
剖开模型的推理黑箱,同济大学等联合研究发现:SFT“喂知识”,RL“教思考”
![]() 前沿资讯
1749454817更新
前沿资讯
1749454817更新
![]() 0
0
大语言模型在逐步推理与任务解决方面展现出强劲实力,然而,现有评估方式主要集中在“最终答案是否正确”这一维度,缺乏对模型思维过程的深入理解。为此,美国加州大学圣克鲁兹分校、斯坦福大学与同济大学的研究人员提出了一套全新的分析框架,试图从更细粒度的角度审视模型的推理行为,聚焦模型在“获取知识”与“进行推理”两个层面上的表现差异。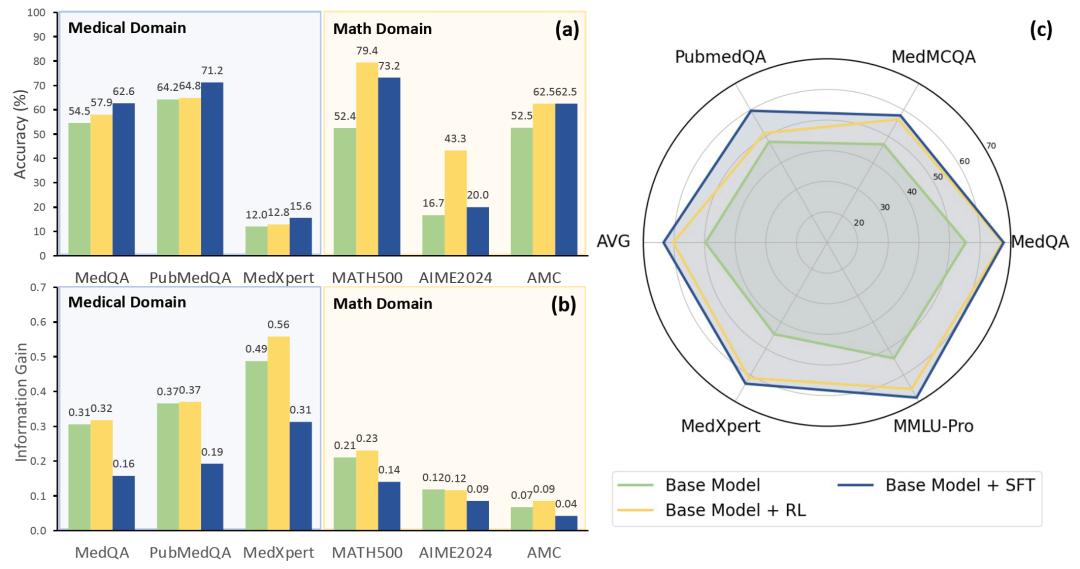
研究团队引入了两个核心指标:知识指数(Knowledge Index, KI)和信息增益(Information Gain,InfoGain),分别用于评估模型在推理过程中使用的事实知识是否准确,以及每一个推理步骤是否有效地推进了问题解决。这两个指标共同构成了对语言模型“思维轨迹”的互补评估方式,为以往模糊不清的“黑箱推理”提供了更明确的剖析工具。
在实验设计上,研究人员选用了两个公开模型作为基础:Qwen2.5-7B(Qwen-Base)以及推理强化版本DeepSeek-R1-Distill-Qwen(Qwen-R1)。通过监督微调(SFT)和强化学习(RL)两种训练方式,分别对这两个模型进行了训练,并在医学与数学两个高度对比的任务领域中进行了系统评估。医学领域所用的数据集包括MedMCQA、PubMedQA、MedQA-USMLE等标准考试题目,而数学领域则涵盖AIME、MATH500、AMC、USAMO等典型高难题库。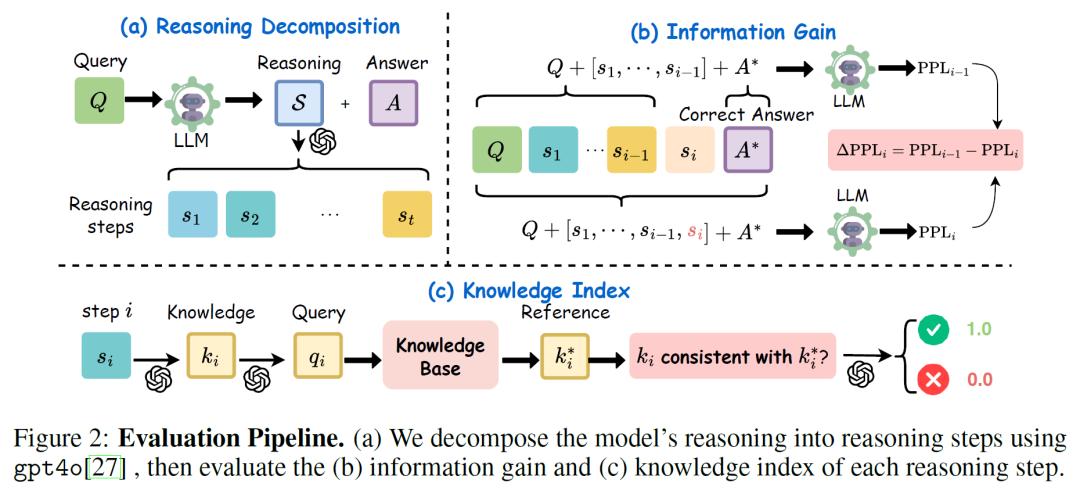
实验结果清晰地展示了“知识”与“推理”在不同任务中的作用强弱差异。在医学任务中,模型是否具备正确的医学知识决定了能否得到正确的答案,知识指数与准确率的相关性高达0.998,远高于信息增益。而在数学任务中,模型的推理能力更为关键,信息增益与准确率的相关性相对更高,表明这些任务依赖模型本身的逻辑推导能力。
进一步分析显示,监督微调(SFT)对提升模型的知识掌握能力最为显著,在医学任务中带来了平均超过13个百分点的知识指数提升。但与此同时,SFT也引入了冗长甚至重复的推理步骤,使得信息增益平均下降近39%,推理路径不再高效。相比之下,强化学习(RL)虽然在增加新知识方面不及SFT,但却能有效裁剪错误或无关的知识点,优化推理流程,并同时带来轻微的知识指数提升。这种训练方式更像是在“教模型思考”,而SFT则偏向于“灌输知识”。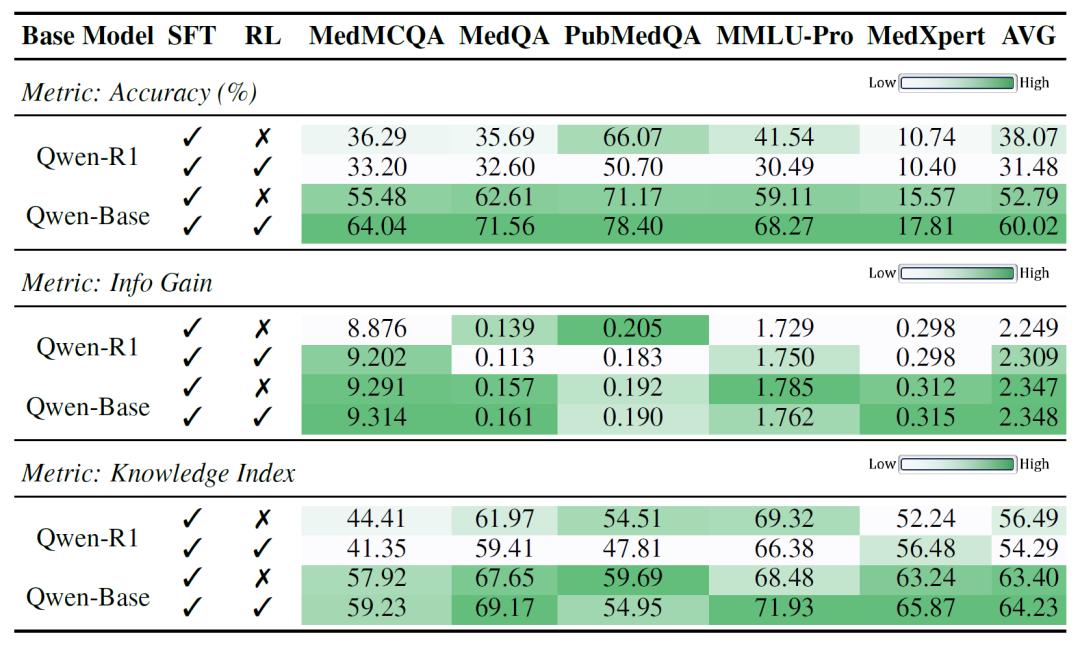
一个典型的医学问答案例中,SFT训练后的模型虽然整体推理逻辑清晰,知识表达准确,却最终选择了副作用较大的药物作为治疗方案,忽视了更安全、常规的首选药物。揭示出模型在真实情境下的决策能力仍有不足。而经过RL优化的模型在同样情境下能避开该决策误区,做出更合理的选择。这一对比说明,仅有正确的推理步骤或知识点并不足以确保安全可靠的结论,模型是否能做出正确的“判断”才是关键。
研究者指出,这种“知识驱动”与“推理驱动”的任务差异,决定了不同训练策略的适用性。在医学任务中,SFT的效果明显优于RL,说明医学问题对事实性知识依赖更强。而在数学任务中,RL训练后的模型反而更具优势,强化训练能够更有效提升推理能力,使模型更具逻辑性与高效性。
参考资料:https://arxiv.org/abs/2506.02126
 豫公网安备41010702003375号
豫公网安备41010702003375号