
Anthropic推出Claude Code Security,防御AI攻击,可自动发现复杂逻辑漏洞
![]() 前沿资讯
1771753398更新
前沿资讯
1771753398更新
![]() 67
67
导读:当AI既能发现漏洞,也能被攻击者用来利用漏洞时,防御方必须更快。Anthropic发布了一项称为Claude Code Security的新能力,可以让AI像人类安全研究员一样理解和推理代码。在最新版本Claude Opus 4.6的测试中,Anthropic团队用它在生产级开源代码库中发现了超过500个存在多年的安全漏洞。这款工具目前以有限研究预览的形式向企业和团队客户开放,同时为开源维护者提供快速申请通道。
网络安全行业正面临一个转折点。
一方面,AI大模型在发现隐藏漏洞方面展现出前所未有的能力。另一方面,同样的能力也可能被攻击者利用。在这场攻防博弈中,Anthropic选择将AI安全能力交到防御者手中。
传统安全测试,主要依赖静态分析,即基于已知漏洞模式进行规则匹配。这种方法能够有效识别常见问题,如暴露的密码或过时的加密算法,但对于复杂的业务逻辑漏洞或访问控制缺陷往往无能为力。
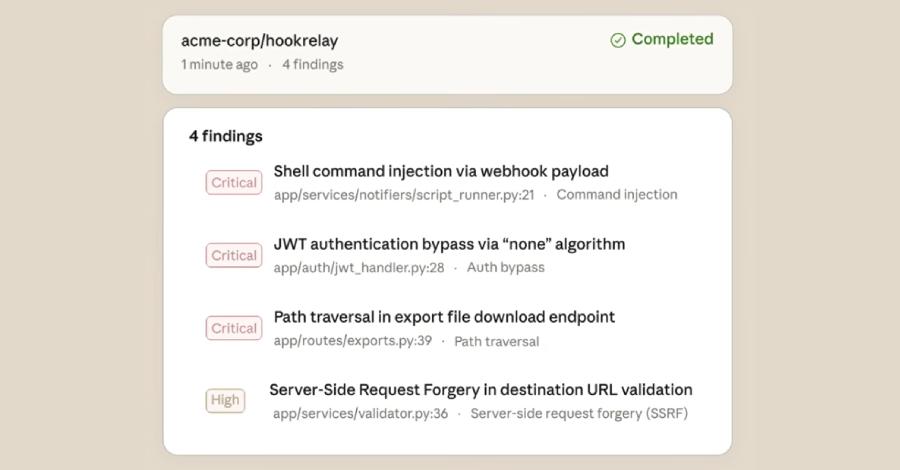
Claude Code Security采用了完全不同的技术路线。
它可以像人类安全研究员一样阅读和推理代码:理解组件之间的交互方式,跟踪数据在应用中的流动路径,从而捕获基于规则的扫描工具容易遗漏的复杂漏洞。
在问题呈现给分析师之前,Claude会反复审查每个结果,尝试证明或反证自己的发现,从而过滤掉大量误报。同时,系统会为每个发现分配严重性等级,帮助团队优先处理最关键的修复。
验证后的发现会显示在Claude Code Security仪表板中,团队可以审查问题、检查建议的补丁并批准修复方案。该系统还提供置信度评估,因为某些问题仅从源代码很难完全判断。
研究验证:已发现500+隐藏漏洞。使用本月发布的Claude Opus 4.6,Anthropic团队在生产级开源代码库中发现了超过500个安全漏洞,但这些问题在多年专家审查中一直未被发现。目前,Anthropic正在与相关维护者进行负责任的披露,并计划将这项安全工作扩展到更广泛的开源社区。
Claude Code Security现以有限研究预览的形式向Enterprise和Team客户提供,参与者将获得早期访问资格并直接与Anthropic团队合作优化工具能力。开源仓库的维护者可以申请免费快速访问。
Anthropic表示,预计在不久的将来,全球很大一部分代码都将由AI进行扫描,因为模型在寻找隐藏缺陷和安全问题方面的有效性已经得到验证。攻击者会利用AI更快地找到可利用的弱点,但行动迅速的防御者同样可以发现这些弱点并修复它们。
Claude Code Security是实现更安全代码库和行业更高安全基线目标的重要一步。
参考资料:https://www.anthropic.com/news/claude-code-security
 豫公网安备41010702003375号
豫公网安备41010702003375号