
Cohere发布企业级多模态大模型Command A Vision,领先GPT-4.1等同类模型
![]() 前沿资讯
1754016555更新
前沿资讯
1754016555更新
![]() 1
1
专注企业级生成式AI的Cohere公司今日正式发布新一代多模态大模型Command A Vision。该模型在图表分析、文档OCR、实景理解等企业视觉任务中刷新行业基准,同时保持低算力需求,可在两张A100或单张H100(4-bit量化)上完成私有化部署,为金融、制造、医疗等受监管行业提供安全可控的AI视觉能力。
Cohere官方测试显示,Command A Vision在DocVQA、TextVQA、OCRBench等关键多模态基准中,性能超越GPT-4.1、Llama 4 Maverick及Mistral Medium 3等主流模型。其突破性表现体现在三大场景:
图表与图纸解析:可提取多语言图表、流程图中的数据,并基于行业知识库生成分析结论,适用于财报解读、工程图纸审阅等场景。
文档智能处理:通过理解版式结构,从扫描合同、发票、表单中精准提取字段,支持JSON结构化输出,直接对接企业ERP系统。
实景风险识别:在工业巡检、零售陈列分析等场景中,不仅能识别物体,还可识别图像中的空间关系、上下文与细微语义变化。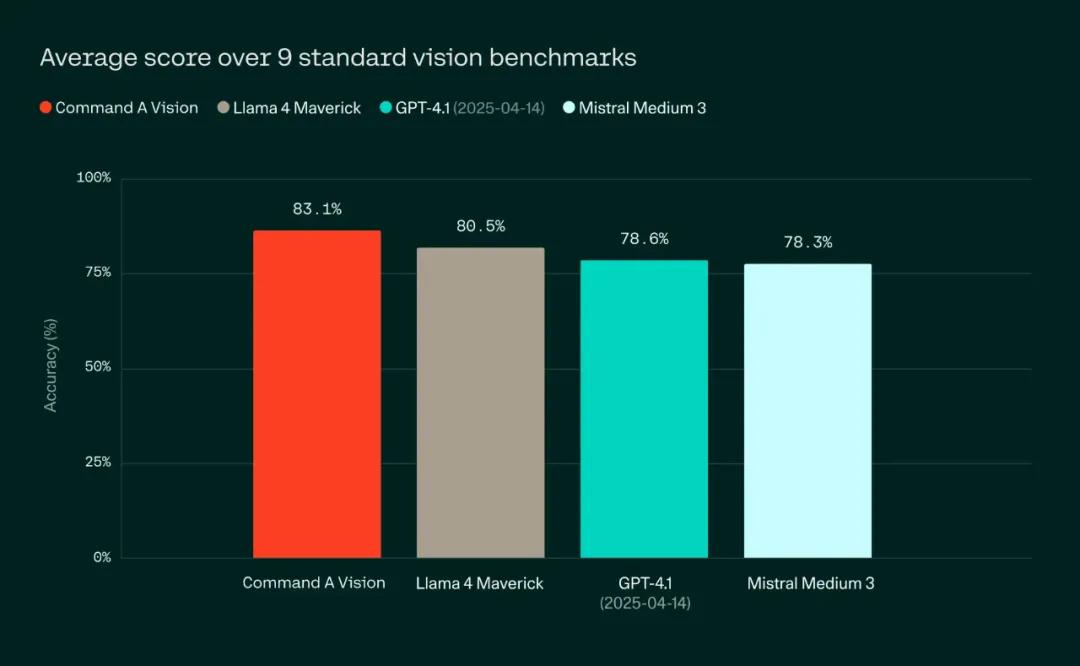
针对企业数据隐私需求,Command A Vision支持灵活、私有化本地部署,仅需两张A100或一张H100 GPU(支持4-bit量化),即可实现生产级运行,特别适用于对数据安全与部署环境有严格要求的金融、医疗、政企等行业。此外,该模型集成了Command A强大的检索增强生成(RAG)能力,支持多语言处理,在文本和图像之间实现更丰富、更精准的上下文关联,提升业务智能洞察能力。
富士通专业服务总监Jeffrey English表示,“Command A Vision的发布是企业AI迈向视觉理解时代的重要一步。我们已经看到它在处理复杂视觉任务中的高效表现,不仅简化了工作流程,更让我们对AI的未来能力充满想象。”。甲骨文基础设施行业高级副总裁Mark Webster则指出:“在建筑行业的测试中,Command A Vision在处理复杂文件如留置权豁免、施工图纸等方面表现出色。基于AI的自动化数据提取将极大地提升项目管理效率,降低风险与成本。”
即日起,Command A Vision已在Cohere平台向企业客户开放,研究用途版本同步上线Hugging Face。
参考资料:https://cohere.com/blog/command-a-vision?s=09
 豫公网安备41010702003375号
豫公网安备41010702003375号