
智谱AI重磅发布GLM-Image:刷新文本渲染基准测试纪录
![]() 前沿资讯
1768381127更新
前沿资讯
1768381127更新
![]() 0
0
【导读】智谱AI正式发布GLM-Image,定位为首个开源的工业级离散自回归图像生成模型。该模型采用自回归+扩散混合架构,在文本渲染和知识密集型图像生成任务中表现优异,CVTG-2k基准测试中NED指标达0.9557,超越所有主流闭源模型。
GLM-Image采用创新的混合架构设计,将自回归模块与扩散解码器有机结合。自回归部分基于GLM-4-9B-0414初始化,拥有90亿参数;扩散解码器遵循CogView4架构,采用单流DiT结构,拥有70亿参数。这一设计使模型既具备强大的全局语义理解能力,又能生成高保真度的视觉细节。
在图像生成质量上,GLM-Image与主流潜扩散模型相当,但在文本渲染和知识密集型生成场景中展现出显著优势。除文生图任务外,GLM-Image还支持图像编辑、风格迁移、身份保持生成等丰富的图生图应用。

三大核心突破:
视觉Token策略:GLM-Image采用语义-VQ作为主要分词策略,相比传统VQVAE Token具有更优的收敛特性,为高质量图像生成奠定基础。
渐进式训练:训练过程包含256像素、512像素及512-1024像素混合分辨率三个阶段。结合XOmni分词器的16倍压缩比和扩散解码器32倍上采样因子,最终图像分辨率可达1024×2048像素。为解决高分辨率训练可控性下降问题,团队采用渐进式生成策略,有效提升整体生成质量。
Glyph-byT5文本渲染优化:针对中文字符渲染这一普遍难题,引入轻量级Glyph-byT5模型进行字符级编码,显著提升复杂文本内容的渲染准确性。
性能表现方面,在CVTG-2k文本渲染基准测试中,GLM-Image取得卓越成绩:
- NED(归一化编辑距离):0.9557,位居所有测试模型之首
- 平均单词准确率:0.9116
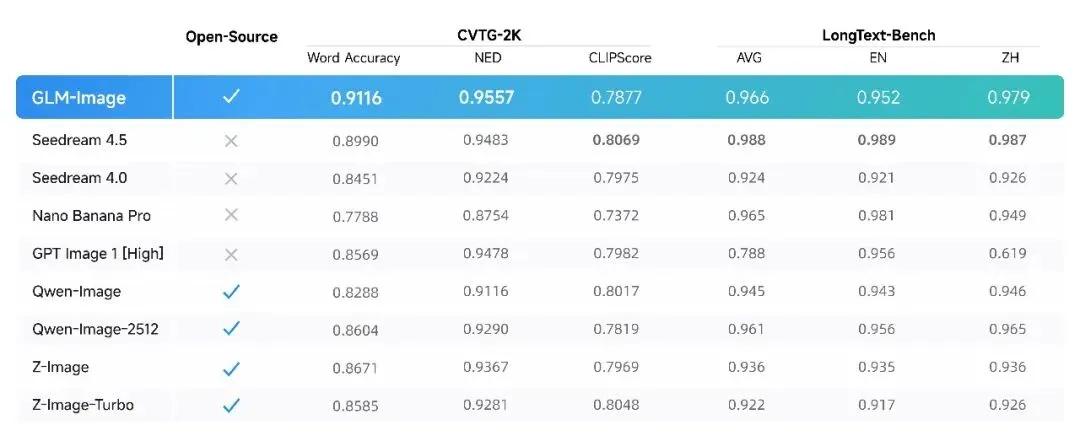
GLM-Image是唯一在该测试中超越闭源模型Seedream 4.5(0.899)的开源模型。在LongText-Bench长文本理解测试中,中文场景达0.9788,英文场景达0.9524,充分证明其处理复杂长文本提示的能力。
CVTG-2k(Complex Visual Text Generation-2K)是当前AI图像生成领域专门针对复杂视觉文本生成任务设计的权威基准测试,用于评估图像生成模型在图像中准确渲染多种文本内容的能力。
GLM-Image的成功,还标志着首个在国产芯片上完成全流程训练的SOTA多模态模型正式诞生。
该模型从数据预处理到大规模预训练,全流程均在昇腾Atlas 800T A2设备上完成,依托昇腾NPU和昇思MindSpore AI框架,通过动态图多级流水下发、高性能融合算子及多流并行等创新技术,全面优化端到端训练流程,成功验证了在国产全栈算力底座上训练高性能多模态生成模型的可行性,为国产AI生态发展树立重要里程碑。
GLM-Image现已在HuggingFace、GitHub等平台开源,开发者可访问以下渠道体验:
- 技术博客:z.ai/blog/glm-image
- HuggingFace:huggingface.co/zai-org/GLM-Image
- GitHub:github.com/zai-org/GLM-Image
- API文档:docs.z.ai/guides/image/glm-image
参考资料:https://z.ai/blog/glm-image
 豫公网安备41010702003375号
豫公网安备41010702003375号