
腾讯开源发布HunyuanImage 2.1,图像生成能力接近商业级水准
![]() 前沿资讯
1757488371更新
前沿资讯
1757488371更新
![]() 0
0
腾讯正式推出新一代开源文生图模型HunyuanImage 2.1。该版本最大的亮点,是能高效生成2K(2048×2048)分辨率的高清图像,同时在语义对齐和细节控制方面有明显提升。
在整体架构上,HunyuanImage 2.1采用了“两步走”的方案。第一步是基础的文生图模型,内置双文本编码器:一个是多模态语言理解模型,用来提升画面与文字的对应度。另一个是支持多语言和字符感知的编码器,能更好地处理不同语言环境下的文本生成。第二步则由精修模型完成,它进一步改善画质、减少伪影。
在训练环节,团队采用了分层语义标注,并通过OCR和知识增强手段弥补传统描述器在复杂语义上的不足。结合人类反馈强化学习,模型在结构美感和表现力上也得到了提升。
腾讯还引入了一个PromptEnhancer模块,用于自动优化用户的提示词,让生成结果更贴近预期。同时,新的蒸馏方法让推理更高效,只需少量采样步骤就能得到高质量图像。
从评测数据看,HunyuanImage 2.1在开源模型中语义对齐表现最佳,甚至已经接近一些闭源商用产品。
在SSAE(结构化语义对齐评测)中,研究团队设置了3500个关键点,覆盖12个大类,用来考察生成图像与文字描述的对应度。评测由多模态语言模型自动打分,结果显示,HunyuanImage 2.1在开源模型中表现最优,图文对齐的准确率仅比商业闭源模型GPT-Image略低。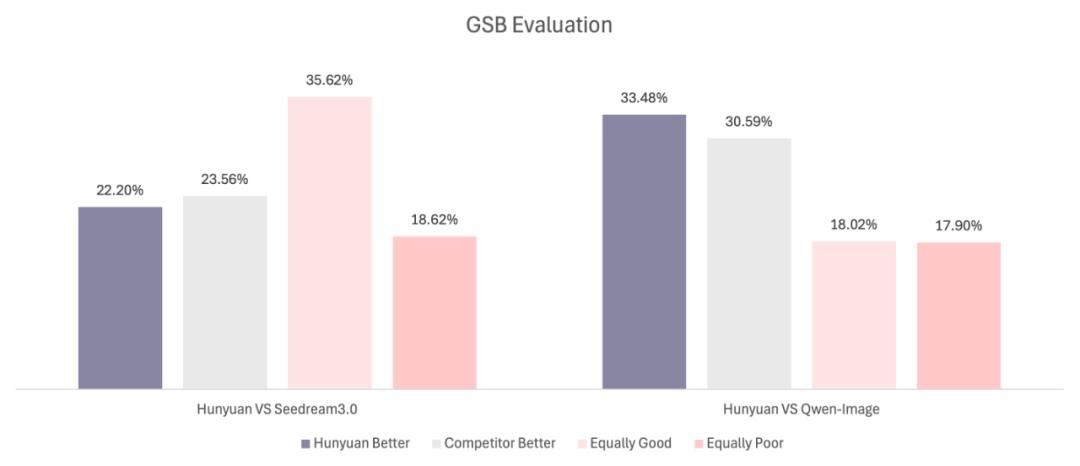
在另一项GSB对比评测中,腾讯邀请了超过100位专业评审,针对1000个提示词生成的图像进行主观打分。结果显示,HunyuanImage 2.1相较于闭源的Seedream 3.0仅略逊一筹(-1.36%),但在与开源的Qwen-Image对比时则有明显优势(+2.89%)。表明该模型不仅站稳了开源阵营的前列,也逐步缩小了与商业模型之间的差距。
HunyuanImage 2.1支持多种图像比例,原生兼容中英文提示词,能够生成包含多物体、复杂场景的高清画面。对于需要在研究、创作或应用层面使用高质量开源图像生成方案的开发者来说,该版本为此类人群提供了新的选择。
根据官方信息,运行HunyuanImage 2.1需要支持CUDA的英伟达显卡,并至少具备59GB显存才能在单批次下生成2048×2048分辨率的图像。系统方面,目前支持Linux环境。如果显存不足,用户也可以通过CPU卸载功能降低GPU占用,但速度会有所下降。
相关链接:
腾讯混元官网:https://hunyuan.tencent.com/image
Github:https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
Hugging Face:https://huggingface.co/tencent/HunyuanImage-2.1
参考资料:https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
 豫公网安备41010702003375号
豫公网安备41010702003375号