
苹果最新研究结果表明:模型的“推理能力”存在根本局限性,跟人类没法比
![]() 前沿资讯
1749207063更新
前沿资讯
1749207063更新
![]() 0
0
推理模型通过长思维链(CoT)和自我反思等“思考”机制,在各类推理基准测试中展现出了一定潜力,但在面对不同复杂度的问题时,其性能暴露出了一些根本性的不足。
苹果研究团队通过四种可控的谜题环境:汉诺塔(Tower of Hanoi)、跳棋(Checker Jumping)、过河(River Crossing)和积木世界(Blocks World),系统地分析了模型的推理能力。这些环境能够在保持一致逻辑结构的同时,精确控制问题的组合复杂度,从而不仅可以评估模型的最终答案,还能深入分析其内部推理过程。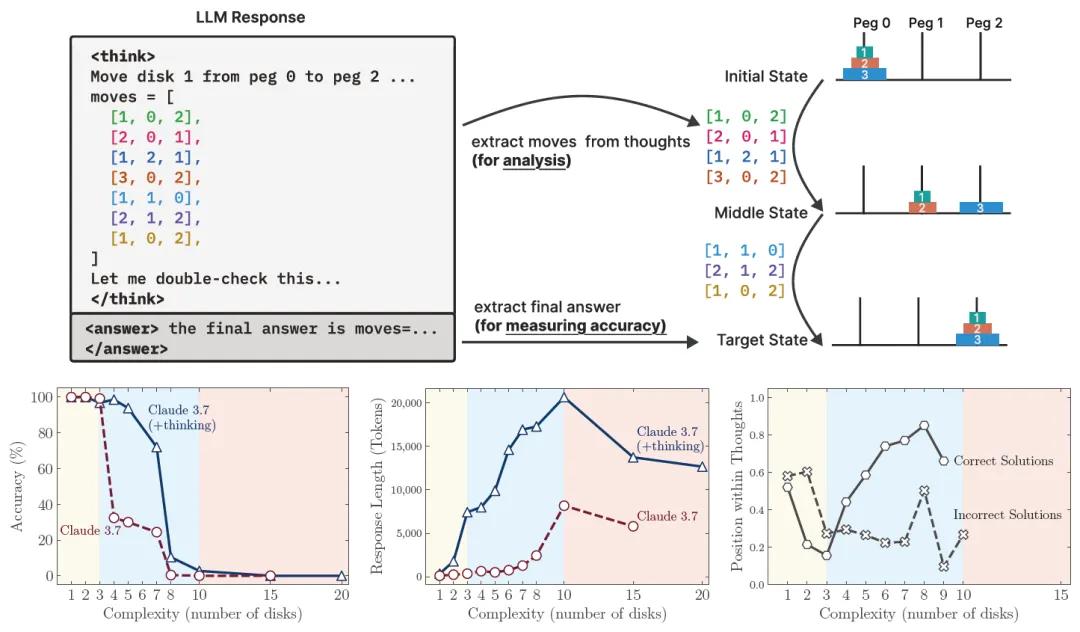
研究发现,推理模型与标准的语言模型在不同复杂度的任务中呈现出三种不同的性能表现区域:
低复杂度任务:在一些较为简单的任务中,标准的非推理模型表现得更为高效和准确。例如,当汉诺塔的磁盘数量为1-3个时,非推理模型Claude 3.7 Sonnet无需生成冗长的思维链,就能直接给出正确移动步骤,准确率超过80%,且使用的tokens数量比推理模型少30%-50%。
中等复杂度任务:随着问题复杂度的适度增加,具备思考机制的推理模型开始展现出优势。以跳棋问题为例,当棋盘上有4-7对棋子时,Claude 3.7 Sonnet Thinking能通过生成平均长度为5000-8000 tokens的思维链,逐步排除错误路径,其准确率比非推理模型高20%-30%。在过河问题中,当有3对参与者时,推理模型能通过模拟不同的过河组合,最终找到符合安全约束的解决方案,而同一复杂度下非推理模型的失败率超过40%。
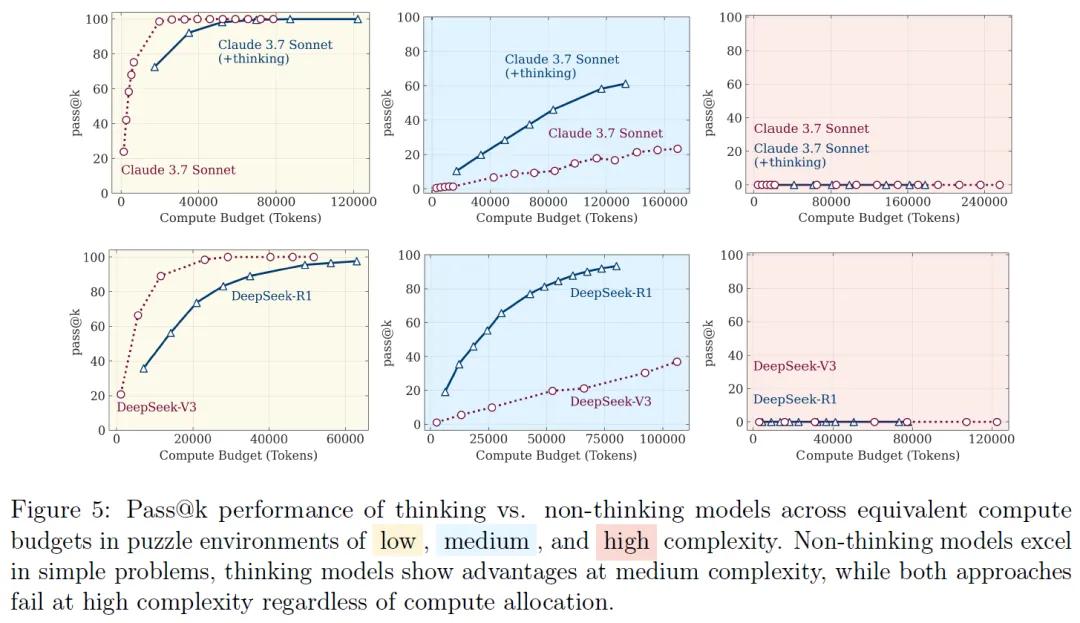
高复杂度任务:当问题复杂度达到较高水平时,无论是推理模型还是标准语言模型,性能都出现了完全崩溃的情况。例如,当汉诺塔的磁盘数量超过8个时,所有模型的准确率骤降至零。接近崩溃点时,推理使用的tokens数量反而随着问题复杂度的增加而减少。以DeepSeek-R1为例,在磁盘数量为10个时,其使用的tokens数量为12000左右,而当磁盘数量增加到15个时,tokens数量反而降至8000以下,而此时模型仍有64k的token预算可用。
在需要精确计算的任务中,推理模型表现也不佳。研究人员在汉诺塔问题中向模型提供了递归算法的伪代码,要求模型按照步骤执行,但结果显示,当磁盘数量超过5个时,模型执行算法的准确率与自主求解时并无显著差异,依然在10步左右出现错误,表明推理模型在理解和执行逻辑步骤方面存在根本性缺陷,即使有明确的算法指导,也难以保证计算的准确性。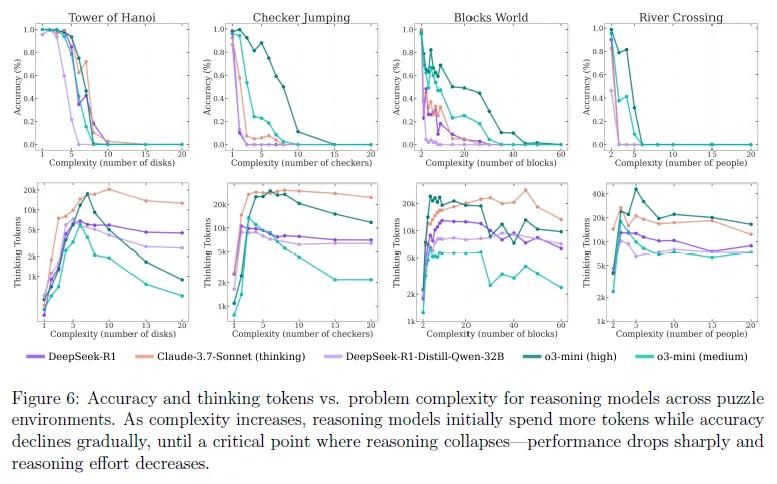
通过对推理过程的分析发现,在简单问题中,推理模型常常在早期就找到了正确的解决方案,但却继续无效地探索错误的替代方案,导致计算资源的浪费。在3个磁盘的汉诺塔问题中,Claude 3.7 Sonnet Thinking在生成正确移动序列后,仍会花费30%的token预算去尝试错误的路径,这种“过度思考”现象使推理效率降低了40%以上。
而在中等复杂度问题中,如5对棋子的跳棋问题,模型往往需要探索超过20条错误路径后,才能在思维链的后半部分找到正确解决方案,正确解出现的平均位置在思维链的70%处。当问题复杂度超过一定阈值时,模型则完全无法找到正确的解决方案,思维链中不再出现任何有效的中间解。
参考资料:https://machinelearning.apple.com/research/illusion-of-thinking
 豫公网安备41010702003375号
豫公网安备41010702003375号