
阿里云开源三款Qwen3.5系列中等模型,性能超越旗舰,27B版本单GPU就能跑
![]() 前沿资讯
1772010216更新
前沿资讯
1772010216更新
![]() 65
65
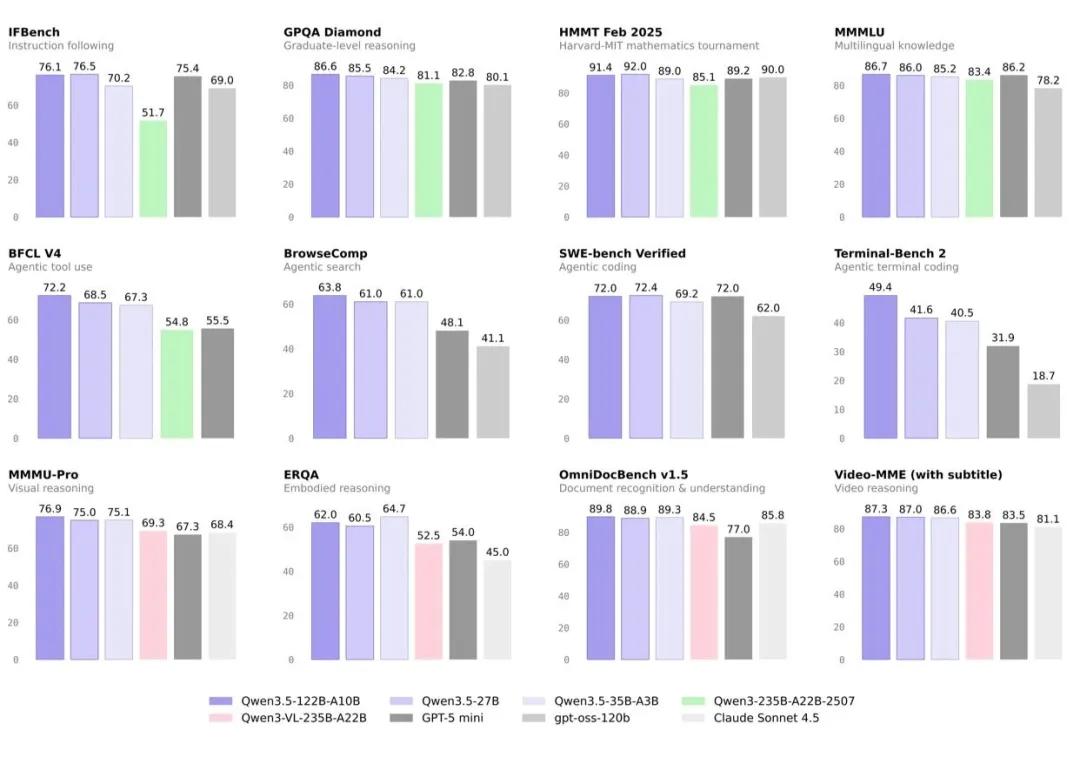
阿里云正式开源了千问3.5系列的三款中等规模模型:Qwen3.5-35B-A3B、Qwen3.5-122B-A10B和Qwen3.5-27B。
过去,AI行业有一个默认逻辑:模型越大,性能越好。想要更强的AI?堆参数、烧钱、扩大规模。
这让AI变成了只有巨头才能玩得起的游戏,普通人和企业只能"租用"大公司的API,看脸色行事。
但这次开源的三款模型打破了这种逻辑。更小的模型,却能打败更大的模型。
以Qwen3.5-35B-A3B为例,它的参数规模远小于前代旗舰Qwen3-235B-A22B,但在指令遵循、博士级别推理、数学推理、多语言知识等多个权威评测中全面超越后者。
"大力出奇迹"的时代可能正在过去,效率为王的时代正在到来。
小胜大,他们做了什么?
阿里云这次用了几招"精打细算":
混合注意力机制 + 高稀疏MoE架构,简单理解就是让模型学会"偷懒"。不需要动用全部神经元解决问题时,就只启用一小部分。既省算力,又不牺牲性能。
在训练数据上,开发团队使用了更大规模的文本和视觉混合Token,让模型"见过"更多东西,自然就更聪明。
结果是:总参数更小,激活参数更少,但实际表现反而更强。
三个版本,各有特点
Qwen3.5-35B-A3B:性能超越前代2350亿参数旗舰,适合对性能有较高要求的开发者。
Qwen3.5-122B-A10B:在复杂代理场景中表现优异,适合需要"AI Agent"能力的企业应用。
Qwen3.5-27B:首个密集模型,可以在单个GPU上运行,对本地部署极为友好。编程、工具调用能力超过GPT-5 mini,视觉理解能力超过Claude Sonnet 4.5。中小企业和个人开发者也能跑起来,不用再依赖云端API。
此外,阿里云还推出了Qwen3.5-Flash (生产版本的 Qwen3.5-35B-A3B)API服务,默认支持100万字超长上下文,每百万Token仅需0.2元,,成本低到令人惊讶。
参考资料:https://mp.weixin.qq.com/s/cBA0ssG3YvA1pL6KtIo1gA
 豫公网安备41010702003375号
豫公网安备41010702003375号