
Taalas发布全球最快AI推理硬件:17000 tokens/秒,延迟进入毫秒级
![]() 前沿资讯
1771668484更新
前沿资讯
1771668484更新
![]() 67
67
当全行业还在卷参数规模时,一家只有 24 人的小团队用 3000 万美元做出了一个反直觉的硬件:把大模型直接刻进硅芯片里。
Taalas 刚刚发布的 HC1 板卡,运行 Llama 3.1 8B 能达到 17000 tokens/秒,比 B200 快 10 倍,成本低 20 倍,功耗低 10 倍。不需要 HBM 显存,不需要液冷,就是一块朴素的专用芯片。

长期以来,AI 推理面临一个死循环:模型越强,延迟越高,成本越离谱。
代码助手"思考"几分钟,打断了程序员的 flow,Agent 应用需要毫秒级响应,但云端 GPU 集群根本扛不住。
Taalas 的答案是:别让 GPU 干它不擅长的事。
这家成立仅两年半的公司,刚刚发布了全球首个硬连线大模型推理平台 HC1。
HC1 硬连线了 Llama 3.1 8B 模型,也就是从芯片出厂那一刻起,这个模型就被永久"刻"进了芯片里。
在 Taalas 的实验室里,这块板卡正在全速运行,速度是:
17000 tokens/秒。
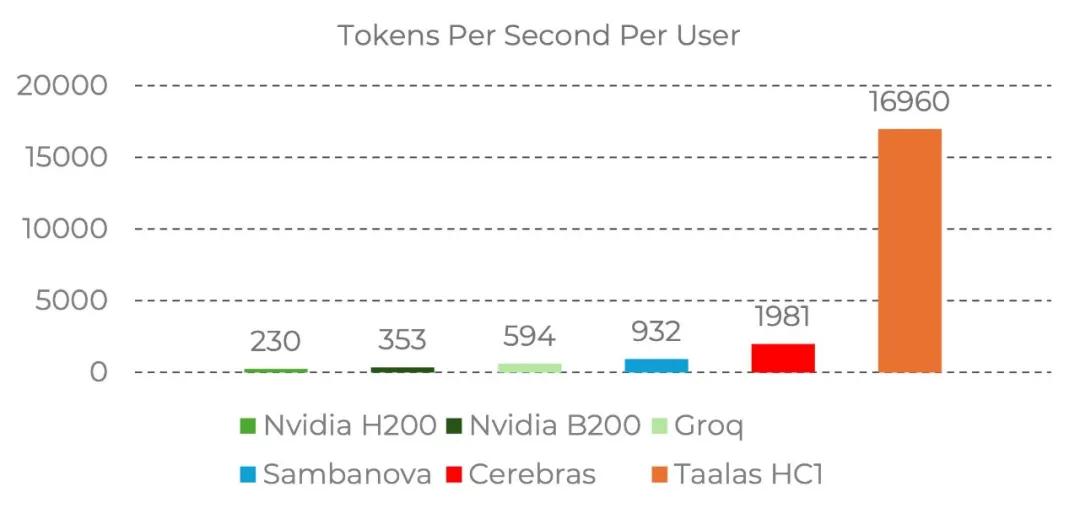
这是什么概念?H200 基准测试中,B200 的成绩是 1700 tokens/秒左右。Groq、Sambanova、Cerebras 这些专用推理芯片,普遍在 2000–5000 区间。
Taalas 的 HC1,快了将近 10 倍。
更恐怖的是成本和功耗。官方数据显示,这块板卡的构建成本仅为 B200 的 1/20,功耗是其 1/10。
没有 HBM,没有液冷,没有 advanced packaging,没有 3D 堆叠。 就是一块纯硅芯片,插上就能用。
不要通用GPU。不要可编程。要把模型直接刻进硅里,从出厂那一刻起,永远只能跑这一个模型。
这种极致定制化带来的,是传统架构永远追不上的效率。内存和计算单元的边界被打破,存储即计算,计算即存储。
Taalas 称之为 Total Specialization(完全专业化)。
"AI 推理是人类历史上计算需求最极端的工作负载,"Taalas 在官方博客中写道,"那它也理应得到最极端的优化——为每一个模型定制最优的硅。"
当然,也并非完全不可调。硬连线的 Llama 3.1 8B 仍支持可配置的上下文窗口长度,也支持通过 LoRA 进行微调。
这家公司,全员只有 24 人,创始成员之间的合作历史超过 20 年。
两年半时间里,他们总共花了 3000 万美元,但融资总额超过 2 亿刀。
有媒体评价道:
"在深度科技创业普遍像中世纪军队围城的时代,Taalas 是一次精准打击。"
路线图:推理 LLM 已来,下一步是推理+通用。
第一代 HC1 平台已经落地,首发模型是 Llama 3.1 8B。
第二代 HC2 平台将在今年冬季发布,密度更高,速度更快,支持 4-bit 浮点标准格式(第一代用的是 3-bit 自定义格式,模型质量略有折损)。
与此同时,基于 HC1 的中型推理 LLM 预计今年春季推出。
Taalas 的野心不止于"快"。
他们想解决的是AI 普及的根本障碍:延迟和成本。当推理进入毫秒级、几乎零成本,"AI 无处不在"才不再是数据中心的故事。
Taalas 在博客最后写道:
"颠覆性的技术一开始往往看起来很陌生。我们的首个产品已经交付,未来还会有更多。早期版本会有粗糙的地方,但我们相信行业需要理解并接受这套新的范式。"
首款产品 Llama 3.1 8B 已经在官网开放 demo 和 API,开发者可以直接申请体验。获取方式:
1.Chatbot Demo:(https://chatjimmy.ai/)可以直接体验Demo
2.Inference API服务:提供API接口给开发者调用
参考资料:https://taalas.com/the-path-to-ubiquitous-ai/
 豫公网安备41010702003375号
豫公网安备41010702003375号