
IBM推出Granite 4.0 Nano系列模型,可直接在浏览器本地运行
![]() 前沿资讯
1762067484更新
前沿资讯
1762067484更新
![]() 0
0
导读:IBM推出了轻量级、可本地运行的Granite 4.0 Nano系列模型。这些模型不仅能在笔记本甚至浏览器中直接跑起来,还在性能测试中超过不少“大块头”模型。
IBM发布了四个全新的Granite 4.0 Nano模型,参数量从3.5亿到15亿不等,主打“能在任何地方运行”。
- 350M版本能在普通笔记本CPU上运行,只需8~16GB内存;
- 1.5B版本也只需一块6~8GB显存的显卡即可流畅推理,甚至在CPU模式下通过内存交换也能完成计算。
这些模型分为两大架构路线:混合型(Hybrid-SSM) 与 标准Transformer型,兼顾性能与兼容性。
| 模型名称 | 参数规模 | 架构类型 | 特点与应用场景 |
|---|---|---|---|
| Granite-4.0-H-1B | 约15亿 | Hybrid-SSM | 平衡性能与延迟表现,专为边缘设备优化,在指令跟随与函数调用任务中表现突出。 |
| Granite-4.0-H-350M | 约3.5亿 | Hybrid-SSM | 可在普通笔记本CPU上运行,无需GPU;适合轻量级AI应用与浏览器端部署。 |
| Granite-4.0-1B | 实际接近20亿 | Transformer架构 | 与混合型1B版本性能相近,但兼容性更强,适合尚未支持Hybrid架构的开发环境。 |
| Granite-4.0-350M | 约3.5亿 | Transformer架构 | 极致轻量,可快速加载和推理,适合移动端、本地工具或快速原型搭建。 |
IBM表示,小并不代表弱,关键在于架构设计是否聪明。这些模型面向边缘设备、笔记本和本地环境设计,在计算受限的情况下仍能保持高性能和低延迟。
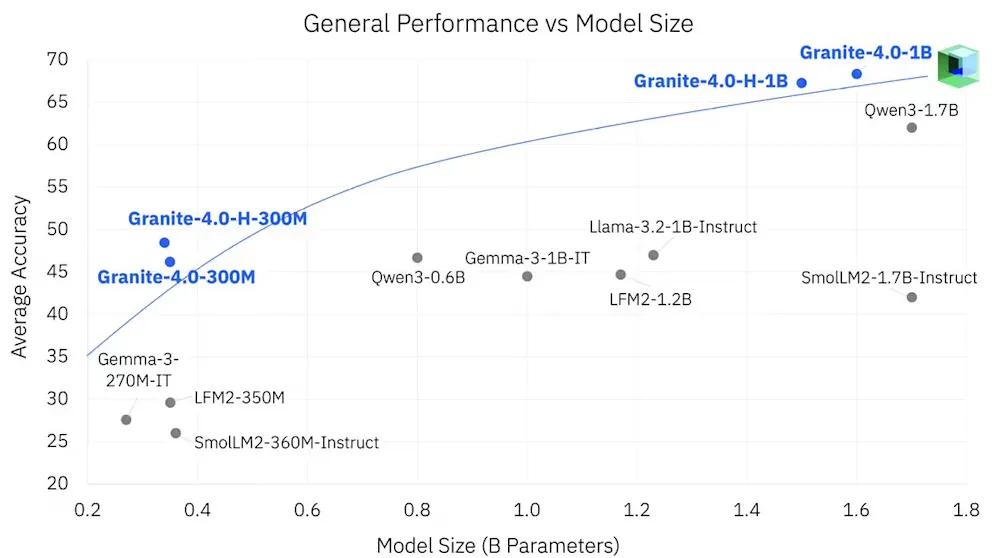
在基准测试中,Granite 4.0 Nano的表现令人惊喜:
- Granite-4.0-H-1B在指令理解测试IFEval中得分78.5,超过阿里巴巴的Qwen3-1.7B;
- 在函数调用测试BFCLv3中得分54.8,同级中居首;
- 安全性测试中得分超过90%,在同级模型中名列前茅。
整体来看,Granite-4.0-1B在知识、数学、代码和安全四大领域的平均得分达到
68.3%,在1B级别模型中属于顶尖水平。
AI圈一直流行着“模型越大越强”的理念。但随着研究深入,人们发现,架构优化、训练质量和任务定向微调,往往能让小模型也发挥“大智慧”。
IBM看准了这个趋势,通过发布性能出众的开源小模型,给出了与封闭式AI平台完全不同的路线。
Granite产品市场负责人艾玛(Emma)在AMA问答中透露,他们正在训练更大版本的Granite 4.0,并计划推出专注推理任务的“思考型模型”,还会发布微调方案和完整训练论文。
开发者们反响热烈。有人评论说:“如果1B模型能保持这样的稳定输出,这真的是个工作级利器。”也有人表示:“Granite Tiny已经是我网页搜索的主力模型了,Nano看起来更值得试试。”
参考资料:https://venturebeat.com/ai/ibms-open-source-granite-4-0-nano-ai-models-are-small-enough-to-run-locally
 豫公网安备41010702003375号
豫公网安备41010702003375号