
华为Pangu团队基于昇腾AI处理器训练出7180亿参数的MoE模型,性能比肩DeepSeek R1
![]() 前沿资讯
1749378535更新
前沿资讯
1749378535更新
![]() 0
0
华为Pangu团队首次公开基于昇腾AI处理器的大规模混合专家(MoE)模型训练方案。通过架构仿真优化与系统级调优,成功训练出7180亿参数的稀疏大模型,在6000昇腾NPU集群上实现30%的模型浮点利用率,性能比肩DeepSeek R1,标志着昇腾系统已具备支撑当前最先进语言模型全流程训练的能力。
混合专家模型(MoE)通过动态激活部分专家参数,在理论上可大幅提升模型规模与效率。然而,近万亿参数规模对软硬件系统提出严峻挑战:动态稀疏结构导致计算资源利用率波动,多设备通信开销显著增加,内存管理复杂度呈指数级上升。针对昇腾NPU特性,华为Pangu团队提出“仿真驱动架构设计+系统深度优化”双轮方案,实现从模型架构到训练效率的全链条突破。
为避免反复进行昂贵的硬件实验,团队开发了昇腾NPU专用仿真工具,通过自底向上的工作流预测模型性能:先验证单个算子在昇腾芯片上的表现,再逐层评估端到端效率,同时纳入计算-通信模式、算子交互和硬件约束等关键因素。通过对10000种模型配置的仿真分析,最终确定Pangu Ultra MoE的最优架构:256个专家、7180亿参数,兼顾性能与资源效率。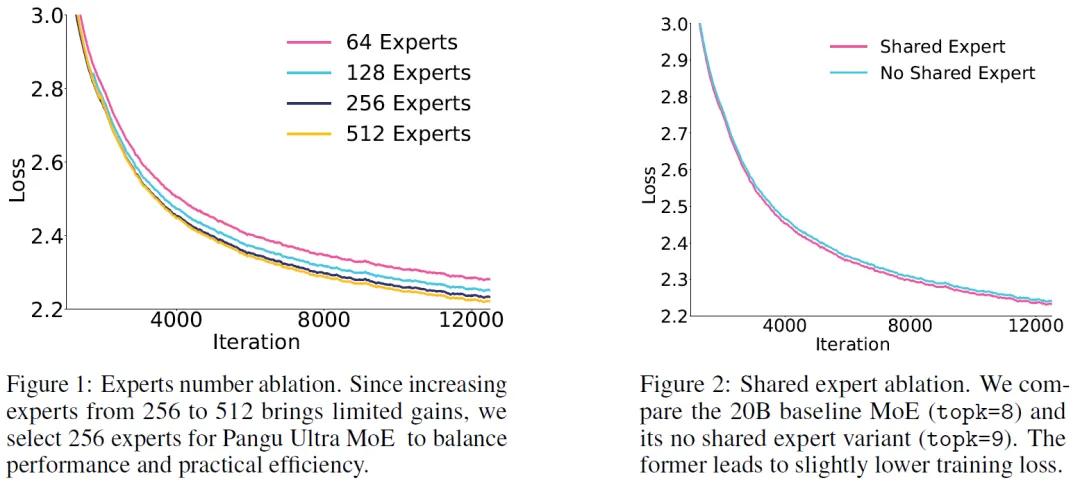
在训练过程中,Pangu Ultra MoE运行于6000张Ascend NPUs组成的大型集群之上。通过创新的“虚拟流水线”并行策略与“层次化专家通信”机制,系统最大程度地降低了通信开销,并实现了前后向计算与通信的深度重叠。结合一系列精细化的内存优化与动态专家负载平衡策略,模型训练过程最终实现了每秒处理146万token的速度,硬件利用率提升至30.0%,相比基线系统提高近60%。
除了性能之外,Pangu Ultra MoE在多项语言理解与推理任务中表现同样亮眼。在MMLU、C-Eval、IF-Eval等标准评测中,该模型展现出与DeepSeek R1等同量级模型相当甚至更优的结果。而在面向专业知识的医学问答测试MedQA与MedMCQA中,模型分别取得87.1和80.8的高分,表现出对复杂专业知识的理解与应用能力。
随着训练层数的加深,模型中的专家模块逐步呈现出“任务特化”的倾向。不同任务中的输入倾向于被路由到特定专家,形成语义上的聚合与分化,这种“专家选择”的内在机制,正是MoE架构能够在大规模训练中兼顾效率与表达能力的关键所在。
Pangu Ultra MoE的成功落地不仅展示了华为在AI芯片、系统优化和大模型训练上的全栈能力,也为国产AI生态提供了实践样本。其训练系统完全基于国产硬件、自主研发的并行框架和优化策略,打破了对传统GPU方案的依赖,为日后更多场景下的AI本地部署提供了新的可能。
参考资料:https://arxiv.org/pdf/2505.04519
 豫公网安备41010702003375号
豫公网安备41010702003375号