
阿里正式发布万亿参数推理模型Qwen3-Max-Thinking,性能比肩GPT-5.2
![]() 前沿资讯
1769499333更新
前沿资讯
1769499333更新
![]() 0
0
导读:阿里千问最新旗舰推理模型正式发布,总参数量超万亿,在19项权威基准测试中性能可媲美GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro。该模型引入自适应工具调用和测试时扩展两大核心技术,目前已上线Qwen Chat和阿里云百炼API,兼容OpenAI和Anthropic协议。
阿里正式发布千问系列最新旗舰推理模型Qwen3-Max-Thinking。作为通义千问家族中规模最大、能力最强的推理模型,Qwen3-Max-Thinking总参数量超万亿(1T),预训练数据量高达36T Tokens,经过更大规模的强化学习后训练,模型性能实现大幅跃升。
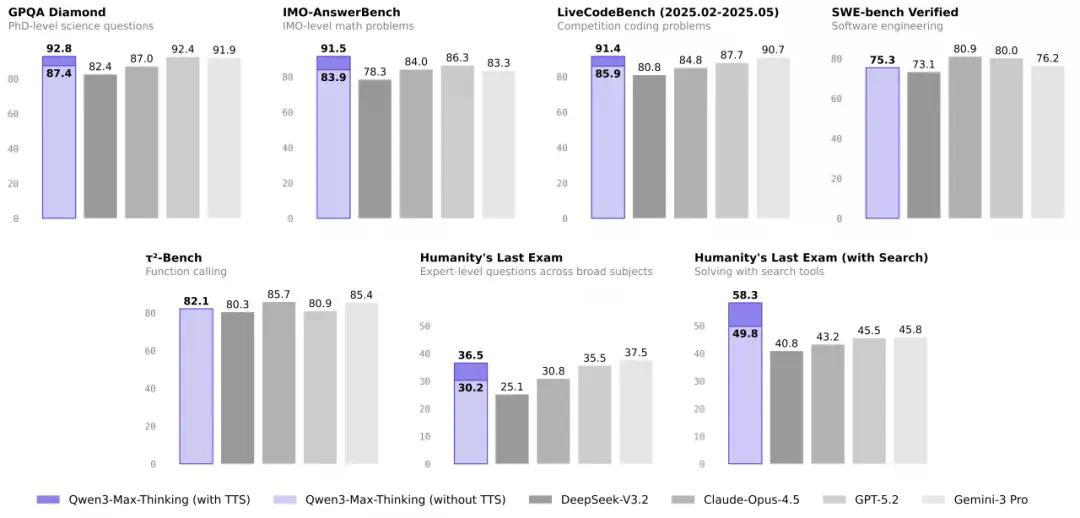
在包含事实科学知识、复杂推理和编程能力在内的19项权威基准测试中,Qwen3-Max-Thinking的整体表现可媲美GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等国际顶尖模型,成为目前最接近国际顶尖水平的国产AI大模型。
Qwen3-Max-Thinking引入两项核心创新,分别从模型能力和推理机制两个维度实现突破:
第一项创新是自适应工具调用能力。 Qwen3-Max-Thinking能够在对话中自主选择并调用其内置的搜索、记忆和代码解释器功能。该能力源于专门设计的训练流程:在完成初步的工具使用微调后,模型在多样化任务上使用基于规则和模型的反馈进行了进一步训练。
实验表明,搜索和记忆工具能有效缓解幻觉、提供实时信息访问并支持更个性化的回复,代码解释器则允许用户执行代码片段并应用计算推理来解决复杂问题。这些功能共同提供了流畅且强大的对话体验,目前已上线Qwen Chat。
第二项创新是测试时扩展技术(Test-Time Scaling)。 测试时扩展是指在推理阶段分配额外计算资源以提升模型性能。阿里提出了一种经验累积式、多轮迭代的测试时扩展策略,该方法限制并将节省的计算资源,用于由"经验提取"机制引导的迭代式自我反思。
相比直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,在相同上下文窗口内能更充分地融合历史信息。在大致相同的token消耗下,该方法持续优于标准的并行采样与聚合方法,在GPQA、HLE、LiveCodeBench、IMO-AnswerBench等关键推理基准上均实现显著提升。
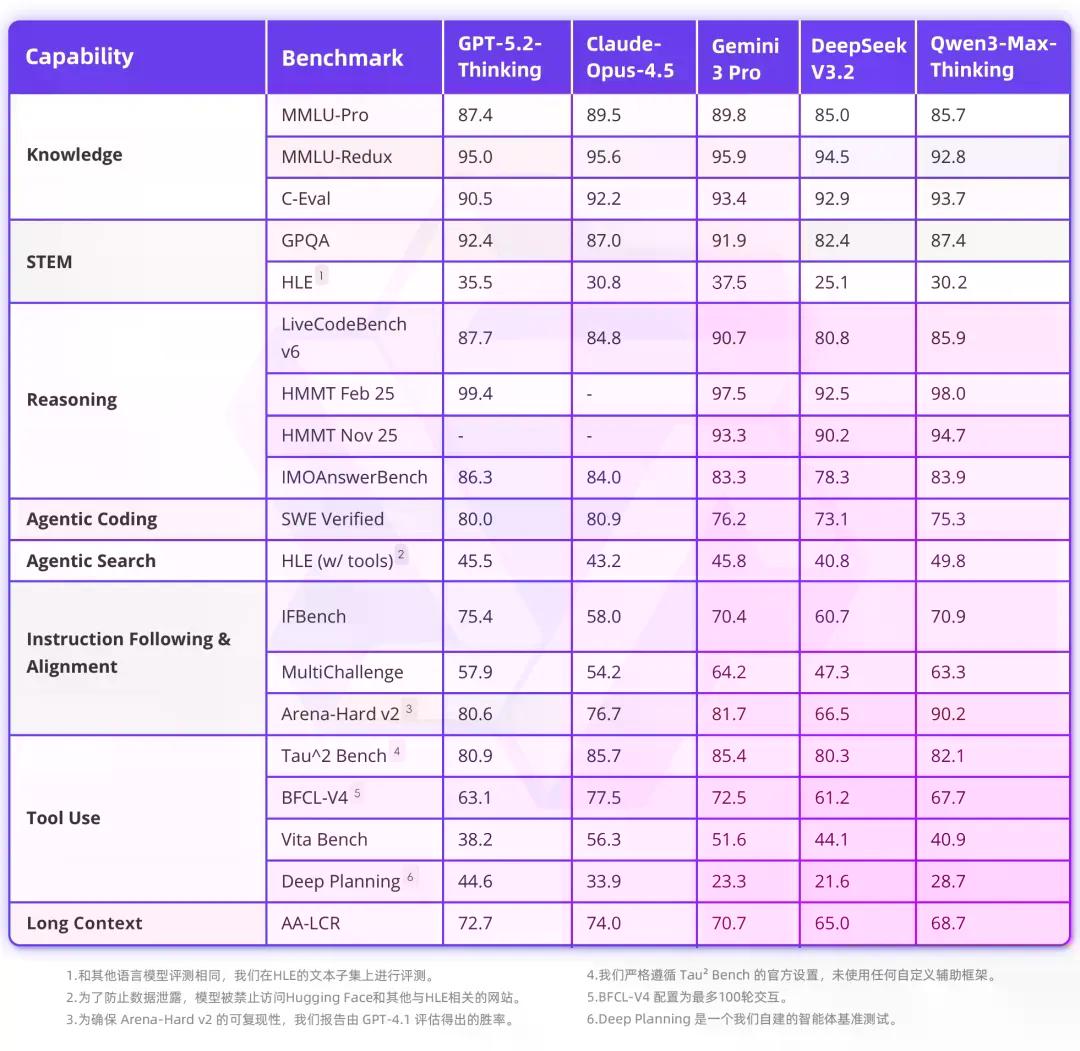
在启用工具的"人类最后的测试"(HLE)基准中,Qwen3-Max-Thinking得分58.3,超越GPT-5.2-Thinking的45.5以及Gemini 3 Pro的45.8,刷新SOTA纪录。在IMO难度级别的IMO-AnswerBench中,该模型也取得了91.5分的成绩,展现出强大的数学推理能力。
Qwen3-Max-Thinking现已上线Qwen Chat(chat.qwen.ai),用户可直接与模型及其自适应工具调用功能进行交互。同时,Qwen3-Max-Thinking的API(模型名称为qwen3-max-2026-01-23)也已开放,用户可通过阿里云百炼平台调用。
阿里云百炼平台已开放API服务,用户注册阿里云账号并开通阿里云Model Studio服务后,进入控制台创建API密钥即可开始使用。
参考资料:https://mp.weixin.qq.com/s/tWpStpBN5i5mZQ9jTiVV9A
 豫公网安备41010702003375号
豫公网安备41010702003375号