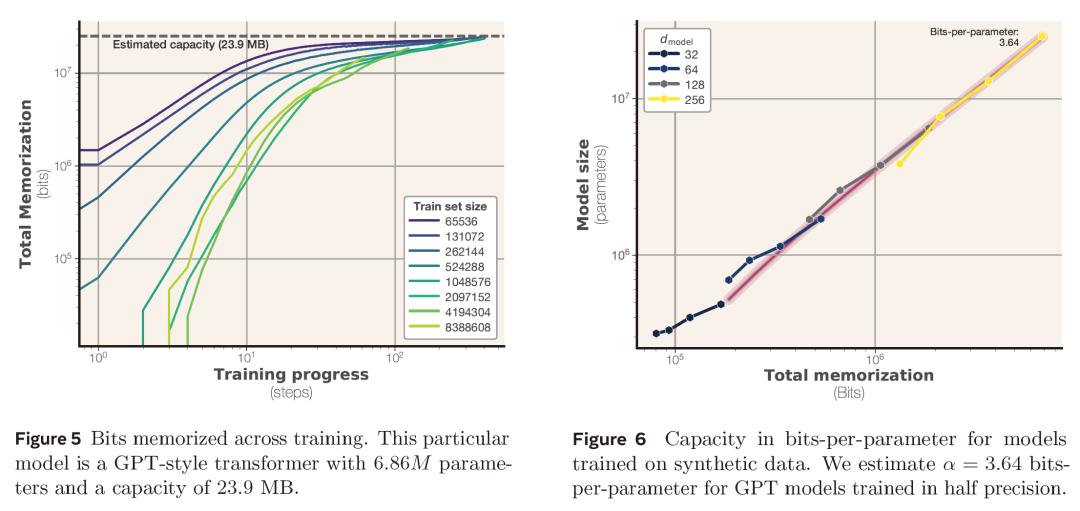
研究团队将每个数据点视作一个“信息包”,先计算该数据点本身的信息量(原始比特数),再计算它在模型存在条件下能够被压缩到的最短长度。两者的差值,就表示模型为这段信息“节省”了多少比特,也就是它记住了多少内容,比如某句话原本需要100比特表示,在模型的帮助下只需要30比特,那模型对这句话的记忆量就是70比特。
实验中,研究人员训练了数百个从50万到15亿参数规模的Transformer模型,发现GPT家族模型的记忆容量约为3.6比特/参数。当数据完全独立时,模型记忆量随参数线性增长,直至达到容量上限后趋于平稳。模型精度对容量影响有限,从bfloat16升级到fp32精度仅使容量提升约9%,表明额外精度比特未主要用于原始数据存储。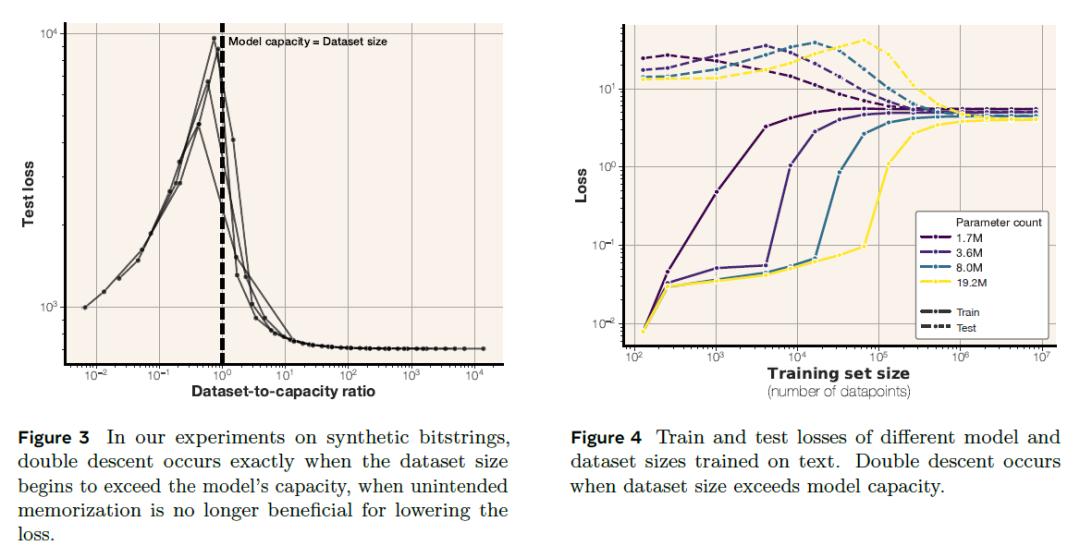
在转向真实文本数据时,模型表现出“记忆-泛化”的动态切换。小数据集阶段优先存储具体样本,记忆量随数据增加上升。当数据量超过模型容量时,模型开始减少对单个样本的记忆,转而学习通用模式,此阶段称为“grokking”(顿悟)。研究还首次通过实验证实,数据集规模超过模型容量时测试损失先升后降,印证了“模型容量不足时被迫泛化”的理论。
研究还提出了一种“缩放定律”,可预测在给定模型容量和数据量下,成员推理的准确度:成员推理成功率随模型容量增加而提高,随数据规模扩大而下降,数据量与模型容量之比超一定阈值时,推理成功率趋近随机水平(F1分数≈0.5)。
这项研究首次系统性量化语言模型记忆能力,揭示从“记忆主导”到“泛化主导”的学习阶段转变。随着大模型向万亿参数规模演进,理解其存储与泛化的平衡机制成为开发高效、可信AI系统的关键。论文作者表示,该研究为解读模型“知道什么”与“如何学习”提供了新度量标尺,将推动更安全、更具可解释性的AI发展。
参考资料:https://arxiv.org/abs/2505.24832
 豫公网安备41010702003375号
豫公网安备41010702003375号