
Nous Research最新研究:开源模型计算成本优势“受限”,Token消耗高出闭源模型10倍
![]() 前沿资讯
1755248686更新
前沿资讯
1755248686更新
![]() 1
1
由Nous Research发布的一项最新研究报告显示,在同类推理任务上,开源大模型消耗的token数量普遍高于闭源模型,最高可达10倍。
报告指出,推理模型通过测试时扩展与强化学习,学会在任务中生成更长、更细的思考链条,以提升解题能力。过去,行业更关注“模型智能与单位成本”的帕累托曲线,而很少关注“为得到同样答案究竟消耗了多少tokens”。随着应用落地与成本压力上升,“思考效率”正成为一项重要指标。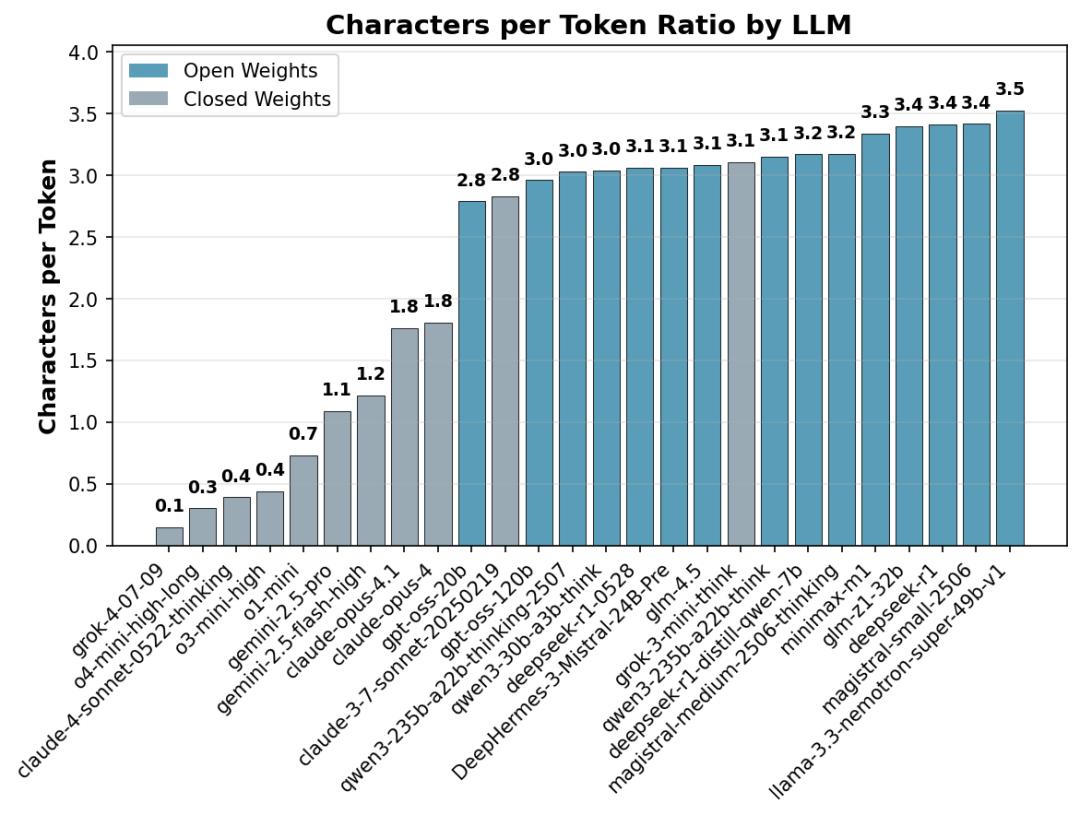
研究团队对50余款主流大语言模型进行了横向对比,测试范围涵盖常识、数学、逻辑三大场景。在5道“一句话即可答完”的常识题中,闭源阵营的OpenAI、Claude仅用几十个token就能给出答案,而部分开源模型却生成上千token的“思考过程”。以Magistral系列为例,其token消耗量达到最优闭源模型的10倍,即便在数学、逻辑两类需要“深思熟虑”的任务中,开源模型仍平均多用1.5–3倍token。
报告以7月OpenRouter实时报价测算:在知识问答场景,部分开源模型的单次调用成本反而比闭源旗舰更贵。
值得注意的是,OpenAI新发布的开源权重模型gpt-oss-120b在全部测试中均以“最短思考链”拿下开源阵营第一名,甚至逼近闭源模型的效率。研究者认为,其极度压缩的链式思考(CoT)为行业提供了可复用的优化范本。
为何差距如此之大?报告分析,闭源模型普遍采用“隐式思考”,即只向用户展示摘要或最终答案,而开源模型往往要输出完整的思考过程。研究通过字符与token的比例推断:OpenAI、Claude在聊天模式下仅给出30%的思考摘要,而DeepSeek、Qwen等开源模型则完整呈现100%思考链。
业内观察人士指出,随着大模型进入“价格战”下半场,token效率将成为新的技术壁垒。报告建议开源社区借鉴gpt-oss的做法,引入“思考密度优化”机制,在保持推理质量的同时缩短输出长度,以降低延迟、节省算力。
目前,完整数据集与复现脚本已在GitHub公开。研究人员呼吁更多开发者加入测试,以共同推动高效推理模型的标准化评估。
参考资料:https://nousresearch.com/measuring-thinking-efficiency-in-reasoning-models-the-missing-benchmark/;
 豫公网安备41010702003375号
豫公网安备41010702003375号