
微软研究院携南京大学提出GUI-Actor,将“操作位置”从“坐标”升维到“视觉关注区域”,推动视觉交互AI真正落地
![]() 前沿资讯
1749293809更新
前沿资讯
1749293809更新
![]() 0
0
随着语言模型(LLM)和视觉语言模型(VLM)的快速发展,构建能够理解自然语言并自动操作图形用户界面(GUI)的智能代理成为研究热点。在这一领域中,一个关键挑战是“视觉定位”:如何根据自然语言指令,在屏幕中正确识别和操作目标区域。传统方法普遍依赖坐标生成机制,即模型输出如“x=0.125,y=0.23”这样的具体位置坐标。然而,这种方法存在很多局限性,包括空间语义对齐差、监督模糊性高、以及视觉特征与坐标粒度不匹配等问题。
针对这些挑战,微软携手南京大学等研究机构联合提出了GUI-Actor:一种基于视觉语言模型的全新GUI视觉定位框架,其最大特点是“去坐标化”(coordinate-free),不再依赖于明确的屏幕坐标,而是通过注意力机制,直接识别出可能的操作区域,从而模拟人类直接点击屏幕上目标区域的自然行为。
GUI-Actor引入了一个特别的<ACTOR>令牌,配合注意力机制,能够在模型的一次前向计算中识别出多个可能的操作区域。这种“显式空间对齐”策略,模拟人类在观察界面时通过视觉关注区域来判断操作对象的方式,更贴近真实交互行为。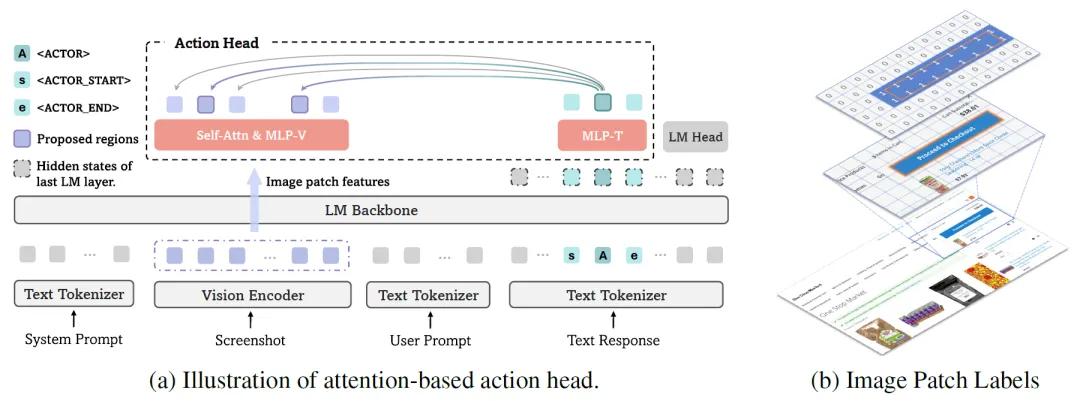
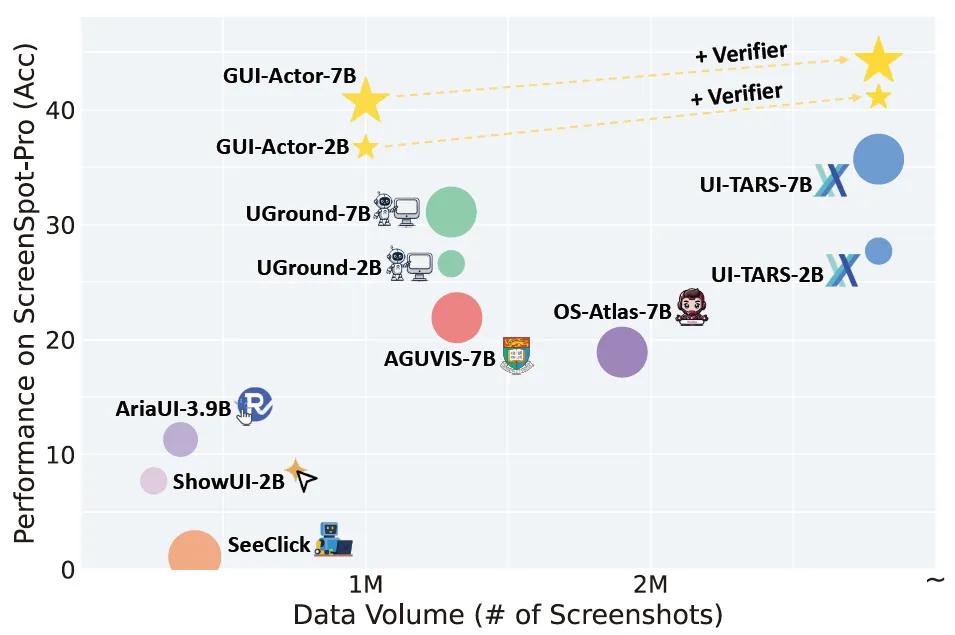
GUI-Actor在多个权威基准测试上展现出强劲性能,尤其是在ScreenSpot-Pro这一高分辨率、高领域迁移任务中,GUI-Actor-7B使用Qwen2.5-VL作为基础模型,在参数量更小的前提下,超越了原本使用72B参数的UI-TARS-72B等强大模型。GUI-Actor-7B+Verifier在ScreenSpot-Pro中取得44.2的平均分,显著领先UI-TARS-7B(35.7)。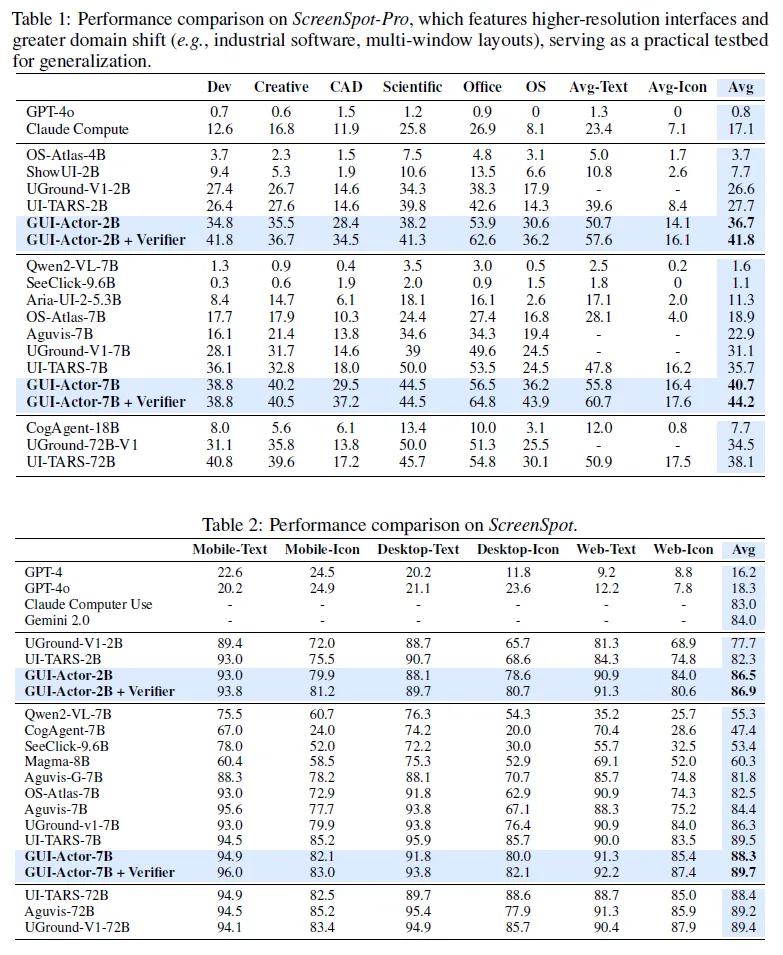
GUI-Actor-2B在多个benchmark中也超越了大部分7B模型,展现出极高的参数效率。LiteTrain轻量版本仅微调100M参数,即可达成接近全模型训练的精度,在节省计算资源的同时仍保持出色性能。此外,GUI-Actor天然具备多区域预测能力,无需额外推理成本即可生成多个候选操作区域,使其更适合复杂的GUI场景操作。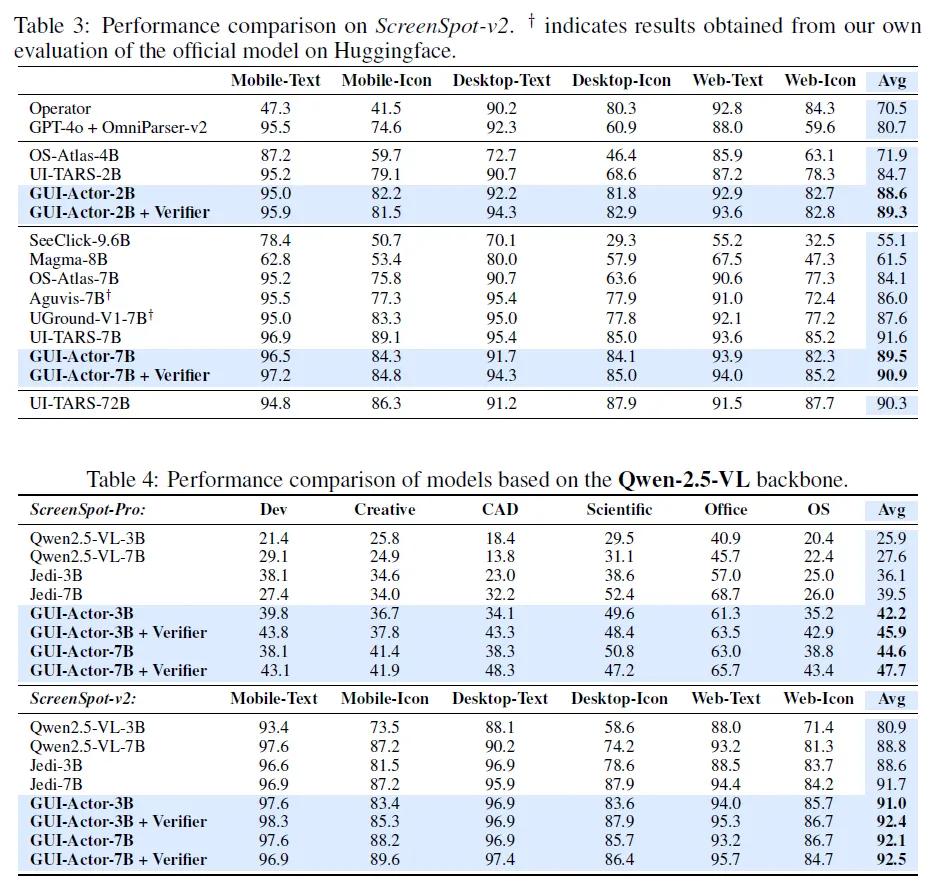
测试还表明,GUI-Actor具备优秀的跨分辨率和跨界面泛化能力。在包含工业软件、多窗口等极具挑战性的测试集中,其表现优于所有同规模模型。研究者指出,这是由于GUI-Actor通过<ACTOR>令牌直接与视觉patch建立联系,避免了将高分辨率图像映射为离散坐标这一瓶颈。更重要的是,GUI-Actor在仅用60%训练数据的情况下,已能达到其最终性能,远优于传统坐标模型需要80%以上数据才达到收敛的效率。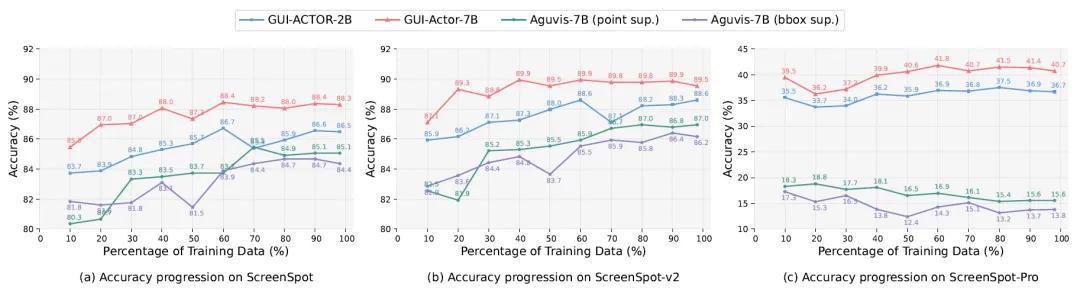
GUI-Actor通过将“操作位置”从“坐标”升维到“视觉关注区域”,成功突破了坐标生成机制带来的种种限制。它不仅通过轻量级结构赋予VLM以GUI理解能力,更在无需牺牲模型原始通用能力的前提下,取得了比肩甚至超越业界主流模型的性能。GUI-Actor有望成为下一代智能交互代理的基础技术,推动“看得懂也点得准”的视觉交互AI真正落地。
参考资料:https://arxiv.org/abs/2506.03143https://huggingface.co/papers/2506.03143
 豫公网安备41010702003375号
豫公网安备41010702003375号