
Google发布Gemma 4 12B:首款支持原生音频的中型多模态模型,可本地运行
![]() 前沿资讯
1780563675更新
前沿资讯
1780563675更新
![]() 0
0
传统的多模态AI模型,就像一个团队里有多位翻译——处理图片要找一个翻译,处理音频再找一位翻译,最后再把结果交给"主脑"。这种方式不仅慢,还很占内存。
Google最新发布的Gemma 4 12B,决定换一种方式:让一个"通才"直接搞定一切。
当地时间6月3日,Google DeepMind正式推出这款新模型。它是Google首款支持"听懂"音频的中型模型,体积小到能在普通笔记本电脑上运行——只需16GB显存。
Gemma 4 12B被定位为连接轻量级模型与高端模型的"桥梁"。它有五个尺寸可选,从手机级别的E2B到服务器级别的31B:
| 规格 | 定位 | 支持模态 | 上下文窗口 |
|---|---|---|---|
| E2B | 移动/边缘设备 | 文本、图像、音频 | 128K tokens |
| E4B | 移动/边缘设备 | 文本、图像、音频 | 128K tokens |
| 12B Unified | 消费级GPU/工作站 | 文本、图像、音频 | 256K tokens |
| 26B A4B MoE | 高端GPU/服务器 | 文本、图像 | 256K tokens |
| 31B Dense | 高端GPU/服务器 | 文本、图像 | 256K tokens |
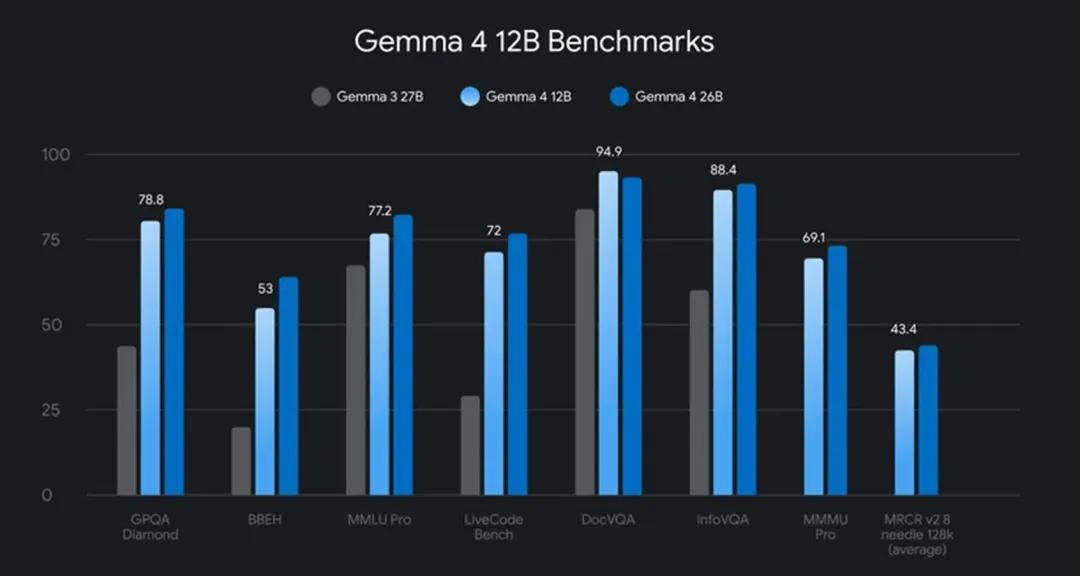
12B在多项基准测试中逼近更大的26B模型,但内存占用不到一半。
传统多模态模型处理图片时,要先让一个专门的"视觉编码器"把图片翻译成机器能懂的表示,再交给语言模型。这个翻译过程既费时间又费内存。
Gemma 4 12B的做法是:直接让语言模型自己看图、听音频。
具体怎么做到的?
- 看图:用一个极简的"投影层"替代复杂的视觉编码器。相当于把图片切成小块,直接映射成文字令牌能理解的格式,丢给语言模型处理。
- 听音频:直接把原始音频波形转换成文字令牌同款的"表示",不再经过任何"翻译"。这让整个模型可以在一次训练中完成多模态学习,不需要分别调教图片模块和音频模块。此外,模型采用"混合注意力"机制:处理局部信息时用滑动窗口,处理全局信息时用全局注意力。两种机制交替使用,兼顾速度与理解深度。处理长文本时,传统方法会把所有历史信息都塞进内存,就像一个人同时记住一整本书的所有内容,非常吃力。Google这次选择使用Proportional RoPE(p-RoPE)来优化长文本的内存占用。p-RoPE,可以让模型分清哪些是近期重点、哪些是长期背景,按需分配记忆资源,从而降低内存消耗。推理时,模型不是老老实实一个字一个字往外蹦,而是像"预写草稿"一样,同时想好几个可能的答案,再挑最好的那个输出。这样能显著加快生成速度。
Gemma 4 12B的核心能力包括:
- 逐步推理:遇到数学题或逻辑题,会先自己思考再回答
- 看懂图片:文档扫描、屏幕截图理解、图表解读、手写识别、多语言OCR
- 听懂语音:多语言语音转文字,以及语音翻译(E2B/E4B/12B专属)
- 处理视频:逐帧分析视频内容
- 调用工具:能按照指令调用外部工具或API,赋能自动化工作流
- 写代码:代码生成、补全、纠错预训练覆盖140种语言,开箱即用支持35种。
开发者怎么用?现已支持主流推理框架:Hugging Face Transformers、llama.cpp、MLX、SGLang、vLLM。用法和日常编程一样简单:
from transformers import AutoProcessor, AutoModelForMultimodalLMMODEL_ID = "google/gemma-4-12B-it"processor = AutoProcessor.from_pretrained(MODEL_ID)model = AutoModelForMultimodalLM.from_pretrained(MODEL_ID, dtype="auto", device_map="auto")messages = [{"role": "user", "content": "Write a short joke about saving RAM."}]inputs = processor.apply_chat_template(messages, tokenize=True, return_dict=True, return_tensors="pt", add_generation_prompt=True, enable_thinking=False).to(model.device)outputs = model.generate(**inputs, max_new_tokens=1024)想让模型"先思考再回答"?把enable_thinking设为True就行。
Google还推出了Gemma Skills技能库,专门帮助开发者快速构建智能体应用。
从手机到笔记本,从文本到图像、音频,Gemma 4 12B代表了一种趋势:不再追求"越大越好",而是让AI真正走进每个人的设备。当一个中型模型就能在本地完成多模态理解,或许"人人可用的AI"不再只是口号。
参考资料:
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12B/
 豫公网安备41010702003375号
豫公网安备41010702003375号