
Qwen-Image-Layered发布:AI图片编辑可以像PS一样分层改
![]() 前沿资讯
1766400355更新
前沿资讯
1766400355更新
![]() 0
0
导读:Qwen-Image-Layered 带来一种全新的 AI 图片编辑思路:不是整体重生成,也不是涂掩码,而是把图片直接“拆成图层”。每一层都能单独改、单独移动、单独删,其他部分完全不受影响。
在 AI 生图越来越常见的今天,“好看”已经不再是唯一标准,能不能精确修改、反复修改、还不出问题,正在成为新的门槛。
今天,通义千问团队宣布推出全新的图像生成与编辑模型:Qwen-Image-Layered。其核心思路是:不再把图片当成一整块像素,而是直接拆成多个可以独立编辑的图层。

在 Qwen-Image-Layered 之前,主流 AI 图片编辑大致有两种路线:
- 全局重生成:一句提示词,整张图重新画。改得多,但随机性也大,原本没想动的地方往往一起“翻车”。
- 掩码式局部编辑:圈住一块再改,确实更稳,但遇到遮挡、边缘模糊时,常常不好控制。
Qwen-Image-Layered 走的是第三条路:直接把图片“拆解”。
模型会把一张普通的 RGB 图片,自动分解成多个语义上彼此独立的 RGBA 图层。每一层不仅有颜色信息,还有透明度,就像把一张图片“剥洋葱”,一层一层拆开。
结果就是:改一层,只影响这一层。无论是重新着色、替换人物、改文字,还是删除物体,其他内容都能原样保留。
为了实现这一目标,Qwen-Image-Layered 在架构上做了几件关键的事:
- RGBA-VAE:让普通 RGB 图片和带透明度的 RGBA 图层,进入同一个潜空间。这一步解决了图层边界模糊、不同图层分布不一致的问题。
- VLD-MMDiT 架构:图层数量不再受限。不管是 3 层、8 层,还是更多图层,都可以一次性处理,图层之间还能通过注意力机制协同工作。
- 多阶段进化训练:模型先学会生成单图,再学会生成多层,最后学会“拆解任意图片”。把生成能力,转化成了真正的理解能力。
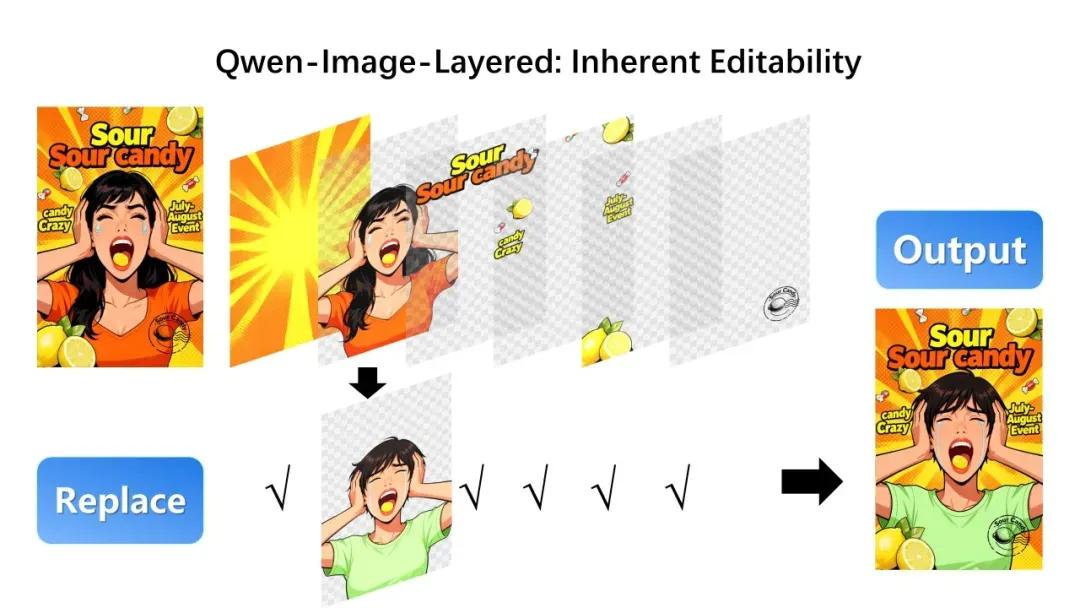
在分层完成之后,编辑方式会变得非常直观:
- 只给某一层重新上色,其它内容完全不动
- 把图中的女孩替换成男孩,而背景、光影保持一致
- 单独修改图片里的文字内容
- 干净地删除多余物体,不留“修补痕迹”
- 自由缩放、移动物体,不出现拉伸和失真
更进一步,图层数量是可变的。 同一张图,既可以拆成 3 层,也可以细化成 8 层,甚至,某一个图层还能继续被递归拆解,实现更精细的编辑控制。
从结果来看,图片不再只是像素的集合,而是一个可以被理解、被拆分、被反复编辑的结构化对象。这让 AI 图片编辑第一次真正具备了“稳定、可控、可迭代”的基础,PS这次可是真“危”了。
体验地址:https://www.modelscope.cn/studios/Qwen/Qwen-Image-Layered
参考资料:https://mp.weixin.qq.com/s/3yXOWhUuzVajlyySg7J9Hw
 豫公网安备41010702003375号
豫公网安备41010702003375号