
OpenAI发布Codex-Spark,「实时协作」才是AI编程的下一个战场?
![]() 前沿资讯
1770979183更新
前沿资讯
1770979183更新
![]() 39
39
OpenAI 发布了首款专为实时协作设计的编码模型 Codex-Spark,搭配 Cerebras 的超低延迟硬件,能够实现每秒超过 1000 个 token 的生成速度。
过去几年,AI Agent 的主流叙事是「自主执行」。无论是 Claude Code、Devin 还是 OpenAI 自己的 Codex,核心逻辑都是让模型独立完成一段较长周期的任务,包括修复 bug、生成项目架构、编写测试用例。在这个过程中,Agent 需要「伪装」成人类操作者,通过模拟鼠标点击、键盘输入、页面滚动等行为来与 Web 界面交互。
但这种「仿人操作」的路径存在几个结构性痛点。首先是状态同步的脆弱性:网页是动态渲染的,DOM 结构随时可能因为用户交互或后台数据加载而改变,Agent 基于某个时刻截图生成的 XPath 或 CSS 选择器,很可能在下一次执行时就已失效。其次是交互成本的浪费:让 Agent 完整「看」一个页面需要将整个渲染树序列化传输,这个过程的 token 消耗远大于纯文本理解,但为了保证操作准确性又不得不做。第三是反馈循环的断裂:传统 Agent 模式下,人类用户只能在任务完成后才能看到结果,中间过程对用户是完全黑箱的,用户无法在模型「跑偏」的早期阶段进行干预和纠正。
这些问题在「慢速推理」时代还能勉强容忍,毕竟用户已经习惯了等待。但当模型推理本身变得足够快,这些交互层面的低效就成为了最明显的瓶颈。
Codex-Spark 的发布,似乎揭示了一个被低估的趋势:AI 编码工具正在从「后台 Agent」模式转向「前台协作」模式。但这种转变的底层支撑不是模型本身,而是推理基础设施的延迟优化。
OpenAI 官方披露了几个关键数据:客户端与服务器之间的每次往返延迟降低了 80%,单个 token 的 overhead 减少了 30%,首 token 出现的时间(time-to-first-token)缩短了 50%。 但这些改进都是来自整个推理管线的重构,包括 WebSocket 持久连接的引入、Responses API 的内部优化、会话初始化流程的重写,以及与 Cerebras 定制硬件的深度整合。
这种基础设施层面的变化,正在催生一种新的交互范式。用户不再需要给 Agent 下一个完整的指令然后「放手等待」,而是可以在模型工作的过程中实时观察、随时打断、动态调整方向。
如果说,Codex-Spark 代表了推理层的范式转移,那么 WebMCP 这类协议层创新解决的是另一个根本问题:AI 如何可靠地操作 Web。
传统上,AI 操作 Web 页面依赖两种路径:一是视觉模型直接分析渲染后的页面截图,二是通过 CDP(Chrome DevTools Protocol)这类开发者协议注入脚本。前者 token 成本高且容易受页面样式变化影响,后者需要浏览器环境的持续运行,开销巨大。WebMCP 的核心思路,是将 Web 页面的交互从「模拟人类操作」转变为「直接调用底层能力」。 模型不再「假装」点击按钮,而是通过结构化的协议直接触发页面逻辑。
这与 Codex-Spark 的即时协作逻辑形成了互补。当推理延迟足够低时,模型可以频繁地向页面发送小粒度的查询和指令,而不是一次性生成一个完整的操作序列。
过去,我们设计 Web 接口时,唯一的消费者是人类用户;现在,AI Agent 正在成为第二类重要的消费者。那些依赖复杂前端交互逻辑的应用,可能需要为 AI 提供更加结构化、协议友好的接口层。
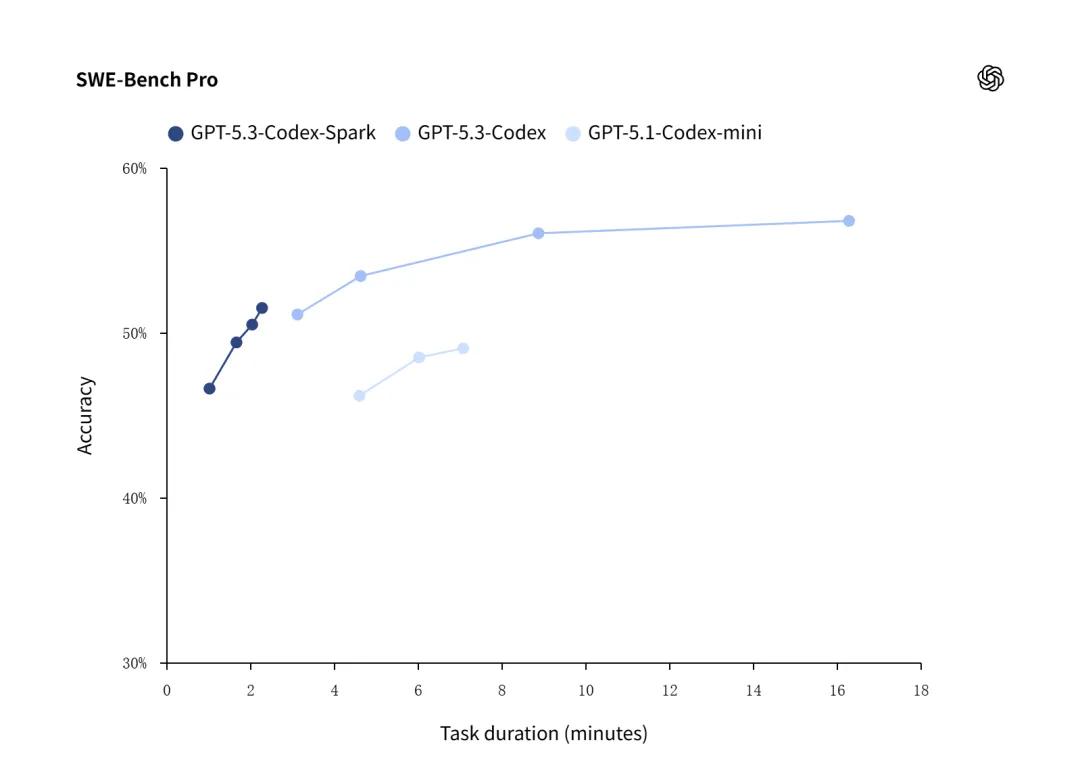
从 benchmark 数据来看,Codex-Spark 在 SWE-Bench Pro 和 Terminal-Bench 2.0 上的准确率略低于完整的 GPT-5.3-Codex,但完成时间只有后者的三分之一。
OpenAI 已经明确表示,未来会让这两种模式融合:Codex 可以让用户保持在紧凑的交互循环中,同时将耗时较长的任务委托给后台的子 Agent,或者将任务并行分发给多个模型以同时获取广度和速度。
从更宏观的视角看,Codex-Spark 标志着 AI 工具从「自动化」向「协作化」的转型。
过去的 Agent 强调自主决策和长周期执行,而未来的 Agent 可能会更多地扮演「智能协作者」的角色,它们不是替代人类工作,而是在人类工作的每一个环节提供即时、精准的辅助。
参考资料:https://openai.com/index/introducing-gpt-5-3-codex-spark/
 豫公网安备41010702003375号
豫公网安备41010702003375号