
Mistral推出OCR 3:手写、表格、扫描件一次搞定
![]() 前沿资讯
1766224495更新
前沿资讯
1766224495更新
![]() 0
0
导读:Mistral AI 正式发布 OCR 3,在官方测试中,整体胜率达到 74%,明显领先上一代和多数同类方案。支持手写内容识别,还能还原表格和文档结构,同时,速度和价格也被压到行业新低。
如果你平时接触过 OCR,大概率会有一种感觉:能“识字”的很多,但能“看懂文档”的却不多。这正是 Mistral AI 这次想解决的问题。
Mistral AI 最新发布了 Mistral OCR 3,官方给它的定位很清晰:不是做一个通用型识别工具,而是专门为扫描 PDF、复杂表格、表单和手写内容服务。
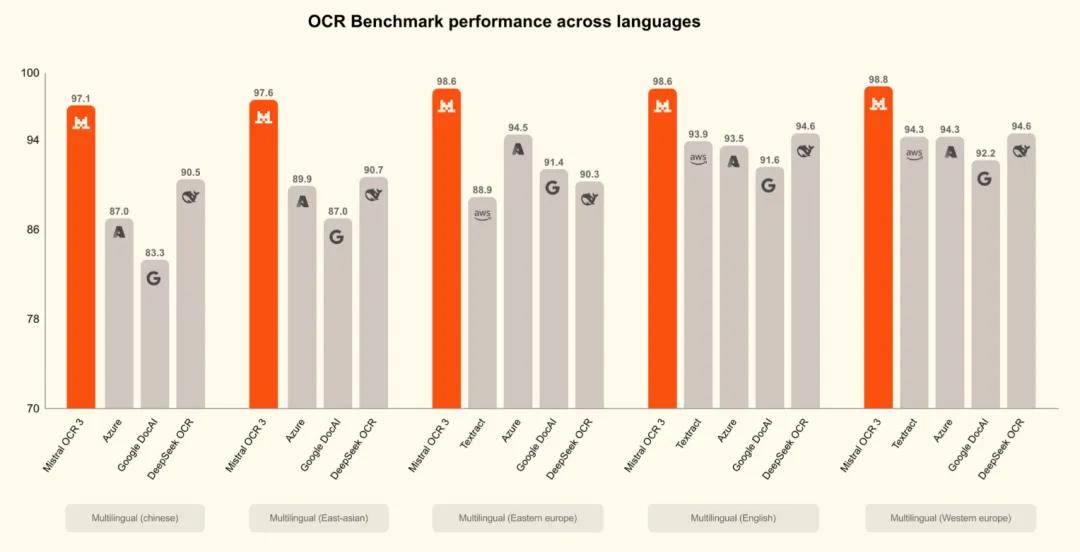
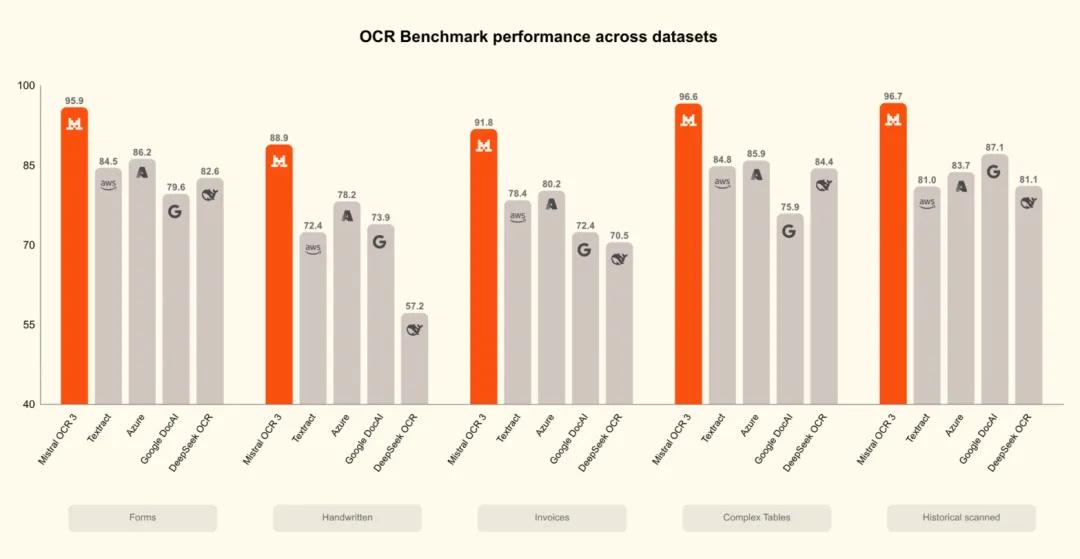
从官方公布的数据来看,OCR 3 在多类真实业务文档测试中,相较 Mistral OCR 2 和多家企业级 OCR 方案,整体胜率达到 74%。这类测试主要集中在低质量扫描件、表单、复杂表格以及手写内容,也是 OCR 最容易“翻车”的地方。
更直观的是性能指标:单节点每分钟可处理约 2000 页文档,价格则被压到每 1000 页 2 美元,通过批处理接口还能降到 1 美元。在当前 OCR API 市场里,这个定价已经相当激进。
和传统 OCR 最大的不同在于,OCR 3 并不只输出纯文本。官方强调,它会尽量保留原始文档结构:
- 表格会被重建为 HTML 结构,包含合并单元格、行列层级
- 普通文本可以输出为 Markdown
- 最终结果可以直接转成结构化 JSON,方便后续系统处理
在官方演示中,一封字迹潦草的“圣诞老人来信”被完整解析成结构化内容,手写部分的还原度也明显高于常见 OCR。这也是 OCR 3 被重点强调的一点:原生支持手写内容,而不是“勉强能看”。
官方给出的判断是:OCR 正在从“读文字”,走向“理解文档结构”。 这一步,对后续的知识抽取、检索、自动处理流程影响很大。
在发布节奏上,Mistral 这次并没有“画饼”:
- 开发者可以直接通过 API 调用模型(mistral-ocr-2512)
- 普通用户则可以在 Mistral AI Studio 的 Document AI Playground 中体验,支持拖拽上传 PDF 或图片,一步生成文本或 JSON
官方也确认,OCR 3 与 OCR 2 完全兼容,老项目迁移成本不高。
发布后,OCR 3 很快在 Reddit 引发讨论。
不少用户认为,它在人文研究、历史档案数字化方面潜力很大,有人提到:“把大量手写信件、历史文献变成可搜索文本,这本身就很有价值。”
也有用户把它用在日常工作流里,比如把 PDF 论文转成纯文本,再交给工具快速筛选是否值得精读,这类“重排 + 清洗”的需求,被认为非常实用。
综合官方信息和社区反馈,Mistral OCR 3 的价值并不在于“识别准不准”这一单点指标,而在于:它试图把海量“死文档”,直接转成结构化、可复用的数据资产。
对于企业档案、财务单据、历史文献、扫描资料来说,这一步一旦成本和稳定性过关,带来的变化会是长期的。
参考资料:https://mistral.ai/news/mistral-ocr-3
 豫公网安备41010702003375号
豫公网安备41010702003375号