
谷歌开源LangExtract:一键解锁非结构化文本的“数据金矿”
![]() 前沿资讯
1754029301更新
前沿资讯
1754029301更新
![]() 1
1
在数据爆炸的今天,高价值数据往往沉寂于医疗病历、法律卷宗、用户反馈或新闻原稿等大量非结构化文本之中。为彻底解决“人工整理耗时、脚本定制易错、通用大模型易飘”的三重痛点,谷歌正式推出开源Python库LangExtract,该工具基于Gemini大模型,面向开发者提供一次性、可溯源、可扩展的结构化抽取方案。
LangExtract具备一系列面向开发者与专业领域用户的信息抽取优势:
源文本精准定位:每个抽取实体都精确映射至原文中的字符位置,实现高可追溯性与透明度,便于人工校验与审计。
结构化输出保障一致性:通过“少样本示例+任务提示”机制,结合Gemini等支持“受控生成”的模型,输出结果严格遵循用户定义的结构化模式。
长文本优化处理能力:内建分块处理、并行抽取、多轮遍历等机制,优化百万级Token上下文下的信息回忆率,提升复杂文档的抽取效果。
交互式可视化展示:支持一键生成自包含的HTML页面,直观呈现抽取结果与原文关系,便于演示与质量评估。
多模型灵活兼容:兼容Gemini等云端模型,同时支持本地开源模型接入,适配不同部署环境与算力条件。
领域适配无需微调:无需额外训练,通过少量示例即可快速适配医学、金融、法律、工程等专业场景。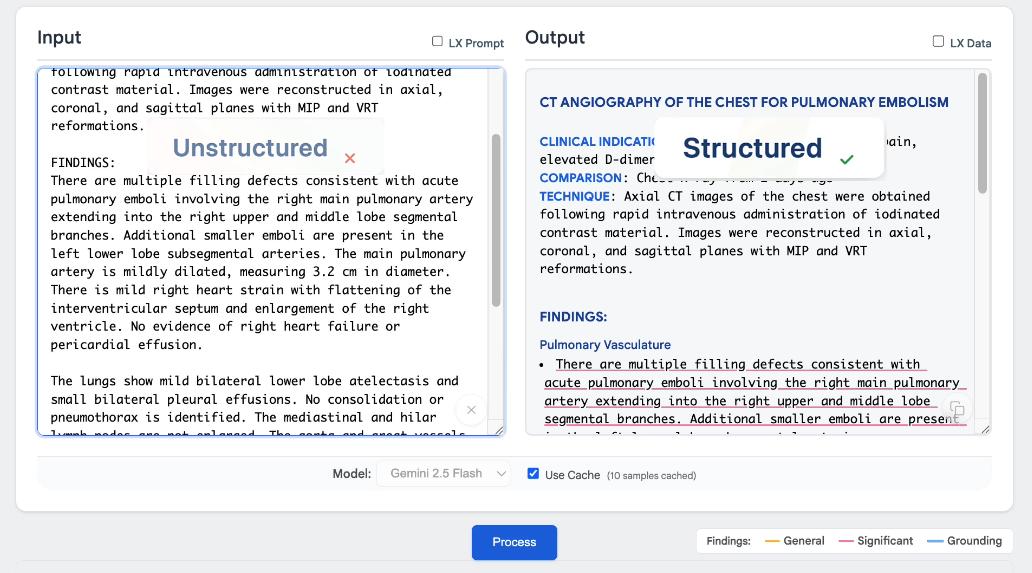
官方示例展示了LangExtract如何从莎士比亚《罗密欧与朱丽叶》的文本中提取人物、情感与关系,并以交互式方式呈现结果。更进一步,LangExtract也可应用于医学临床文本处理,如自动识别药物名称、剂量与相互关系。此外,谷歌还在Hugging Face平台上线了专为结构化放射学报告打造的演示系统“RadExtract”(Demo演示地址:https://google-radextract.hf.space),展示该库在医疗专业领域的实际应用潜力。
详细的使用文档、示例代码与可视化演示已在项目GitHub仓库上线。无论是处理学术文本、法律合同,还是客户反馈与新闻数据,LangExtract都提供了一条通往结构化信息的“快速通道”。
参考资料:https://developers.googleblog.com/en/introducing-langextract-a-gemini-powered-information-extraction-library/
 豫公网安备41010702003375号
豫公网安备41010702003375号