
干翻WhisperX?通义千问Qwen3-ASR全线开源:1.7B拳打GPT-4o,0.6B秒切5小时音频
![]() 前沿资讯
1769769347更新
前沿资讯
1769769347更新
![]() 0
0
导读:通义千问团队正式开源Qwen3-ASR系列语音识别模型,包含1.7B和0.6B两个规格的主模型,以及创新的强制对齐模型。该系列支持52个语种与方言识别,在中文、英文、多语种及方言场景下均达到开源SOTA水平。
阿里云通义千问团队正式开源Qwen3-ASR系列语音识别模型。该系列包含两个语音识别模型:Qwen3-ASR-1.7B与Qwen3-ASR-0.6B,以及一个创新的语音强制对齐模型Qwen3-ForcedAligner-0.6B。三个模型的结构、权重及配套推理框架已同步开源,支持GitHub、HuggingFace、ModelScope等主流平台获取。
Qwen3-ASR系列实现了52个语种与方言的语种识别与语音识别支持。具体而言,单一模型即可完成30个语种的识别任务,同时支持22种中文口音与方言,以及多国英文口音。对于有多语言需求的业务场景,这一特性显著降低了多模型切换的工程成本。

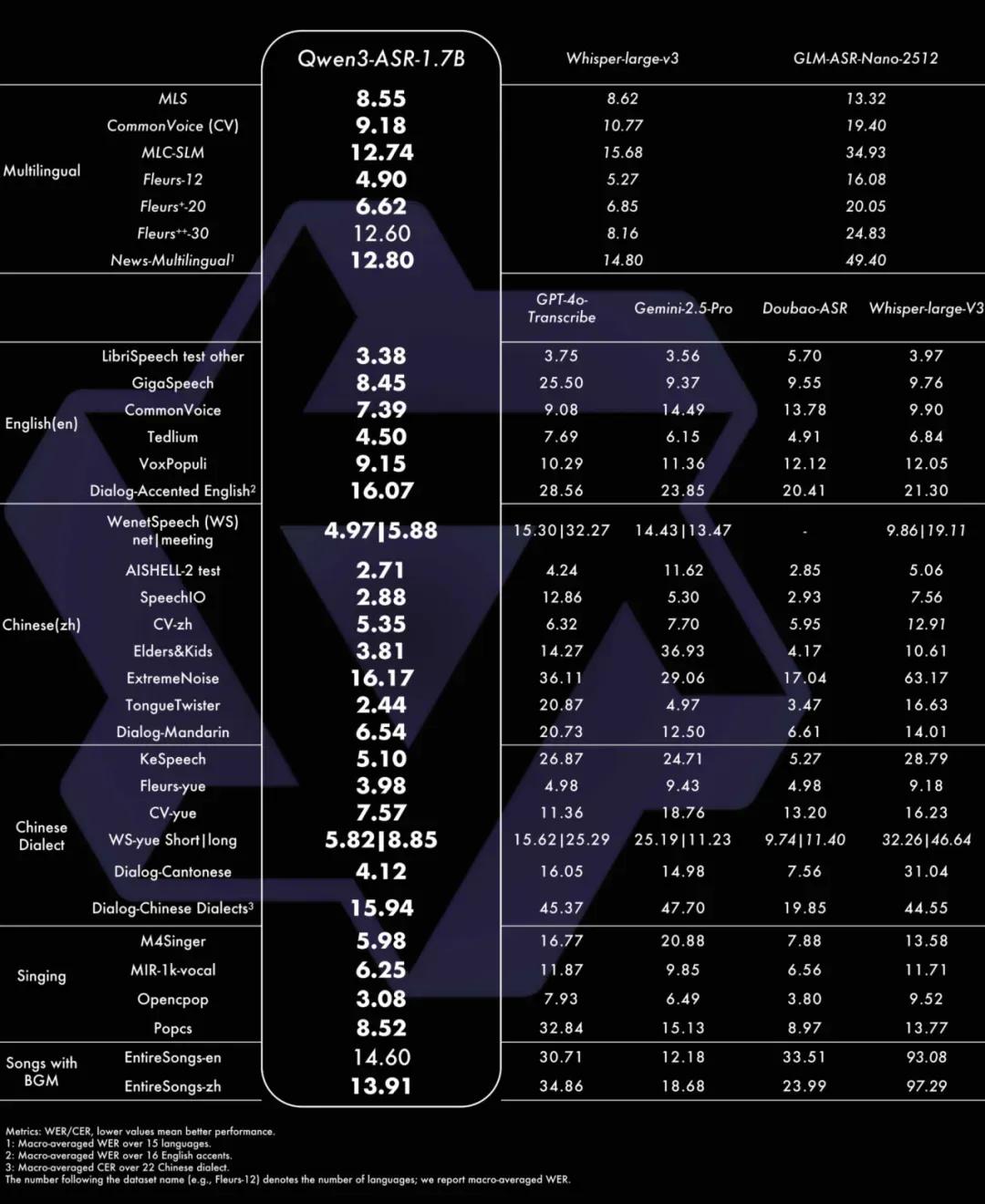
1.7B模型达SOTA,复杂场景稳定性强
Qwen3-ASR-1.7B在多个维度取得了开源领先水平(SOTA)。
在中文场景下,该模型在普通话、粤语及22种地区方言上整体领先商用API与开源模型,尤其在方言识别上,相比Doubao-ASR平均错误率降低20%(15.94 vs 19.85)。在英文场景下,开发团队构建了覆盖16个国家口音的测试集,Qwen3-ASR-1.7B全面优于GPT-4o Transcribe、Gemini系列及Whisper-large-v3。
更具价值的是其在复杂声学环境下的稳定性表现。面对老人/儿童语音、极低信噪比、鬼畜重复等挑战场景,模型仍能保持极低的字/词错误率。此外,该模型还支持带BGM的整首歌中/英文转写,中文/英文平均WER分别达到13.91%和14.60%,填补了开源模型在歌唱识别场景的能力空白。
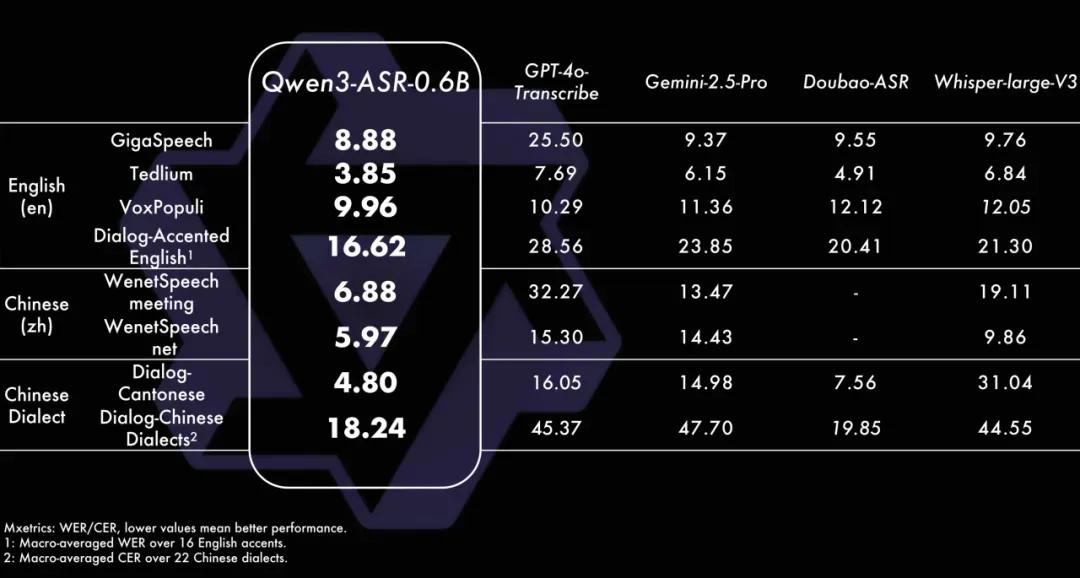
0.6B模型效率惊艳,10秒处理5小时音频
Qwen3-ASR-0.6B则在性能与效率之间实现了良好平衡。
该模型在保证语音识别准确率的前提下,128并发异步服务推理可达2000倍吞吐,10秒钟即可处理5小时以上的音频。单并发下也能实现100倍加速比,适合对延迟敏感的在线服务场景。
两个模型均支持流式/非流式一体化推理,最长可一次性处理20分钟音频,兼顾实时转写与大文件批量处理需求。
强制对齐模型:时间戳预测超越传统方案
此次开源的Qwen3-ForcedAligner-0.6B是一个基于NAR LLM推理的时间戳预测模型,支持11个语种在5分钟以内语音的任意单元精准对齐。
经评测,其时间戳预测精度超越WhisperX、NeMo-ForcedAligner等传统方案,单并发推理RTF达到0.0089,兼顾精度与效率。
除模型权重外,开发团队还开源了全面易用的推理框架,支持基于vLLM的batch推理、异步服务、流式推理、时间戳预测等功能。对于需要快速集成语音识别能力的团队,可直接利用开源工具链完成部署,无需从零构建工程管线。
获取方式:
- GitHub: https://github.com/QwenLM/Qwen3-ASR
- HuggingFace: https://huggingface.co/collections/Qwen/qwen3-asr
- ModelScope: https://www.modelscope.cn/collections/Qwen/Qwen3-ASR
- 在线Demo: HuggingFace Spaces / ModelScope Studio
参考资料:https://mp.weixin.qq.com/s/gE0D-oKWQuES31FVriFDrg
 豫公网安备41010702003375号
豫公网安备41010702003375号