
Qwen3-Coder-Next发布:3B激活参数,本地跑满SWE-Bench Verified 70%+
![]() 前沿资讯
1770189774更新
前沿资讯
1770189774更新
![]() 0
0
导读:Qwen3-Coder-Next 正式发布。这款模型基于 Qwen3-Next-80B-A3B-Base 构建,采用混合注意力与 MoE 架构,推理时仅需 3B 激活参数,却在 SWE-Bench Verified 上突破 70% 大关。
参数规模与推理成本之间的矛盾,向来是端侧部署的核心痛点。模型越大,能力越强,但部署成本也随之飙升。
Qwen3-Coder-Next 基于 Qwen3-Next-80B-A3B-Base 基座,采用混合注意力与 MoE(混合专家)新架构,推理时仅需 3B 激活参数,却能在多个编程智能体基准上与数十亿参数的大模型正面竞争。
这不是「小模型凑合用」的妥协方案,而是一次架构层面的重新思考。
Qwen3-Coder-Next 的训练思路与传统代码模型截然不同。它不依赖单纯的参数扩展来提升能力,而是聚焦于扩展智能体训练信号。团队使用大规模可验证编程任务与可执行环境进行训练,使模型能够直接从环境反馈中学习,而非仅仅预测下一个 token。
具体训练流程包含四个关键阶段:
持续预训练阶段,模型在以代码与智能体为中心的高质量数据上进行密集训练,建立优良的代码理解与生成基础。
监督微调阶段,引入大量高质量智能体轨迹数据,模型学习真实世界中的问题解决路径,而不是人工标注的「理想答案」。
领域专精训练阶段,针对软件工程、质量保障、Web/UX 等垂直领域进行专家级训练,使模型在特定场景下达到专业水准。
能力蒸馏阶段,将多位专家的能力压缩并蒸馏到单一可部署模型中,确保最终产物既有专家深度,又具备通用模型的易用性。
这套配方的目标非常明确:强化长程推理能力、改善工具使用效率、提升从执行失败中恢复的韧性。这三点恰恰是当前开源代码模型的普遍短板,也是现实编程场景中最让开发者头疼的问题。
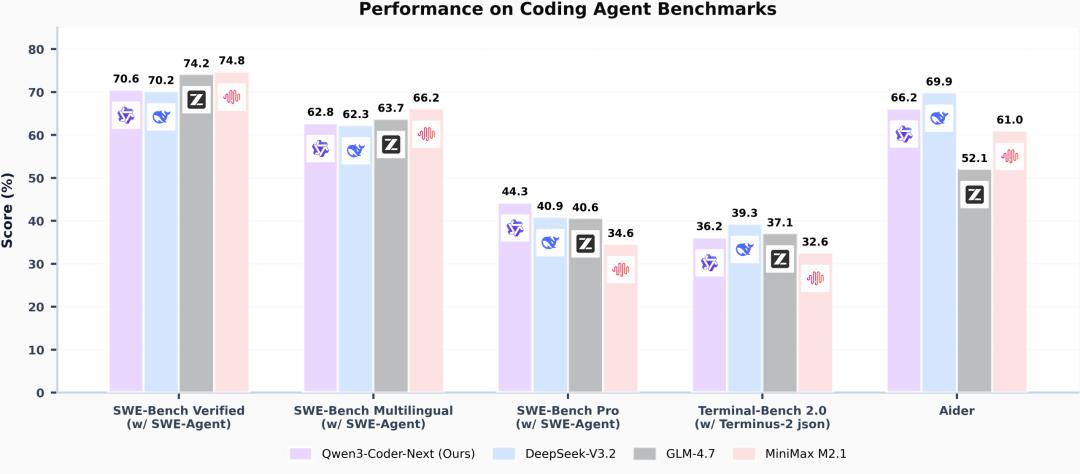
在多个业界公认的编程智能体基准上,Qwen3-Coder-Next 成绩亮眼:
使用 SWE-Agent 框架时,Qwen3-Coder-Next 在 SWE-Bench Verified 上突破 70% ,这一数字在开源模型中属于第一梯队。
在更具挑战性的多语言设置与 SWE-Bench-Pro 基准上,模型同样保持竞争力,证明了其跨语言与复杂任务处理能力。更关键的是,虽然激活参数规模很小,该模型在多项智能体评测上能够匹敌甚至超过若干更大的开源模型。
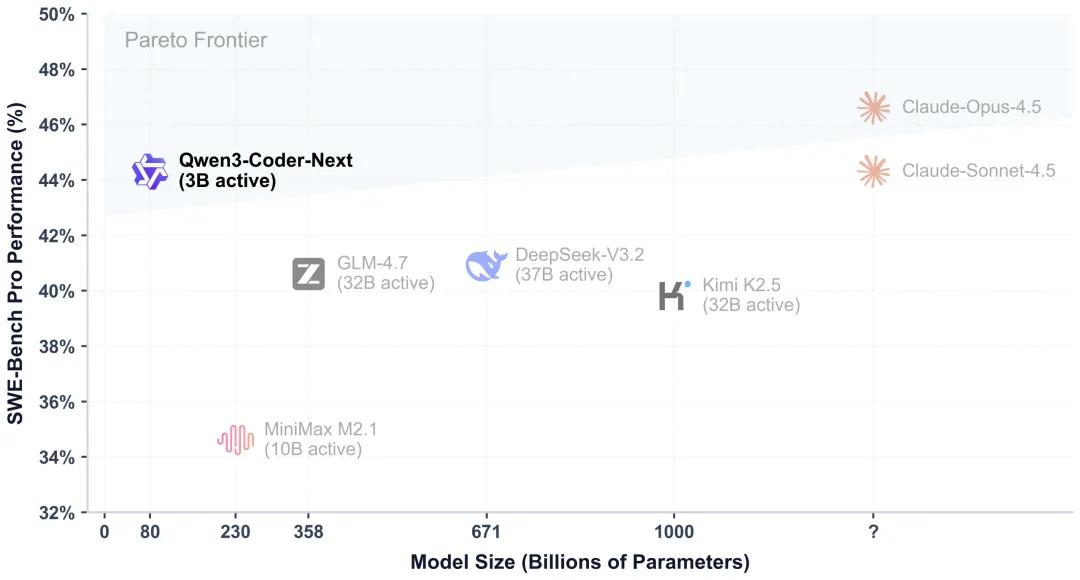
而,真正让 Qwen3-Coder-Next 脱颖而出的,是它在效率与性能之间找到了一个极佳的平衡点。数据显示,Qwen3-Coder-Next(3B 激活)的 SWE-Bench-Pro 表现可与激活参数量高 10×–20×的模型相当。
当你需要一个能够处理复杂代码任务的智能体时,不再需要为 30B、40B 甚至更高的推理成本买单。一台配备消费级显卡的开发者工作站,就能跑动一个能力足以匹敌大型模型的代码智能体。对于预算有限但对能力有要求的团队,这代表着部署成本的数量级下降。
如果你需要本地部署一个能力足够强的代码智能体,Qwen3-Coder-Next 是当前开源生态中效率与性能平衡得最好的选择之一。
参考资料:https://qwen.ai/blog?id=qwen3-coder-next
 豫公网安备41010702003375号
豫公网安备41010702003375号