
通义千问Qwen3.7-Max发布:一个最接近"替你干活"的模型
![]() 前沿资讯
1779269339更新
前沿资讯
1779269339更新
![]() 1
1
今天,通义千问扔出了一个新模型,叫Qwen3.7-Max。
这次Qwen3.7-Max的定位,不是通用大模型,而是Agent专用基础模型:写代码、自动化办公、多步骤执行——这些才是它的主战场。
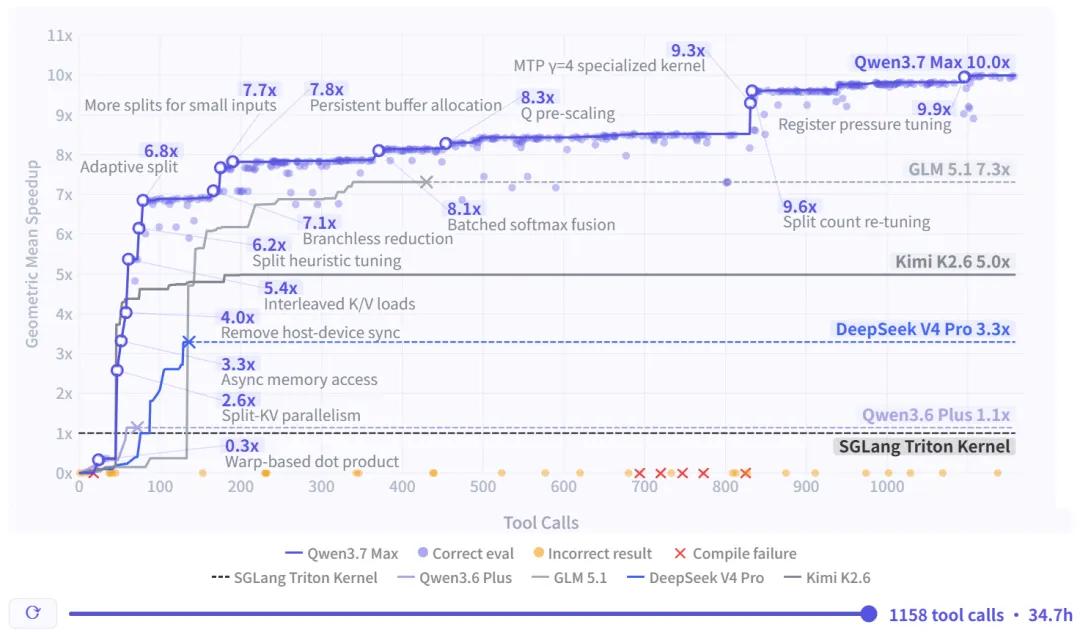
官方秀了一个特别离谱的肌肉。他们让Qwen3.7-Max去优化SGLang里面的Extend Attention内核,这是什么呢,你可以理解成LLM服务里面一个特别核心的计算模块。模型从零开始,只有一个任务描述和现有代码,没有任何文档,没有任何示例。
然后它自己诊断问题、自己写代码、自己编译、自己跑性能测试、自己迭代优化。
35个小时之后,10倍加速。
什么概念?作为对比,同样的任务:GLM 5.1做到了7.3倍,imi K2.6做到了5倍,DeepSeek V4 Pro做到了3.3倍,而上一代的Qwen3.6-Plus只做到了1.1倍——基本等于没优化。
说实话,这种长时程自主执行的能力,是之前所有模型都没有证明过的。能在1000步以上的任务里面保持上下文连贯性、保持推理质量,这需要的不仅是模型聪明,还需要整个训练体系的支持。
通义千问在这块做了什么?两个关键词。
一个是环境扩展。他们把Agent训练环境的质量和多样性做了大幅提升,实验结果很有意思:随着训练环境增加,模型性能提升的曲线是可预测的,而且在训练时完全没见过的环境下,性能提升同样成立。这说明什么?说明模型学到的不是针对特定框架的适配,而是通用的Agent能力。
另一个是解耦设计。他们把训练框架拆成了三个独立组件:任务、框架、验证器,可以自由组合。这带来了一个关键突破:模型在相同的任务上会遇到不同的框架配置,迫使它学习通用的解题策略,而不是某一种框架的"作弊方法"。
结果就是,Qwen3.7-Max在Claude Code、OpenClaw、Qwen Code和一堆自定义工具框架上的表现基本一致。你用什么框架调用它,它都能给你差不多的结果。
这太重要了。因为,现在市面上很多模型表现好,是针对特定框架做了优化,一旦换到别的环境就原形毕露。
除了内核优化,通义千问还秀了一些其他能力。
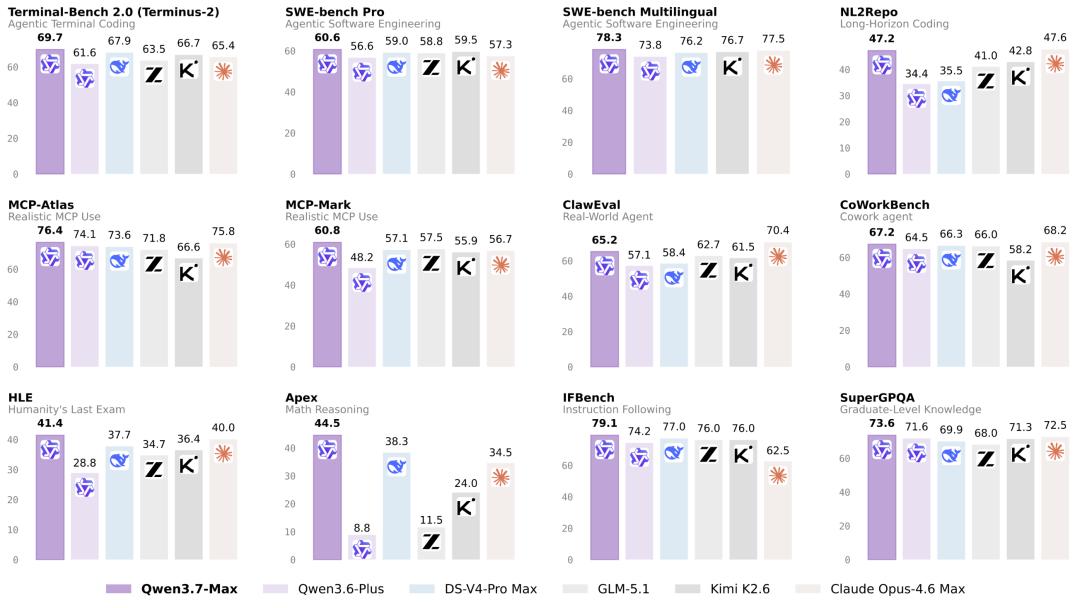
在软件工程Agent场景,模型实现了13条新启发式规则的自动添加,准确标记了1618个Reward Hacking案例。在模拟创业公司运营的YC-Bench测试里面,Qwen3.7-Max实现了208万美元总营收,是上一代模型的5.9倍。
甚至,它现在还能控制机器狗做物理世界导航了。感知、规划、记忆、决策,全流程自主完成。
我能感觉到,通义千问这次的核心目标是明确的:不是做一个更强的聊天模型,而是做一个更强的干活模型。
他们的思路很简单:你不是需要一个替你思考的AI,你需要的是一个替你干活的AI。
对了,这个新模型即将通过阿里云Model Studio提供API,支持Claude Code、OpenClaw、Qwen Code等主流Agent框架直接调用。
参考资料:https://qwen.ai/blog?id=qwen3.7
 豫公网安备41010702003375号
豫公网安备41010702003375号